本文主要是介绍干货福利 | “新基建”时代,数据如何驱动企业数智化升级,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2020年由于新冠疫情的爆发,对各行各业都造成了一定的压力和损失,让许多企业注意到数字化转型的必要性。据调研数据显示,今年有45%的企业将“提高对数据的管理能力”作为企业数字化转型的目标,位列所有选项之首。
出于对数据治理的关注,企业也逐步提升了对数据存储、数据调用及数据分析的生产力工具和平台能力的要求,由此便诞生了“数据中台”这一数据产品新概念。
12月6日,中国计算机学会青年计算机科技论坛(简称CCF YOCSEF)在杭州举办了数据中台专题论坛,就数据中台的定义、概况、企业案例以及数据中台实施过程中的焦点问题进行了探讨,讨论氛围热烈。袋鼠云战略副总裁张旭受邀出席演讲,与会嘉宾还有滴滴高级技术专家张亮、之江实验室王梁昊、税友王伟等。

论坛上,袋鼠云战略副总裁张旭以《“新基建”时代,数据如何驱动企业数智化升级》为题做现场分享,全面介绍袋鼠云在多年数据中台实践过程中总结出的数据中台建设方法论。
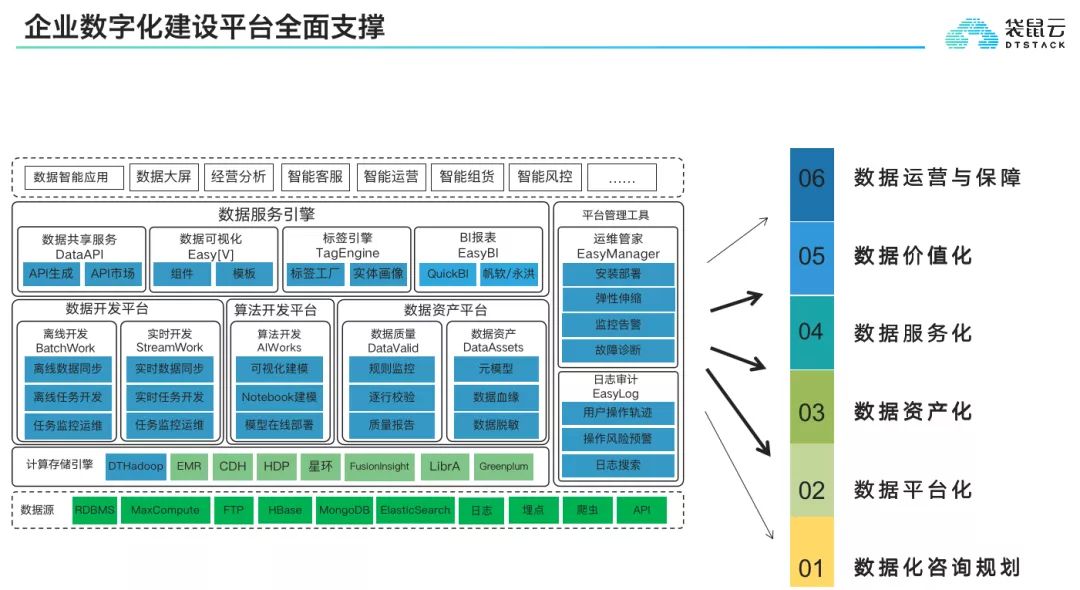
张旭认为,企业做数据中台需要让咨询先行,做好数据化的顶层设计和咨询规划,然后是数据平台化、数据资产化、数据服务化,一直到数据价值化,这些是一个企业数字化建设的主航道,最终实现数据对企业的全面赋能。最后企业在数字化进程中,一定要让数据化运营与保障贯穿始终,才能最大程度的保证企业数字化转型的成功!
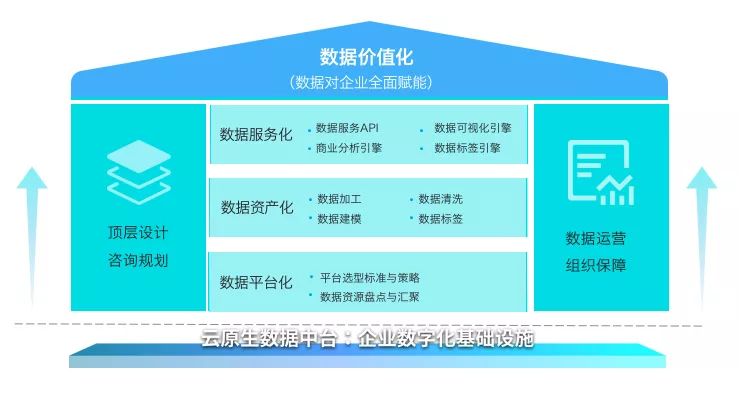
张旭表示,数据是一种力量,会帮助企业在当前的商业阶段快速成长,拉开竞争差异,在商业上业务上产生价值,企业目前最迫切的是数据化。这是目前的大环境和前提,在这个前提下讨论数据中台的定论。我们期待的数据中台能够将企业数据化支撑起来,能够为企业数据化提供一套科学合理的建设体系,能够让这个体系运转起来,逐步实现企业数据化进程,如果能达到这个定位,这就是企业想要的数据中台。
在之后的思辨讨论中,在场嘉宾就数据中台实施过程中的焦点问题进行了深度交流。在谈到数据中台投入大,产出不明显,如何客观的衡量数据中台的价值时,袋鼠云副总裁张旭用了一个巧妙的修路的比喻,生动地表达了中台的投入产出比。建中台就好比修路,如果没有好的柏油马路,汽车平均使用寿命是五年,平均时速是30公里/时。如果让某个车企去修路,可能会负担不起。只能从国家层面去组织修路,这时候收益就要从全社会去考量了。路修好后看所有车的使用年限可以到10年,车速可以到达60/时、80/时、100/时,整体的经济效益都翻倍了。
滴滴高级技术专家张亮表示需要回从运营的角度去考虑长期的投入,不同的类型的企业考量不同,如果数据运营给公司带来价值,就可以持续投入,没有的话就适可而止。之江实验室的王梁昊表示符合规模的企业上到中台战略是必要的,但仍需要解决轻量化处理中台数据的问题。
在思想火花碰撞的思辨讨论结束之后,现场观众就数据中台和云ERP定位,针对高校人才培养、企业人才需求、学生自身发展建设数据中台等方面提出问题,嘉宾就问题逐一解答。
干货福利
为了让未能亲临现场的朋友也能学习企业数字化的方法论,袋鼠云决定将现场演讲PPT公开,以供大家学习和交流。
欢迎扫码获得《“新基建”时代数据如何驱动企业数智化升级》演讲PPT~

这篇关于干货福利 | “新基建”时代,数据如何驱动企业数智化升级的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






