本文主要是介绍重复数据删除:固定和可变长度数据块,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.2 数据块级别相同
1.2.1 固定大小数据块
为了更细粒度的检测重复数据,可以将文件分割成固定大小的数据块,这就是基于固定大小数据块的重复数据检测。实现时,首先将存储系统中所有的文件按固定大小划分成数据块,计算每个数据块的hash函数值,将所有的hash函数值单独存储起来构成hash值库。当有新的数据需要存储时,同样按照这个固定的大小将其划分成数据块,用每块的hash函数值同hash值库中的逐一比较。如果发现新的数据块hash函数值已经存在于哈市值库中,说明这块数据已经在系统中存储过,无需再次存储,只要将指向这个hash函数值所代表的数据块的指针存入相应位置即可;如果新的数据块hash函数值不在hash值库中,则将其实际存储到系统中,并将新的hash函数值添加到库里。实现流程如下图所示。
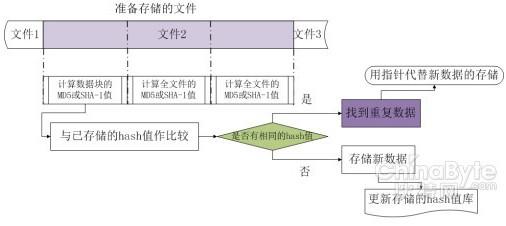
图 固定大小数据块检测
经典文献
u Venti: A new approach to archival storage
Quinlan S, Dorward S. In: Proc. of the 1st Usenix Conf. on File and Storage Technologies (FAST 2002). Berkeley: USENIX Association, 2002. 89–102.
几乎所有涉及dedupe的文章都提到了Venti系统。它是贝尔实验室设想的一款用于归档数据的网络存储系统原型。它和Plan 9操作系统绑定,所以不能用于诸如Windows,Linux之类系统的后端存储设备。Venti以固定大小数据块作为存储单位,并且计算每个数据块的SHA-1值作为块标识,通过比较块的hash值检测重复数据。
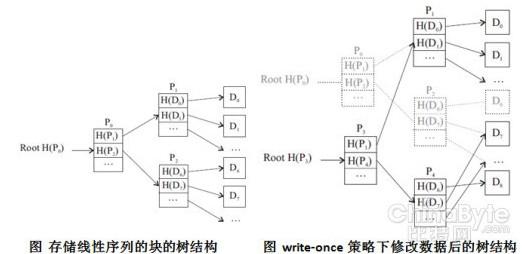
比较值得一提的是Venti的write-once策略。每个数据块占用唯一一个地址,多次写入相同的数据块地址相同,所以同一个数据块只存储一次。数据块不能删除,这也是永久或者备份存储的理想选择。另外,Venti还实现了快照功能。Venti 实现了一个针对大磁盘索引的cache,用以加速fingerprint 查找。由于fingerprint 当中没有位置信息,它的索引cache 不是很有效。尽管用8 个磁盘并行查找fingerprint,它的吞吐率只是局限于7MB/sec 以内。
1.2.2 可变大小数据块(基于文件内容的查找)
可变大小数据块的检测是基于文件内容的将文件分成大小不等的数据块,通常是利用Rabin指纹的方法计算出数据内容的指纹值。Rabin指纹是一种高效的指纹计算函数,利用hash函数的随机性,它对任意数据的计算结果表现出均匀分布。基于内容的数据块划分方法如下:
预先设定一对整数D,r(D>r)和一个滑动窗口的固定宽度l(实际中常用r=D-1)。对于一个序列S=S1,S2,……,Sn,当且仅当 窗口的边缘停在某一个k位置,也就是子序列W=S(k-l+1),S(k-l+2),……,Sk的指纹函数计算结果为h(W) mod D = r,则k位置有一个D-match。k位置也就是某个数据块的边界位置。
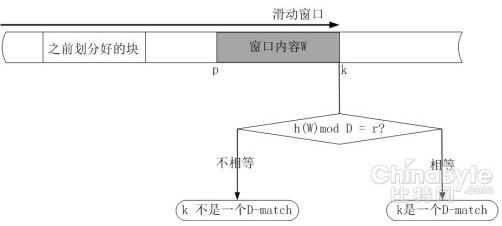
实际操作时,从文件头部开始,将固定大小(相互重叠)的滑动窗口中的数据作为Rabin 指纹的子序列,计算每个窗口位置的指纹。当满足指纹条件时,就将此时窗口所在位置的边界作为块的边界。重复这样一个过程,直到整个文件数据都被划分成数据块。接下来再用hash 函数(MD5 或者SHA) 计算出每个划分的数据块hash 值,并将它们管理起来存放在hash 函数值库中。有新来的文件时,首先按照上述方法划分成数据块,再将每个数据块的hash 值与已存储的数据块hash 值进行对比,如果检测到相同的hash 值,则不存储其代表的数据块,否则存储这个新数据块并更新hash 值库信息。如图所示:
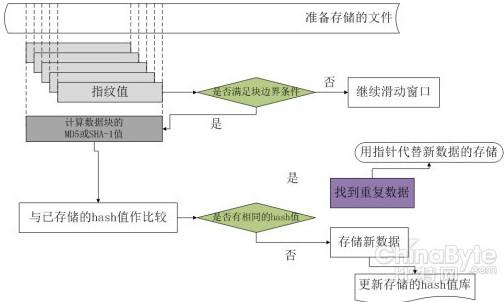
利用基于文件内容的划分方法,无论是插入还是删除一小部分字节,都只会影响到一到两个块,其余的块保持不变,所以对于只相差几个字节的数据块可以检测出更多的冗余。
经典文献
u A Framework for Analyzing and Improving Content-Based Chunking Algorithms
K.Eshghi and H. K. Tang. Technical Report HPL-2005-30(R.l), Hewlett Packard Laboraties, Palo Alto, 2005.
上面描述的数据块划分方法容易产生一些问题。由于hash函数的随机性,极端情况就是某文件始终找不到D-match,造成数据块过大(可能是一个 文件只有一个数据块);另一个极端情况就是每个字节都是D-match,这样数据块过小(只有1字节的长度)。针对这些可能出现的问题,本文提出了一些改 进算法,并且给出了如何评估这些算法好坏的数学公式。主要的改进算法如下:
1) 消除过小块
先按照原始算法标识块边界,再反复合并小于或等于某个限定值L的块,直到所有的块都大于L。实际应用中,一般是在chunk size到达限定值L之前忽略掉指纹。
2) 避免过大块
先用原始算法标识块边界,再将大于限定值T的块划分成n个等于T的块,最后那块可能小于等于T。缺点是对于大块,重复了固定分块的缺点:在块头部某个位置插入字节会造成整个块hash值的改变,其实块中大部分内容是保持不变的。
3) 双划分因子
用两个D的值:每次计算D和D'(例如D'=D/2)两套指针,若找到了D'-match,不马上划分为块边界,先记录下来。如果D- match在设定的Tmax之前有了,就用D-match,若到了Tmax还没有,就看之前有D'-match否,有就用D'-match划分,没有就用 Tmax。
4) 双边界,双划分因子
结合以上三种方法。
u A low-bandwidth network file system
Muthitacharoen A, Chen B, Maziéres D. In: Proc. of the 18th ACM Symp. on Operating System Principles (SOSP 2001). New York: ACM Press, 2001. 174−187.
LBFS是由MIT开发的一款网络文件系统,目标在于减少传输带宽,传输之前判断数据块是否已经在目标机器上存在,如果存在则不用发送数据块。另 外,LBFS用SHA-1值的前64为作块索引,有冲突的可能性。更新采用非同步方式,服务器端先应答客户端,在更新数据库。所以LBFS使用数据库管理 块的hash值,但并不依赖于数据库。服务器端与客户端共享相同的数据库索引号。LBFS的dedupe主要工作原理如下图所示:
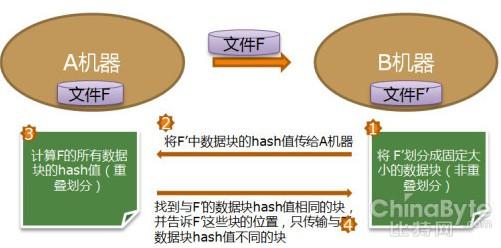
LBFS的显著优点是一次只需要考虑两个文件,方便快速;缺点是一个文件的重复数据可能分布在多个文件中,这样的方法能检测到的重复数据非常有限。 LBFS也同上面一样,为防止分块中的极端现象,设置了块大小的最大、最小值。在LBFS的测试数据中,滑动窗口大小事48bytes,平均块大小为 8KB,最小的块为2KB,最大块为64KB
这篇关于重复数据删除:固定和可变长度数据块的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



