本文主要是介绍Intel8086处理器-处理数据的方式/寻址方式/局部性原理/位运算/进制转换,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在计算机中,cpu将一切硬件,都看成内存,各种硬件在CPU的眼中都是下面这样子的
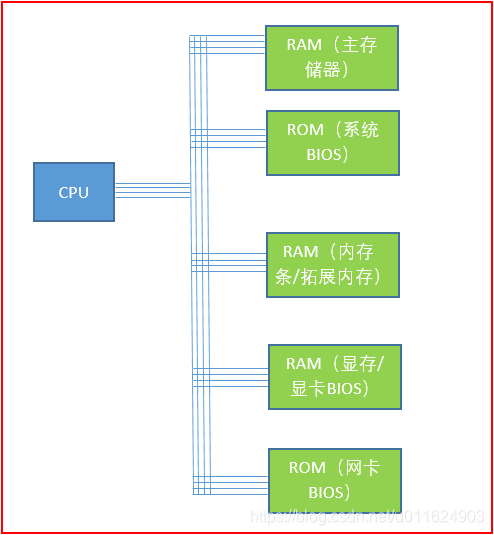
CPU对硬件的操作,其实就是和这些硬件的内存或者BIOS进行交互,CPU能做且只能做三件事
1.将某个地址中存储的字节转移到另一个地址处
2.将两个地址处的内容相加,并将结果存入某个地址
3.判断某地址处的字节是否为0
下面是8086CPU对内存的操作大致流程

日记:上图中可以看出是先取代码,IP自增,然后执行代码,而不是先执行代码,再IP自增,我个人认为此处应该与CPU的指令流水线实现有关,如果先执行,再IP自增,则指令流水线意义不大,此处纯属个人猜测
上图中涉及到8086段寄存器的概念,至于为什么会有段寄存器的存在可以参考这里
同时我们根据上图可以知道指令缓冲器是用来做什么的,如果CPU真的是一条一条的从内存中获取指令,那么效率实在是有些低了,正因为如此,CPU在指令缓冲器的位置又将其分成了一二三级缓存,在此,先要理解下面两个概念:局部性原理和缓存命中率
局部性原理
人们总是基于现在的情况,来推测未来的情况,比如,最近十分钟之内在下雨,那么我可以推测,未来一分钟之内还会下雨,毕竟未来一分钟之内下雨的概率比不下雨的概率要大很多,而缓存也同样是基于这个原理,缓存总是趋于最近使用过的数据或者指令,基于这个原理,所以,数据的分布地址不是随机的,而是聚集到一起的,这个原理,被称为局部性原理,局部性原理具体分为
空间局部性:接下来要访问的数据,和之前访问的数据,在内存地址中是临近的,所以当缓存数据A时,那么和A物理位置临近的数据,也会缓存起来
时间局部性:如果一个数据被访问,那么它接下来的一段时间之内,很有可能还会被访问,所以获取数据A时,会把A缓存起来
注意,局部性原理,并不是一个真正的原理,它是经验性主义,并且从统计学的角度来看,虽然不能百分之百为真,但是的确很有效
缓存命中率
既然了解了局部性原理,这个概念也就好解释了,因为局部性原理并不能保证缓存的数据一定有用,也并不能保证接下来要用的数据一定被缓存起来,但是,现代计算机依据统计学以及大量的样本实验,局部性原理的缓存命中率能高达0.9(百分之90,但是通常不说百分之多少,都用小数表示)
根据局部性原理和缓存命中率,就可以设计出缓存,绝大多数的缓存都是如下设计的:当从内存中获取一条指令的时候,顺便获取这条指令临近的一些指令,缓存起来
CPU可以处理下面三处过来的数据
1.CPU内部
直接从寄存器中获取数据,例如下面的汇编代码都是正确的
mov ax,cx
mov ax,dx
mov ax,ds
2.内存中
在汇编中,使用中括号包含寄存器的方式来描述从内存中获取数据,且只有4种寄存器可以用在[]中,它们分别是bx,bp,si,di,例如下面的汇编代码是正确的
mov ax,[bx]
mov ax,[bx+si]
mov ax,[bx+di]
mov ax,[bp]
mov ax,[bp+si]
mov ax,[bp+di]
下面的汇编代码是错误的
mov ax,[cx]
mov ax,[dx]
mov ax,[ds]
3.端口中
从端口中获取数据,本质上也是从内存中获取数据,只不过这个内存,不是我们常见的内存条,而是各个硬件的缓存中,例如网卡的缓存,键盘的缓存
CPU要读取多长的数据
在计算机中作为一个整体来处理或运算的一组二进制数码,称为一个字。英文是word。字是二进制数的基本单位,是数据总线宽度。比如在32位机器上,是按照4个字节作为一个整体来处理,所以32系统一个字的大小为4字节,同理,64位系统是按照8字节作为一个整体,所以64位系统中一个字的大小为8字节
汇编代码mov ax,[0]表示从ds+0的物理地址处读取数据,但是读取多长的数据呢?cpu是有一套自己的规范的,规则如下
1.通过寄存器位数决定操作多长的数据
mov ax,1;因为ax是16位寄存器,所以后面的数字1是2个字节
mov al,1;因为al是8位寄存器,所以后面的数字1是1个字节
mov eax,1;在32位cpu中,eax是32位寄存器,所以后面的数字1是4字节
2.通过指定位数决定是操作多少数据
使用X ptr参数指定
// 数字1是2个字节的数字1
mov word ptr ds:[0],1
// 数字1是1个字节的数字1
inc byte ptr [bx]
// 数字1是4个字节的数字1
inc dword ptr [ebx]
3.对栈的操作一定是字操作
具体字是多长取决于cpu位数
// 32位cpu压4个字节入栈,16位压1个字节入栈
push ax
// 32位cpu压4个字节入栈,16位不存在eax
push eax
寻址方式
“寻址”这两个字指的是给定一个物理地址,然后去内存中寻找该物理地址中的数据
段地址和偏移地址组合,叫做逻辑地址,偏移地址又叫做有效地址,在汇编代码中,给出有效地址的方式,叫做寻址方式,不同的写法,表示了不同的寻址方式,现在我用idata表示一个立即数,也可以说idata是一个常量
直接寻址
寻址方式:[idata]
示例:
mov ax,[66]
寄存器间接寻址
寻址方式:[bx]或者[bp]或者[si]或者[di]
示例:
mov ax,[bx]
mov ax,[bp]
mov ax,[si]
mov ax,[di]
寄存器相对寻址
寻址方式:[bx+idata]或者[bp+idata]或者[si+idata]或者[di+idata]
示例:
mov ax,[bx+123]
mov ax,[bp+234]
mov ax,[si+11H]
mov ax,[di+5638]
基址变址寻址
寻址方式:[bx+si]或者[bx+di]或者[bp+si]或者[bp+di],此处可参考通用寄存器(7)BP会更好记忆
示例:
mov ax,[bx+si]
mov ax,[bx+di]
mov ax,[bp+si]
mov ax,[bp+di]
相对基址变址寻址
寻址方式:[bx+si+idata]或者[bx+di+idata]或者[bp+si+idata]或者[bp+di+idata],就是在基址变址寻址的方式上加上了立即数(idata)
示例:
mov ax,[bx+si+0123H]
mov ax,[bx+di+89AB]
mov ax,[bp+si+89CC]]
mov ax,[bp+di+666H]
进制的概念
进制转换
由于10进制转换成16进制或者转8进制很复杂,所以通常情况都先将10进制转换成2进制,在从2进制转换成16或者8
例如:把二进制数101111转换成八进制数和十六进制数
二进制数转换成八进制数的方法是:整数部分从小数点向左数,每三位二进制数码为一组,最后不足三位补0,读出三位二进制数对应的十进制数值,就是整数部分转换的八进制数;小数部分从小数点向右数,也是每三位二进制数码为一组,最后不足三位补0,读出三位二进制数对应的十进制数值,就是小数部分转换的八进制小数的数值。即:2进制101111=8进制57。下面是分解步骤
1.因为2的3次方是8,所以每3位分解101111,于是变成了【101,111】
2.101对应的8进制是5,111对应的8进制是7,所以等于57
同理,2进制101111转换16进制
1.因为2的4次方是16,所以每4位分解101111,于是变成了【0010,1111】
2.0010对应的16进制是2,1111对应的16进制是15,所以等于2F
在C++中的表示
std::cout << 10 << std::endl; //打印10
std::cout << 0b10 << std::endl;//0b开头表示二进制,打印出2
std::cout << 010 << std::endl;//0开头表示8进制
std::cout << 0x10 << std::endl;//0x开头表示16进制
负数的补码:
补码是负数在内存中的表示,比方说-9这个数,会将-9的补码存在内存中,因为补码的存在,所以cpu就可以把减法当成加法来处理,这样cpu就不需要设计两套电路(一个加法电路,一个减法电路),这是cpu使用补码的唯一原因,下面是对负9取其补码
(1)-9的绝对值是9
(2)9的二进制是:0000 1001
(3)对9的二进制按位取反:1111 0110
(4)对上述的值加1:1111 0111
结果:所以-9的补码就是:1111 0111
现有10-9=1这个计算,则用上面的补码表达就是
| 10 | -9 | 1 |
|---|---|---|
| 0000 1010 | +1111 0111 | =0000 0001 |
NOTE: 可以根据首位是不是0,也就是说char类型是不是<0来判断该字符是不是ASCII字符,因为ASCII只使用了后7位,最高位没用
左移/右移
逻辑右移:补0
算数右移:补符号位,如果符号位是1,则补1,符号位是0,则补0
左移:左移不区分逻辑还是算数,也不区分正负数,右侧补0
注:多数C++编译器会采用算数右移
按位与:参与运算的双方都为1,结果为1,否则结果为0,该操作可以实现下面功能
1.清0,如果将一个数清0,则可以直接与0做与运算,下面是清0的java代码
int a = 3;a &= 0;System.out.println(a);
2.可以取出指定数中的某些位,下面该操作的java代码
// 十进制666对应的二进制位:10 1001 1010
int a = 666;
// 取右侧4位,那么就与1111
a &= 0xF;
System.out.println(a);
// 取右侧1位,那么就与0001
a &= 0x1;
System.out.println(a);
// 取右侧5位,那么就与1 1111
a &= 0x1F;
System.out.println(a);
// 取从右侧开始数第3位,那么就与0100
a &= 0x4;
System.out.println(a);
按位异或:参与运算的两个位不相同,结果为1,若相同,结果为0
1^1==0;
0^0==0;
1^0==1;
异或操作具有以下特性
1.如果一个bit位与0进行异或,则该bit位将不变
2.如果一个bit位与1进行异或,0变1,1变0,也就是所谓的翻转
// 十进制666对应的二进制位:10 1001 1010
int a = 666;
// 异或1111
int b=0xF;
// c为661,对应的二进制是:10 1001 0101
int c=a^b;
3.两个变量对调
int a = 3;
int b = 5;
a = a ^ b;
b = a ^ b;
a = a ^ b;
System.out.println(a);
System.out.println(b);
这篇关于Intel8086处理器-处理数据的方式/寻址方式/局部性原理/位运算/进制转换的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





