本文主要是介绍voc数据集的充分利用——将图片和xml按类别保存在不同文件夹、将目标剪裁后按类别保存在不同文件夹,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:
在做深度学习的时候,经常需要收集样本,有些样本我们可以从开源数据库中提取,省去自己标注的麻烦,下面介绍几种提取的方法,根据自己需要拿去用。
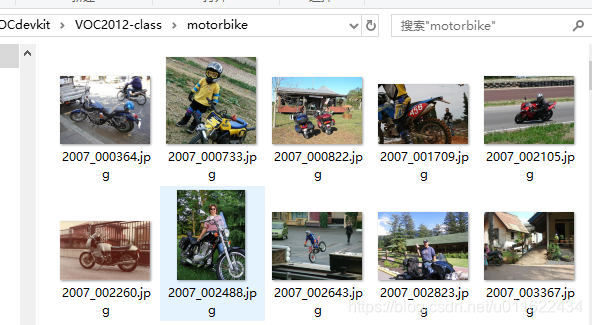
1. 将图片按类别保存在不同文件夹,文件名不变。
执行完得到如下结果,只是对图片进行的分类,没有对xml进行分类。
对xml和图片都进行分类的代码参考本博客第3部分介绍。

voc_class-pic.py
import xml.dom.minidom
import os
import cv2################
FindPath = './VOC2012/Annotations/'
FileNames = os.listdir(FindPath)
pic_path = './VOC2012/JPEGImages/'
save_path_pic = './VOC2012-class/'
Resnet_height = 224
Rsenet_width = 224
start_name = 0
one_location_list = []
all_location_list = []
all_name_list = []
def get_all_location(now_box_root):for box_i in range(len(now_box_root)):location_xmin = now_box[box_i].getElementsByTagName('xmin')location_xmax = now_box[box_i].getElementsByTagName('xmax')location_ymin = now_box[box_i].getElementsByTagName('ymin')location_ymax = now_box[box_i].getElementsByTagName('ymax')location_xmin = location_xmin[0].firstChild.datalocation_xmax = location_xmax[0].firstChild.datalocation_ymin = location_ymin[0].firstChild.datalocation_ymax = location_ymax[0].firstChild.datareturn location_xmin, location_xmax , location_ymin , location_ymaxdef get_path(target_save_path):target_path = save_path_pic + target_save_path + '/'if os.path.exists(target_path) is False:os.makedirs(target_path)print('target_path = ',target_path)return target_pathdef crop_pic(start_name , picName , img_name ,location_size):img = cv2.imread(pic_path + picName + '.jpg')for img_i in range(len(img_name)):print('1 = ',location_size[img_i][0] ,' ',location_size[img_i][1] ,' ' ,location_size[img_i][2], ' ',location_size[img_i][3])image = img[ location_size[img_i][2]:location_size[img_i][3] , location_size[img_i][0]:location_size[img_i][1] ]width = location_size[img_i][1] - location_size[img_i][0]height = location_size[img_i][3] - location_size[img_i][2]target_width = (Resnet_height * width) // height#image = cv2.resize(image , (Resnet_height , Resnet_height) ,interpolation=cv2.INTER_CUBIC) #resizecrop_path = get_path(img_name[img_i])print('crop_path = ',crop_path)###### save crop pic#cv2.imwrite(crop_path + picName + '.jpg',image)###### save original piccv2.imwrite(crop_path + picName + '.jpg',img)for file_name in FileNames:dom = xml.dom.minidom.parse(os.path.join(FindPath, file_name))# print('filename = ',file_name)get_file_to_pic_name,err_xml = os.path.splitext(file_name)print('---------------------------')print('before = ',get_file_to_pic_name)root = dom.documentElementobject_root = root.getElementsByTagName('object')length = len(object_root)for root_i in range(length):now_name = object_root[root_i].getElementsByTagName('name')now_box = object_root[root_i].getElementsByTagName('bndbox')for get_name_nums in range(len(now_name)):####### get nameget_object_name = now_name[get_name_nums].firstChild.dataprint('get_name = ',get_object_name)all_name_list.append(get_object_name)####### get locationget_xmin , get_xmax , get_ymin , get_ymax = get_all_location(now_box)one_location_list.append(int(get_xmin))one_location_list.append(int(get_xmax))one_location_list.append(int(get_ymin))one_location_list.append(int(get_ymax))all_location_list.append(one_location_list)one_location_list = []# print('all = ',all_location_list)if len(all_name_list) != len(all_location_list):print('Error file is ',file_name,',shut down!')break# print('len = ',len(all_name_list),' ',len(all_location_list))############ crop piccrop_pic(start_name , get_file_to_pic_name,all_name_list , all_location_list)start_name += 1all_name_list=[]all_location_list=[]
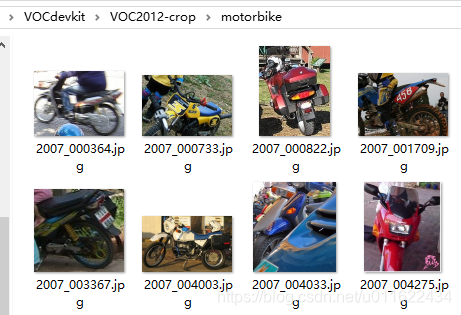
2. 将图片剪裁后,按类别保存在不同的文件夹
执行完之后的结果如下,图片是剪裁后的:

代码和上面那段就一句不同,放在这里直接copy去用。
voc_crop.py
import xml.dom.minidom
import os
import cv2################
FindPath = './VOC2012/Annotations/'
FileNames = os.listdir(FindPath)
pic_path = './VOC2012/JPEGImages/'
save_path_pic = './VOC2012-crop/'
Resnet_height = 224
Rsenet_width = 224
start_name = 0
one_location_list = []
all_location_list = []
all_name_list = []
def get_all_location(now_box_root):for box_i in range(len(now_box_root)):location_xmin = now_box[box_i].getElementsByTagName('xmin')location_xmax = now_box[box_i].getElementsByTagName('xmax')location_ymin = now_box[box_i].getElementsByTagName('ymin')location_ymax = now_box[box_i].getElementsByTagName('ymax')location_xmin = location_xmin[0].firstChild.datalocation_xmax = location_xmax[0].firstChild.datalocation_ymin = location_ymin[0].firstChild.datalocation_ymax = location_ymax[0].firstChild.datareturn location_xmin, location_xmax , location_ymin , location_ymaxdef get_path(target_save_path):target_path = save_path_pic + target_save_path + '/'if os.path.exists(target_path) is False:os.makedirs(target_path)print('target_path = ',target_path)return target_pathdef crop_pic(start_name , picName , img_name ,location_size):img = cv2.imread(pic_path + picName + '.jpg')for img_i in range(len(img_name)):print('1 = ',location_size[img_i][0] ,' ',location_size[img_i][1] ,' ' ,location_size[img_i][2], ' ',location_size[img_i][3])image = img[ location_size[img_i][2]:location_size[img_i][3] , location_size[img_i][0]:location_size[img_i][1] ]width = location_size[img_i][1] - location_size[img_i][0]height = location_size[img_i][3] - location_size[img_i][2]target_width = (Resnet_height * width) // height#image = cv2.resize(image , (Resnet_height , Resnet_height) ,interpolation=cv2.INTER_CUBIC) #resizecrop_path = get_path(img_name[img_i])print('crop_path = ',crop_path)###### save crop piccv2.imwrite(crop_path + picName + '.jpg',image)###### save original pic#cv2.imwrite(crop_path + picName + '.jpg',img)for file_name in FileNames:dom = xml.dom.minidom.parse(os.path.join(FindPath, file_name))# print('filename = ',file_name)get_file_to_pic_name,err_xml = os.path.splitext(file_name)print('---------------------------')print('before = ',get_file_to_pic_name)root = dom.documentElementobject_root = root.getElementsByTagName('object')length = len(object_root)for root_i in range(length):now_name = object_root[root_i].getElementsByTagName('name')now_box = object_root[root_i].getElementsByTagName('bndbox')for get_name_nums in range(len(now_name)):####### get nameget_object_name = now_name[get_name_nums].firstChild.dataprint('get_name = ',get_object_name)all_name_list.append(get_object_name)####### get locationget_xmin , get_xmax , get_ymin , get_ymax = get_all_location(now_box)one_location_list.append(int(get_xmin))one_location_list.append(int(get_xmax))one_location_list.append(int(get_ymin))one_location_list.append(int(get_ymax))all_location_list.append(one_location_list)one_location_list = []# print('all = ',all_location_list)if len(all_name_list) != len(all_location_list):print('Error file is ',file_name,',shut down!')break# print('len = ',len(all_name_list),' ',len(all_location_list))############ crop piccrop_pic(start_name , get_file_to_pic_name,all_name_list , all_location_list)start_name += 1all_name_list=[]all_location_list=[]
3. 将voc数据集按类别保存图片,按类别保存xml标注文件。
执行之后,会将person相关的图片和xml都提取出来。

每次只能分出一种类别,例如“person”类别提取代码如下,要提取其他类别,需要修改代码,需要修改的地方我再下面注释了########### 1 change,########### 2 change,########### 3 change,另外路径根据自己的需要修改。
voc-class-pic-xml.py
import os
import os.path
import shutilfileDir_ann = './VOC2012/Annotations/'
fileDir_img = './VOC2012/JPEGImages/'########### 1 change
saveDir_img = './VOC2012-class-xml/person/' if not os.path.exists(saveDir_img):os.mkdir(saveDir_img)names = locals()for files in os.walk(fileDir_ann):for file in files[2]:print file + "-->start!"########### 2 changesaveDir_ann = './VOC2012-class-xml/person/'if not os.path.exists(saveDir_ann):os.mkdir(saveDir_ann)fp = open(fileDir_ann + file) saveDir_ann = saveDir_ann + filefp_w = open(saveDir_ann, 'w')classes = ['aeroplane','bicycle','bird','boat','bottle','bus','car','cat','chair','cow','diningtable',\'dog','horse','motorbike','pottedplant','sheep','sofa','train','tvmonitor','person']lines = fp.readlines()ind_start = []ind_end = []lines_id_start = lines[:]lines_id_end = lines[:]while "\t<object>\n" in lines_id_start:a = lines_id_start.index("\t<object>\n")ind_start.append(a)lines_id_start[a] = "delete"while "\t</object>\n" in lines_id_end:b = lines_id_end.index("\t</object>\n")ind_end.append(b)lines_id_end[b] = "delete"for k in range(0,len(ind_start)):for j in range(0,len(classes)):if classes[j] in lines[ind_start[k]+1]:a = ind_start[k]names['block%d'%k] = lines[a:ind_end[k]+1]break########### 3 changeclasses1 = '\t\t<name>person</name>\n'string_start = lines[0:ind_start[0]]string_end = lines[ind_end[-1] + 1:]a = 0for k in range(0,len(ind_start)):if classes1 in names['block%d'%k]:a += 1string_start += names['block%d'%k]string_start += string_endfor c in range(0,len(string_start)):fp_w.write(string_start[c])fp_w.close()if a == 0:os.remove(saveDir_ann)else:name_img = fileDir_img + os.path.splitext(file)[0] + ".jpg"shutil.copy(name_img,saveDir_img)fp.close()
参考资料:
https://www.cnblogs.com/tyty-Somnuspoppy/p/10250486.html
https://download.csdn.net/download/u014513323/10823680
这篇关于voc数据集的充分利用——将图片和xml按类别保存在不同文件夹、将目标剪裁后按类别保存在不同文件夹的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


