本文主要是介绍力扣每日一题 6/13 反悔贪心算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 博客主页:誓则盟约
- 系列专栏:IT竞赛 专栏
- 关注博主,后期持续更新系列文章
- 如果有错误感谢请大家批评指出,及时修改
- 感谢大家点赞👍收藏⭐评论✍



2813.子序列最大优雅度【困难】
题目:
给你一个长度为 n 的二维整数数组 items 和一个整数 k 。
items[i] = [profiti, categoryi],其中 profiti 和 categoryi 分别表示第 i 个项目的利润和类别。
现定义 items 的 子序列 的 优雅度 可以用 total_profit + distinct_categories2 计算,其中 total_profit 是子序列中所有项目的利润总和,distinct_categories 是所选子序列所含的所有类别中不同类别的数量。
你的任务是从 items 所有长度为 k 的子序列中,找出 最大优雅度 。
用整数形式表示并返回 items 中所有长度恰好为 k 的子序列的最大优雅度。
注意:数组的子序列是经由原数组删除一些元素(可能不删除)而产生的新数组,且删除不改变其余元素相对顺序。
示例 1:
输入:items = [[3,2],[5,1],[10,1]], k = 2 输出:17 解释: 在这个例子中,我们需要选出长度为 2 的子序列。 其中一种方案是 items[0] = [3,2] 和 items[2] = [10,1] 。 子序列的总利润为 3 + 10 = 13 ,子序列包含 2 种不同类别 [2,1] 。 因此,优雅度为 13 + 22 = 17 ,可以证明 17 是可以获得的最大优雅度。
示例 2:
输入:items = [[3,1],[3,1],[2,2],[5,3]], k = 3 输出:19 解释: 在这个例子中,我们需要选出长度为 3 的子序列。 其中一种方案是 items[0] = [3,1] ,items[2] = [2,2] 和 items[3] = [5,3] 。 子序列的总利润为 3 + 2 + 5 = 10 ,子序列包含 3 种不同类别 [1, 2, 3] 。 因此,优雅度为 10 + 32 = 19 ,可以证明 19 是可以获得的最大优雅度。
示例 3:
输入:items = [[1,1],[2,1],[3,1]], k = 3 输出:7 解释: 在这个例子中,我们需要选出长度为 3 的子序列。 我们需要选中所有项目。 子序列的总利润为 1 + 2 + 3 = 6,子序列包含 1 种不同类别 [1] 。 因此,最大优雅度为 6 + 12 = 7 。
提示:
1 <= items.length == n <= 10**5items[i].length == 2items[i][0] == profitiitems[i][1] == categoryi1 <= profiti <= 10**91 <= categoryi <= n1 <= k <= n
分析问题:
解这道题主要还是要有一定的思维能力,对贪心算法有一定的知识储备。因为这道题考察的内容确实有点多,在它的标签里列出了 贪心,栈,数组,哈希表,排序,堆(优先队列);可见这题考的内容之丰富,不过不用慌,在Python中列表可以充当大部分的数据结构,把列表运用好可以解决大多数问题。
那么这道题的话思路如下:
先把items按照利润大小排序(假设从大到小排序),然后先取前k个,计算出当前的value值;
然后考虑k+1以及之后的元素,首先要明白k+1后面的元素的利润值都是低于之前的任何一个的,那么分类讨论:
- 如果k+1的种类存在于前k个元素中,那么把k+1加进去没有任何意义,种类重复利润还少,直接跳过即可。
- 如果k+1的种类不存在于前k个元素中,那么我们要选一个种类重复的且利润最小的元素出来和他交换,这时候利润虽然减小了但是种类+1了,记录此时的a_value值,于原value值相比,谁大取谁作为value。
按照这个思路,往下遍历,计算优雅度,取最大值即可。 不过要注意的是这里要记录种类重复的元素,以及将他们按照利润大小排序。这里可以直接用一个列表和一个集合实现,因为遍历的顺序是按照利润从大到小,所以加入到ls里面的元素的顺序一定是按照利润值从大到小的,直接将其翻转,先拿小的交换,这里需要一个指针,交换一次指针向前走一步,标记要被交换的元素。接下来看具体的代码实现:
代码实现:
class Solution:def findMaximumElegance(self, items: List[List[int]], k: int) -> int:items.sort(key= lambda items:items[0],reverse=True)ls=items[:k] # 先按利益大小取前k个最大的元素seen,ll,su=set(),[],0 # seen用来标记出现过的种类for i,j in ls:if j not in seen: seen.add(j)else: ll.append([i,j])su+=ivalue=su+len(seen)**2 # 计算当前最大优雅度if len(ll)==0: return valuell,re=ll[::-1],0 # re 指针 用来标记要和ll中的哪个元素比较for q in items[k:]:if q[1] not in seen and re<=len(ll)-1:key=q[0]-ll[re][0]seen.add(q[1])su+=keyre+=1a_va=su+(len(seen))**2if a_va>value:value=a_vareturn value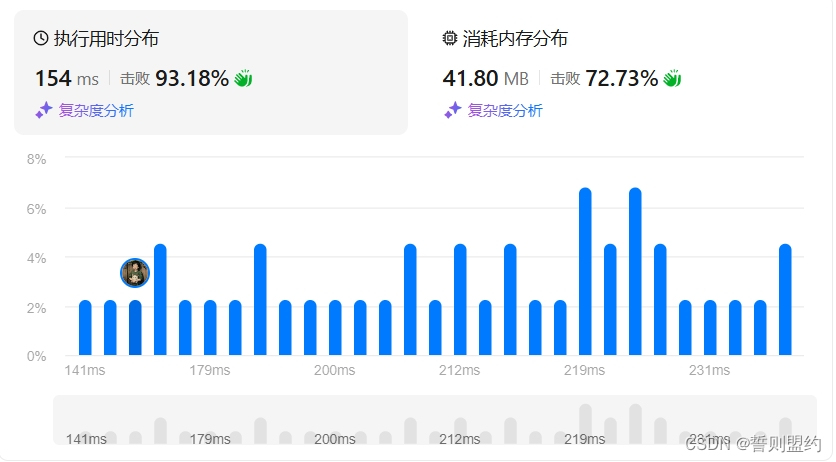
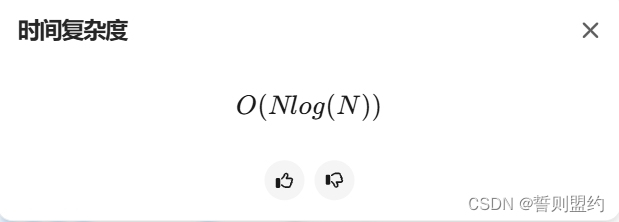

总结:
代码逐行解释:
-
函数定义
- 定义了名为
findMaximumElegance的函数,接受items列表和整数k作为参数。
- 定义了名为
-
初始化操作
- 对
items按照第一项(利益大小)进行降序排序。 - 取出前
k个元素存储在ls列表中。 - 创建空集合
seen用于标记出现过的种类。 - 创建空列表
ll用于存储重复种类的元素。 - 初始化变量
su为 0,用于累计利益总和。
- 对
-
计算初始优雅度
- 遍历
ls中的每个元素[i, j],如果j不在seen中,将其添加到seen中;否则,将该元素添加到ll中。 - 累加
ls中元素的利益到su。 - 计算初始优雅度
value为su + len(seen) ** 2。
- 遍历
-
处理剩余元素以优化优雅度
- 如果
ll不为空,将其反转。 - 遍历
items中k之后的元素q。 - 如果
q的种类不在seen中且re指针未超出ll的范围,计算用q替换ll[re]带来的利益变化key。 - 更新
seen、su,计算新的优雅度a_va。 - 如果
a_va大于当前的value,更新value。
- 如果
-
返回结果
- 函数最终返回计算得到的最大优雅度
value。
- 函数最终返回计算得到的最大优雅度
考查内容:
- 排序算法的应用:通过对
items列表按照特定规则(第一项的利益大小)进行排序,为后续的选择操作奠定基础。 - 数据结构的运用:使用集合
seen来快速判断元素的种类是否已经出现,利用列表ll存储重复种类的元素。 - 贪心算法的思想:先选择前
k个利益最大的元素,然后通过逐步替换来尝试优化结果,体现了贪心选择局部最优以期望达到全局最优的思路。 - 逻辑推理和计算能力:在计算优雅度、判断是否替换元素以及更新相关变量时,需要准确的逻辑推理和计算。
学到的内容:
- 熟练掌握排序函数的使用,能够根据具体需求对数据进行排序。
- 学会运用合适的数据结构来提高算法的效率和便捷性,例如集合的快速查找和去重特性。
- 深入理解贪心算法的策略,以及如何在特定问题中应用贪心思想来解决优化问题。
- 提升了对复杂逻辑的分析和处理能力,包括条件判断、变量更新和结果优化。
- 培养了通过逐步推导和计算来求解最优解的思维方式,同时也学会了如何在算法中有效地管理和利用数据。
To sum up: 这道题的算法有另一个好听的名字叫 反悔贪心,难度还是在线的,多思考,多理解。

“江流天地外,山色有无中。”——王维
这篇关于力扣每日一题 6/13 反悔贪心算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









