本文主要是介绍MySQL Longtext字段优化记录(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
工作中遇到一个查询很慢的情况,环境如下:
开发语言:JAVA
数据库:MySQL
数据量:1600~1800
问题:查询200条时就很慢,是慢在IO上:

如果是查全部(一千六百多条),就更慢了,几乎四十秒还没有返回:

原因:数据表中有个longtext字段:

优化思路:数据库中不存longtext字段,新增blob字段,将文本在后端压缩为bytep[]存到blob二进制字段中,查询时返回。理由:zip是现在成熟的压缩算法,基于LZ77算法和哈夫曼编码,可以把文本(String)较大程度地压缩为byte[]。注:不建议再把压缩后的byte[] BASE64为String,因为BASE64是一种编码方式。
数据流图:
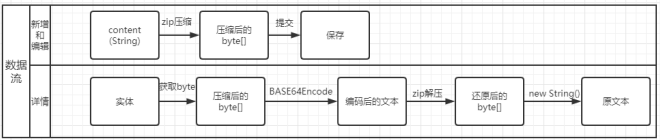
blob字段:
![]()
后端使用Zip压缩算法,使用java.util.zip包下的DeflaterOutputStream和InflaterOutputStream,压缩文本再保存。压缩使用DeflaterOutputStream:

插入测试:

插入成功:

查询时用InflaterOutputStream将byte[]解压缩还原为文本,new String():


查询测试:
插入和查询测试通过,再将原表的longtext全都更新到blob字段中,然后把原表拷贝到两张表,一张表保留longtext字段,一张表保留blob字段,查询比对如下:

说明blob字段IO速度比long text字段IO速度快很多。
注:这种方式就是不存原文本内容,弊端就是无法做对文本的搜索功能,如果要求要对文本做搜索,或者保留为文档到ES中,建议把content字段拆出来一张表和主表关联,也是保存和查询需要处理一下。
希望对你有所帮助。
这篇关于MySQL Longtext字段优化记录(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






