本文主要是介绍Kafka - 生产者初步学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Kafka - 生产者初步学习
一、kafka生产者组件
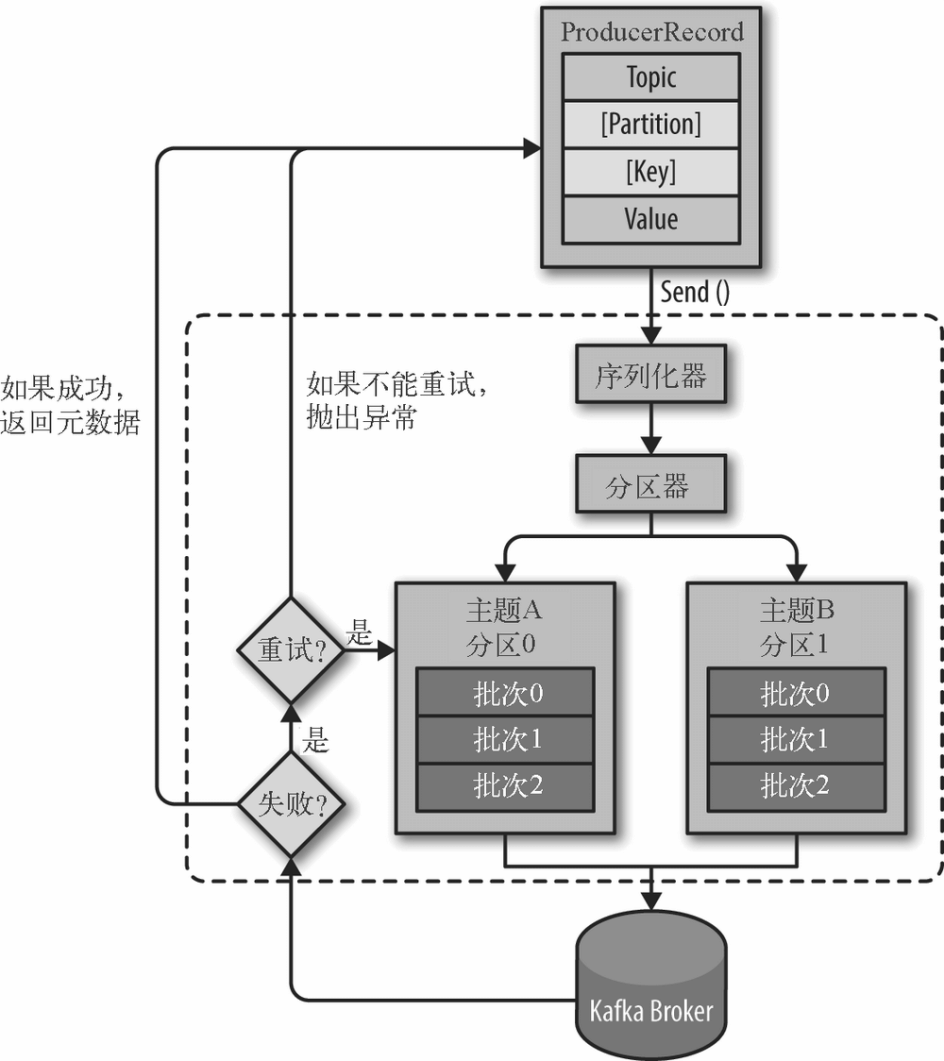
- 我们从创建一个 ProducerRecord 对象开始,ProducerRecord 对象需要包含目标主题和要发送的内容。我们还可以指定键或分区。在发送 ProducerRecord 对象时,生产者要先把键和值对象序列化成字节数组,这样它们才能够在网络上传输。
- 接下来,数据被传给分区器。如果之前在 ProducerRecord 对象里指定了分区,那么分区器就不会再做任何事情,直接把指定的分区返回。如果没有指定分区,那么分区器会根据 ProducerRecord 对象的键来选择一个分区。
- 选好分区以后,生产者就知道该往哪个主题和分区发送这条记录了。紧接着,这条记录被添加到一个记录批次里,这个批次里的所有消息会被发送到相同的主题和分区上。有一个独立的线程负责把这些记录批次发送到相应的 broker 上。
- 服务器在收到这些消息时会返回一个响应。如果消息成功写入 Kafka,就返回一个 RecordMetaData 对象,它包含了主题和分区信息,以及记录在分区里的偏移量。如果写入失败,则会返回一个错误。生产者在收到错误之后会尝试重新发送消息,几次之后如果还是失败,就返回错误信息。
二、使用Java API创建生产者
2.1 pom文件依赖
<properties><java.version>1.8</java.version><kafka.version>1.1.0</kafka.version>
</properties><dependencies><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>${kafka.version}</version></dependency>
</dependencies>目前kafka的最新稳定版本为1.1.0,因此本次也是用配套的客户端版本api。
2.2 连接必备属性
要往 Kafka 写入消息,首先要创建一个生产者对象,并设置一些属性。Kafka 生产者有 3 个必选的属性。
- bootstrap.servers:该属性指定了 broker 的地址清单,地址的格式为
host:port。清单中不需要包含所有的borker地址,生产者会从给定的 broker 里面寻找其他的 broker 信息。不过在实际使用的时候,建议提供至少两个 broker 信息。这是因为一旦其中一个机器宕机,生产者仍然能够连接在集群上。 - key.serializer:broker 希望接受到的信息都是字节数组,生产者接口允许使用参数化类型,因此可以把 Java 对象作为键和值发送给 broker。这样的代码具有良好的可读性。但是生产者本身并不清楚如何讲 Java 对象序列化为字节数组,因此我们需要设置这个属性为一个实现了
org.apache.kafka.common.serialization.Serializer接口的类,生产者就会使用这个类把键对象序列化为字节数组。 - value.serializer:与 key.serializer 一样,value.serializer 指定的类会将值进行序列化。如果键和值均为同一个数据类型,那么使用同一个序列化器。如果数据类型不同,则需要使用不同的序列化器。
注:
Kafka客户端目前只提供了如下的序列化器:
- ByteArraySerializer
- StringSerializer
- IntegerSerializer
当只使用常见的 Java 对象的时候无需自定义序列化器,但是当有其他需求的时候,就需要自己实现。同时要注意的是:就算你只打算发送 值(value), key.serializer 属性也是必须设置的。
一下是个代码段,这里只指定了必要的属性
import java.util.Properties;Properties kafkaProps = new Properties();
kafkaProps.put("bootstrap.servers", "master:9092");
kafkaProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
kafkaProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");三、kafka发送方式
接下来只需要实例化生产者对象,就可以发送消息。发送消息目前主要有三种方式:
- 发送并忘记(fire-and-forget)
- 同步发送
- 异步发送
3.1 发送并忘记(fire-and-forget)
我们把消息发送给服务器,但并不关心它是否正常到达。大多数情况下,消息会正常到达,因为 Kafka 是高可用的,而且生产者会自动尝试重发。不过,使用这种方式有时候也会丢失一些消息。
public static void main(String[] args) {Properties kafkaProps = new Properties();kafkaProps.put("bootstrap.servers", "master:9092");kafkaProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");kafkaProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");KafkaProducer producer = new KafkaProducer<String, String>(kafkaProps);ProducerRecord<String, String> record = new ProducerRecord<>("test", "Precision Products", "USA");try {producer.send(record);} catch (Exception e) {e.printStackTrace();}
}- 生产者的 send() 方法将 ProducerRecord 对象作为参数,所以我们要先创建一个 ProducerRecord 对象。
- 我们使用生产者的 send() 方法发送 ProducerRecord 对象。从生产者的架构图里可以看到,消息先是被放进缓冲区,然后使用单独的线程发送到服务器端。send() 方法会返回一个包含 RecordMetadata 的 Future 对象,不过因为我们会忽略返回值,所以无法知道消息是否发送成功。如果不关心发送结果,那么可以使用这种发送方式。比如,记录 Twitter 消息日志,或记录不太重要的应用程序日志。
- 我们可以忽略发送消息时可能发生的错误或在服务器端可能发生的错误,但在发送消息之前,生产者还是有可能发生其他的异常。这些异常有可能是 SerializationException(说明序列化消息失败)、BufferExhaustedException 或 TimeoutException(说明缓冲区已满),又或者是 InterruptException(说明发送线程被中断)。
3.2 同步发送
我们使用 send() 方法发送消息,它会返回一个 Future 对象,调用 get() 方法进行等待,就可以知道消息是否发送成功。
public static void main(String[] args) {Properties kafkaProps = new Properties();kafkaProps.put("bootstrap.servers", "master:9092");kafkaProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");kafkaProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");KafkaProducer producer = new KafkaProducer<String, String>(kafkaProps);ProducerRecord<String, String> record = new ProducerRecord<>("test", "Precision Products", "USA");try {producer.send(record).get();} catch (Exception e) {e.printStackTrace();}
}- 在这里,producer.send() 方法先返回一个 Future 对象,然后调用 Future 对象的 get() 方法等待 Kafka 响应。如果服务器返回错误,get() 方法会抛出异常。如果没有发生错误,我们会得到一个 RecordMetadata 对象,可以用它获取消息的偏移量。
- 如果在发送数据之前或者在发送过程中发生了任何错误,比如 broker 返回了一个不允许重发消息的异常或者已经超过了重发的次数,那么就会抛出异常。我们只是简单地把异常信息打印出来。
3.3 异步发送
我们调用 send() 方法,并指定一个回调函数,服务器在返回响应时调用该函数。
假设消息在应用程序和 Kafka 集群之间一个来回需要 10ms。如果在发送完每个消息后都等待回应,那么发送 100 个消息需要 1 秒。但如果只发送消息而不等待响应,那么发送 100 个消息所需要的时间会少很多。
大多数时候,我们并不需要等待响应——尽管 Kafka 会把目标主题、分区信息和消息的偏移量发送回来,但对于发送端的应用程序来说不是必需的。不过在遇到消息发送失败时,我们需要抛出异常、记录错误日志,或者把消息写入“错误消息”文件以便日后分析。
为了在异步发送消息的同时能够对异常情况进行处理,生产者提供了回调支持。下面是使用回调的一个例子。
public static void main(String[] args) {Properties kafkaProps = new Properties();kafkaProps.put("bootstrap.servers", "master:9092");kafkaProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");kafkaProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");KafkaProducer producer = new KafkaProducer<String, String>(kafkaProps);ProducerRecord<String, String> record = new ProducerRecord<>("test", "Precision Products", "USA");try {producer.send(record, new DemoProducerCallback());} catch (Exception e) {e.printStackTrace();}
}private static class DemoProducerCallback implements Callback {@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {if (exception != null) {exception.printStackTrace();}}
}- 为了使用回调,需要一个实现了 org.apache.kafka.clients.producer.Callback 接口的类,这个接口只有一个 onCompletion 方法。
- 如果 Kafka 返回一个错误,onCompletion 方法会抛出一个非空(non null)异常。这里我们只是简单地把它打印出来,但是在生产环境应该有更好的处理方式。
- 在发送消息时传进去一个回调对象。
3.4 注意
KafkaProducer 一般会发生两类错误。
- 其中一类是可重试错误,这类错误可以通过重发消息来解决。比如对于连接错误,可以通过再次建立连接来解决,“无主(no
leader)”错误则可以通过重新为分区选举首领来解决。KafkaProducer
可以被配置成自动重试,如果在多次重试后仍无法解决问题,应用程序会收到一个重试异常。 - 另一类错误无法通过重试解决,比如“消息太大”异常。对于这类错误,KafkaProducer 不会进行任何重试,直接抛出异常。
这篇关于Kafka - 生产者初步学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




