本文主要是介绍【考研数据结构——C语言描述】第二章 线性表链式存储结构上的基本操作——静态链表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
25计算机考研,数据结构知识点整理(内容借鉴了王道408+数据结构教材),还会不断完善所整理的内容,后续的内容也会不断更新(可以关注),若有错误和不足欢迎各位朋友指出!
目录
1.动态链表
2.静态链表
2.1静态单链表的描述
1.动态链表
之前介绍的各种链表都是使用指针类型实现的,链表中结点空间的分配和回收(即释放)均由系统提供的标准函数malloc和free动态实现,故称之为动态链表。
2.静态链表
在BASIC、FORTRAN等高级语言中并没有提供“指针”这种数据类型,若仍需采用链表作为存储结构,则可采用顺序存储结构数组模拟实现链表。在数组的每个表目中设置游标(cursor)来模拟指针,由程序员自己编写从数组中分配结点和回收结点的过程。这种方式称为静态单链表(static linked list)。
注意:静态链表是用数组来描述线性表的链式存储结构,结点也有数据域data和指针域next,与前面所讲的链表中的指针不同的是,这里的指针是结点在数组中的相对地址(数组下标),又称游标。和顺序表一样,静态链表也要预先分配一块连续的内存空间。静态链表和单链表的对应关系如图 2.14所示。
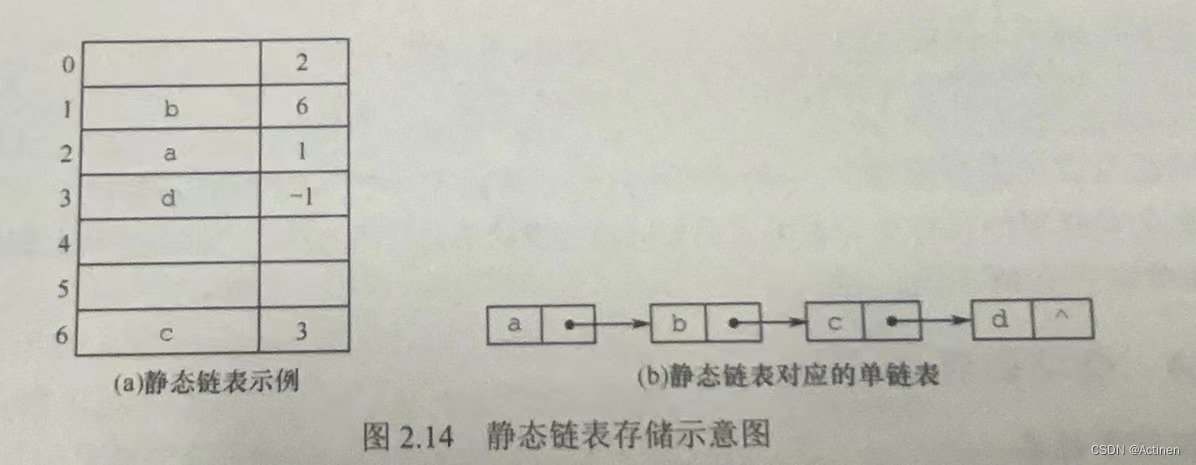
用游标模拟实现链表的方法如下:定义一个较大的结构数组作为结点空间存储池,每个结点含有两个域,即data域和cursor域。data域用来存放结点的数据信息,需注意此时cursor域存放的不再是指针而是游标,游标存放的是其后继结点在结构数组中的相对位置(即数组下标值)。数组的第0个分量可以设计成表的头结点头结点的cursor域指示了表中第一个结点的位置。表尾结点的cursor 域为-1,表示静态单链表结束。
2.1静态单链表的描述
静态单链表可以借助结构体数组来描述:
#defne Maxsize10/*链表可能达到的最大长度*/
typedef struct
{ ElemType data;int cursor;
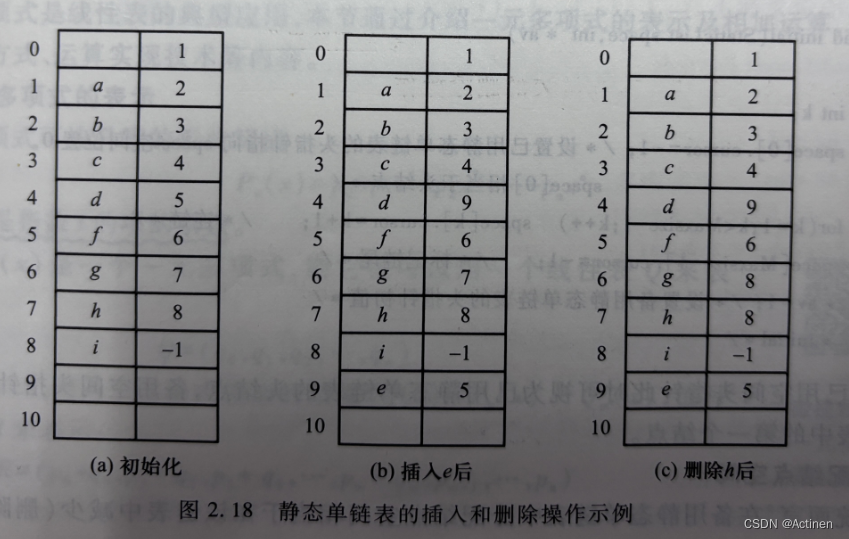
} Component,StaticList[Maxsize];通过变量定义语句 StaticList S;定义的静态单链表S中存储着线性表(a,b,c,d,f,g,h,i),Maxsize=11,如图 2.18(a)所示。要在第4个元素后插入元素e,方法是:先申请一个空闲空间并置入元素e,即令 S[9].data=e,然后修改第4个元素的游标,将e插入链表,即令S[9].cursor=S[4].eursor,S[4].cursor=9,如图2.18(b)所示。若要删除第8个元素h,则先顺着游标链通过计数找到第7个元素存储位置6,删除的具体做法是令S[6].cursor=S[7].cursor,如图2.18(c)所示。上述例子中未考虑对已释放空间的回收,这样在经过多次插入和删除后会造成静态单链表的“假满”,即表中有很多空闲空间,但却无法再插人元素。造成这种现象的原因是未对已删除元素所占用的空间进行回收。
解决这个问题的方法是:将所有未被分配的结点空间以及因删除操作而回收的结点空间通过游标链成一个备用静态单链表。当进行插入操作时,先从备用静态单链表上取一个分量来存放待插人的元素,然后将其插人已用链表的相应位置。当进行删除操作时,则将被删除的结点空间链接到备用静态单链表上以备后用。这种方法是指在已申请的大的存储空间中有一个已用的静态单链表(已用空间),还有一个备用静态单链N表(备用空间)。已用静态单链表的头指针为,备用静态单链表的头指针需另设一个变量av来存储。备用静态单链表示例如图 2.19 所示。
这篇关于【考研数据结构——C语言描述】第二章 线性表链式存储结构上的基本操作——静态链表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







