本文主要是介绍推挽与开漏输出,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一般来说,微控制器的引脚都会有一个驱动电路,可以配置不同类型的数字和模拟电路接口。输出模式一般会有推挽与开漏输出。
推挽输出
推挽输出(Push-Pull Output),故名思意能输出两种电平,一种是推(拉电流,输出高电平),一种是挽(灌电流,输出低电平)。推挽输出可以使用一对开关来实现,在芯片中一般使用晶体管 / 场效应管。
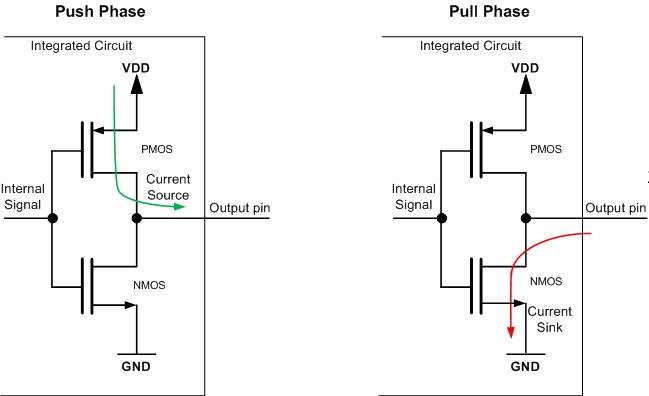
如图,分别是推和挽,详细过程是:
- 推:当输入信号为低电平时,P-MOS 导通,电流从 VDD 经过它到输出引脚。此时 N-MOS 截止。
- 挽:当输入信号为高电平时,N-MOS 导通,电流从输出引脚经过它到 GND。此时 P-MOS 截止。
推挽操作不允许在总线配置中把多个设备连接在一起,只能单向线路的接口(例如 SPI、UART),如果当两个推挽输出结构相连在一起,一个输出高电平,即上管导通,下管闭合;同时另一个输出低电平,即上管闭合,下管导通时。电流会从第一个引脚的 VCC 通过上管再经过第二个引脚的下管直接流向 GND。整个通路上电阻很小,会发生短路,进而可能损害端口。这也是为什么推挽输出不能实现线与的原因。
推挽输出因为能驱动高低电平,有更高的驱动能力,在数字信号中有更好的上升 / 下降沿(斜率较大),意味着更好的性能。
推挽输出一般也可以被配置为输入模式,通过关闭上下管,在线路上呈高阻抗状态。
开漏输出
开漏(OD,Open Drain Output)指打开 MOS 管的漏极,历史上也有开集输出(OC,Open Collect Output)
最原始的开漏输出只有两种状态:低、高阻。如果需要输出高电平,则需要外加上拉电阻。
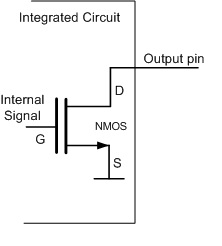
最原始的开漏输出是用一个 N-MOS 管实现的,当输入信号为高电平时,输出脚被拉低到地;但输入信号为低电平时,输出脚呈高阻浮空态。
开漏输出最主要的特性就是高电平没有驱动能力,需要借助外部上拉电阻才能真正输出高电平。
开漏输出常用在通信接口,有多个设备连接在同一线上(例如 I2C、One-Wire)。线路默认被上拉电阻拉至高电平,当任意设备有信号触发时,就会将整条线电平拉低。
用于开漏输出的上拉电阻必须平衡以下参数:
- 边沿斜率:线路本身有电容,上拉电阻与其耦合会构成低通滤波器,不同阻值会影响上升 / 下降沿的斜率。电阻越小,边沿越陡,信号传输效果越好。
- 功耗:如果上拉电阻阻值过小,当线被上拉时会导致过高的功耗
- 噪声:如果上拉电阻阻值过大,上拉会变弱,外部干扰噪声会更容易被线路拾取。
对比
| 推挽输出 | 开漏输出 | |
|---|---|---|
| 高电平驱动能力 | 高 | 看外部上拉电阻 |
| 低电平驱动能力 | 高 | 高 |
| 电平跳变速度 | 快 | 由外部上拉电阻决定,越小越快但功耗越大 |
| 线与 | 不支持 | 支持 |
| 电平转换 | 不支持 | 支持 |
- 推挽输出一般用于单向线通信;开漏通常用于双向线通信。
- 因为有上拉电阻,所以开漏输出功耗会相对高。
- 一般来说,推挽比开漏切换速度快。
这篇关于推挽与开漏输出的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





