本文主要是介绍马斯克怒了,禁止员工使用苹果设备,抨击库克出卖数据给OpenA,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
昨晚,苹果发布会正式宣布了一系列重磅AI升级,甚至创造了一个新的概念——苹果智能(Apple Intelligence)。
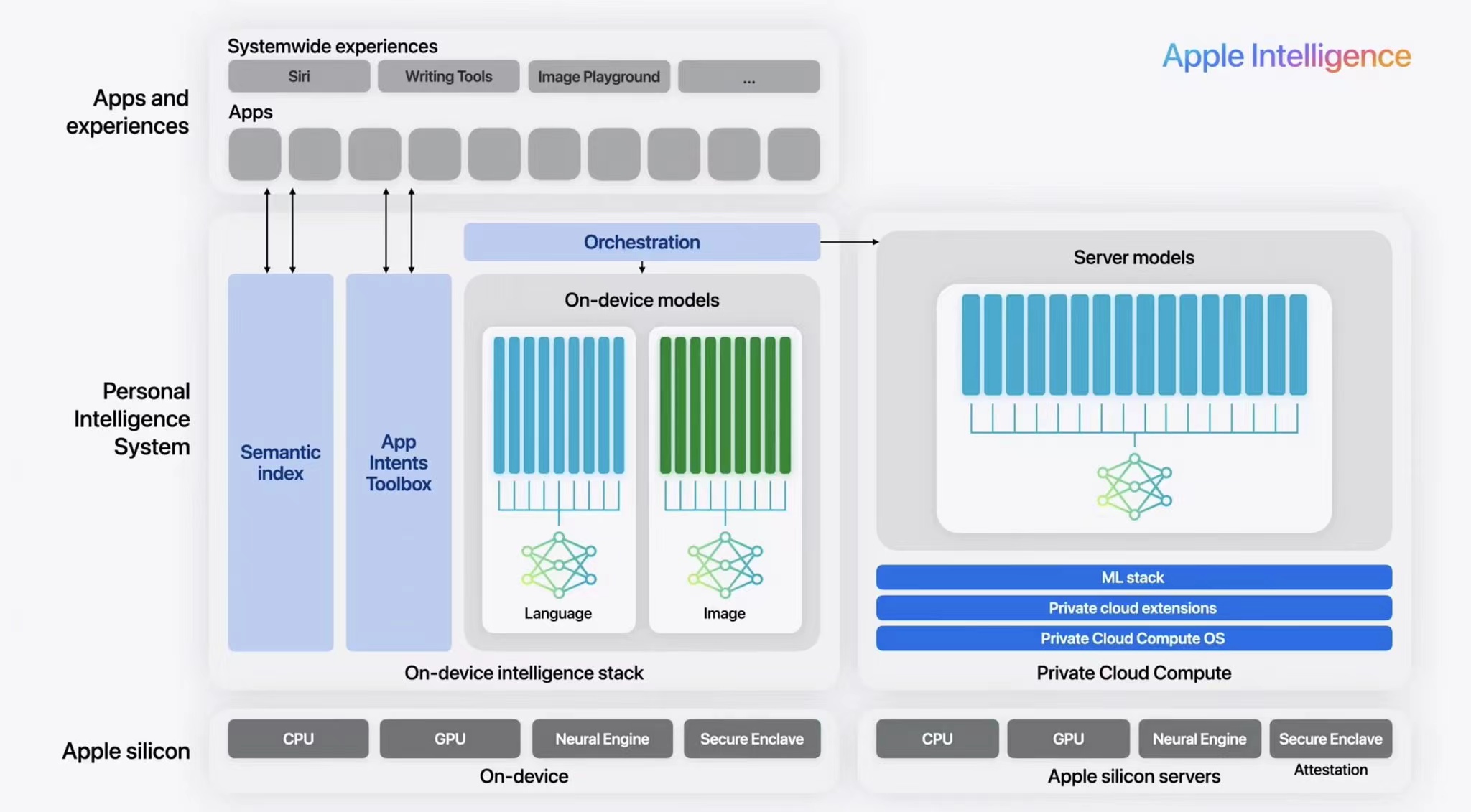
这次升级在操作系统的交互层面上进行了智能化改进,使得更多自然语音和语言理解的控制成为可能,将iPhone变成可穿戴设备的处理中心。从技术角度看,这次升级是整合而非创新,延续了苹果一贯的风格。比如,用户可以像使用GPT一样用Siri解答问题、个性化信息指令,在最新的iOS系统中直接创建“素描”、“插图”和“动画”三种类型的图像,甚至可以在笔记中手写数学公式,Apple Intelligence会用用户的字迹计算结果。
3.5研究测试:
hujiaoai.cn
4研究测试:
askmanyai.cn
Claude-3研究测试:
hiclaude3.com
这些功能的发布让很多应用黯然失色:

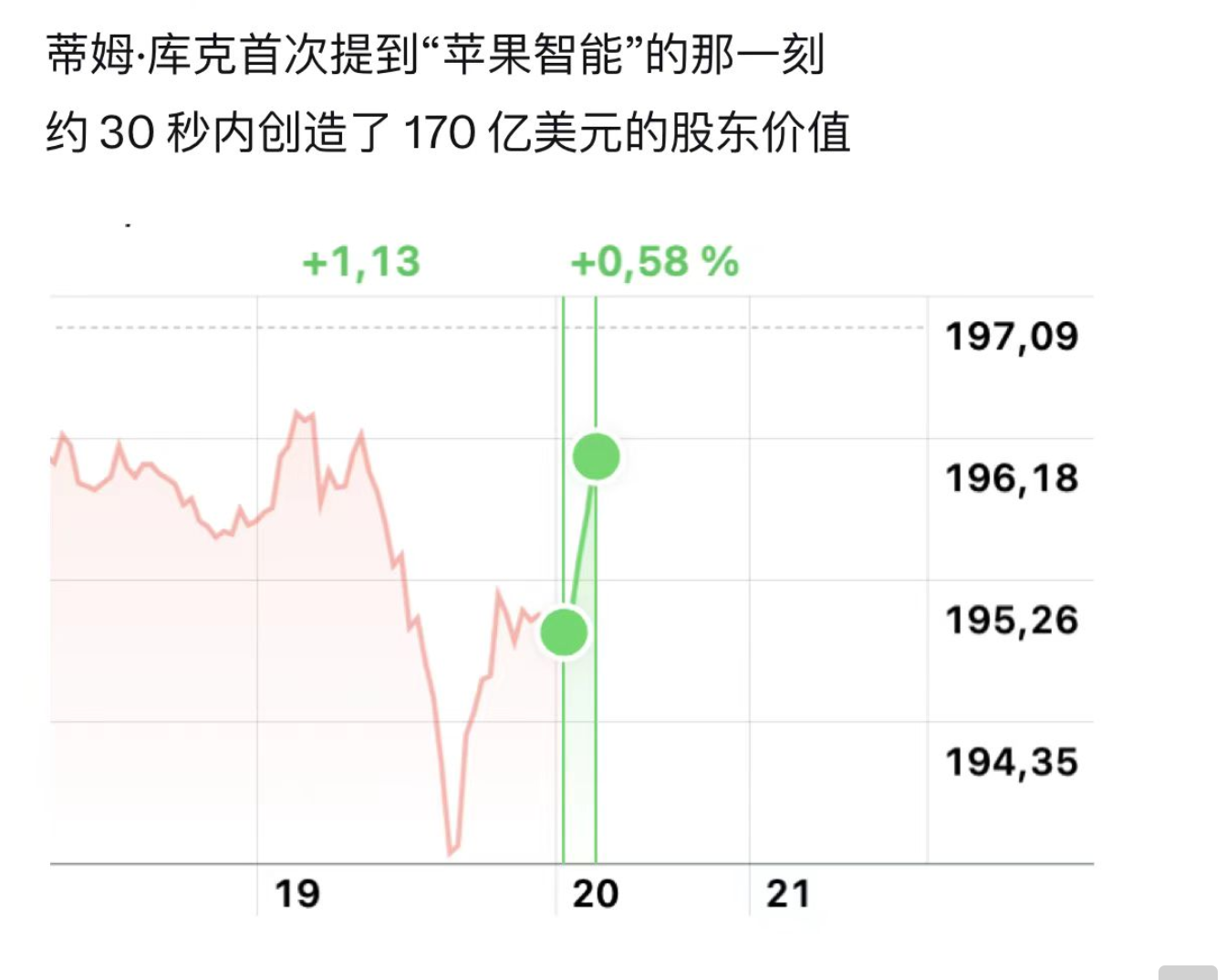
苹果从系统层面进行了全面整合,一体化体验给大众带来的惊喜使得Apple的股价在发布会后开始回升:
网友对苹果发布会展开了热烈讨论,开启了一年一度的互联网大狂欢,有人调侃苹果只是在ChatGPT上加了一个壳子,

还有人戏称苹果将AI从Artificial Intelligence变成了Apple Intelligence:

而这全网的狂欢,我们的老朋友、知名网友-马斯克也出现了!他对苹果的AI集成表示强烈反对,甚至威胁要禁止苹果设备。

马斯克扬言Apple intelligence有巨大安全问题!
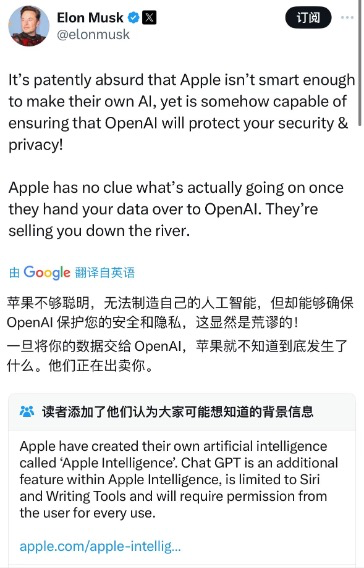
作为OpenAI的发起人之一和现任死对头,马斯克“全方位、多角度”地抨击了苹果AI面临的数据隐私安全问题。他在库克X平台的推文下留言道:“不想要。我的公司员工如果使用的话会被认为是违规行为。”
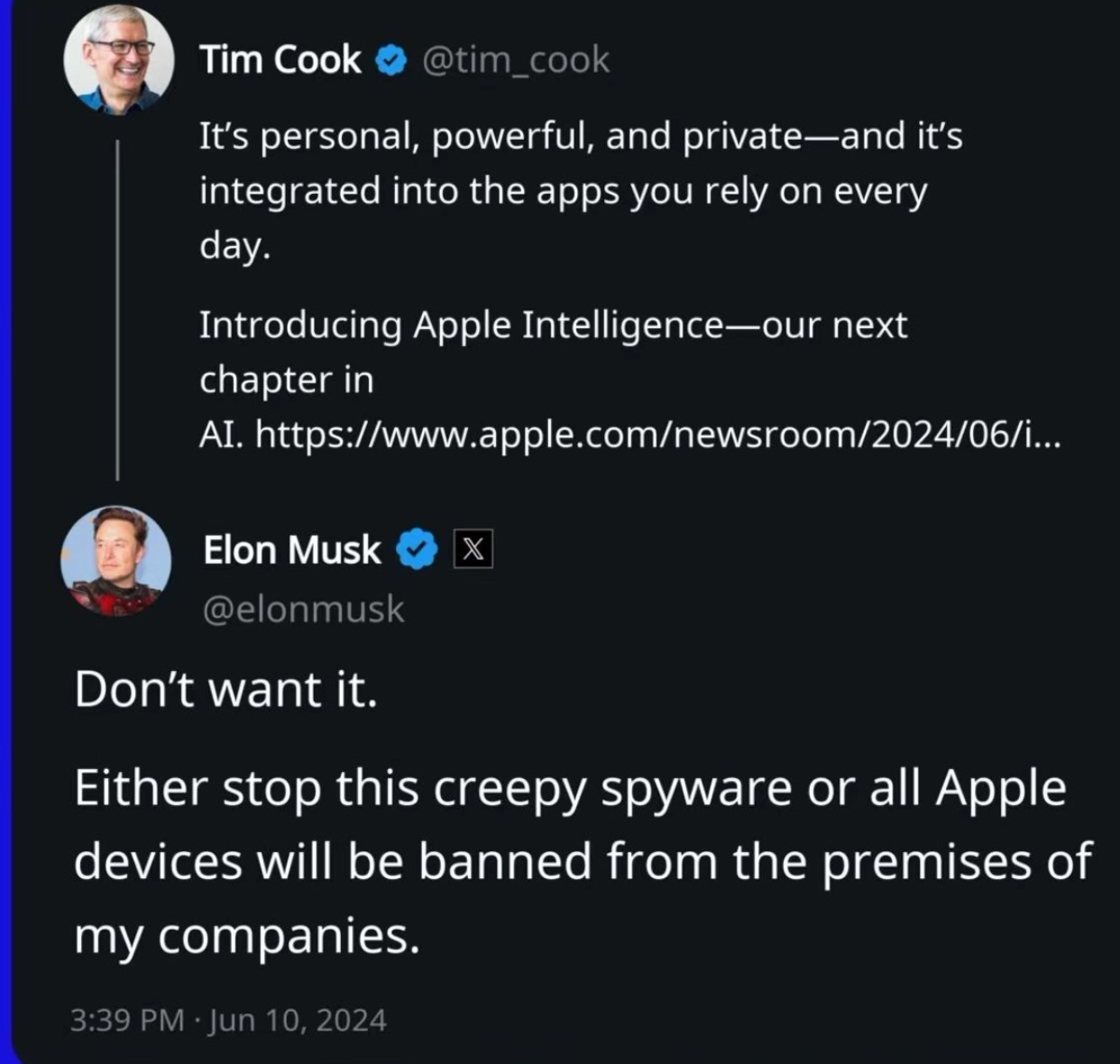
马斯克表示:“苹果还不够聪明到可以制造出自己的AI,认为OpenAI有能力保护你的安全和隐私,这显然是荒谬的!一旦将你的数据交给OpenAI,苹果就不知道到底发生了什么。他们正在出卖你。”
此外,马斯克还称:“如果苹果在操作系统层面整合OpenAI,那么苹果设备将被我的公司禁止使用。这是不可接受的安全违规行为。就连访客都必须在门口检查他们的苹果设备,然后将其存放在法拉第笼中。”

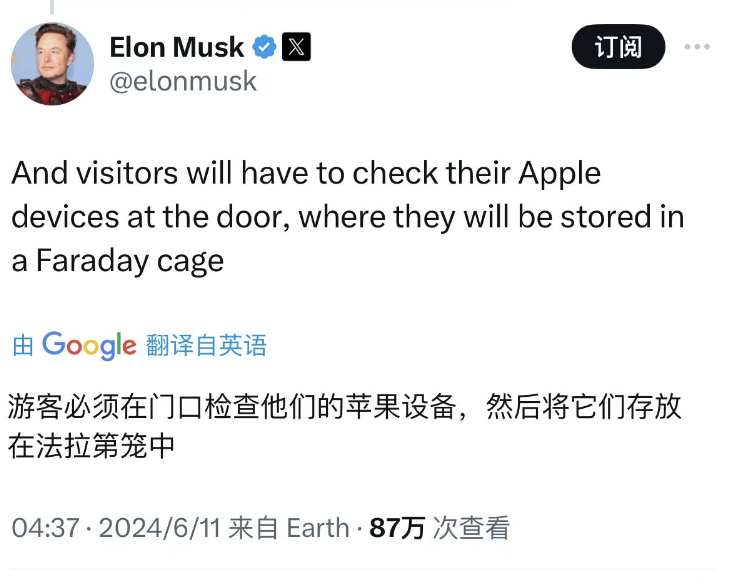
哈哈哈哈哈! 奶茶看了之后感觉非常好笑,查了下法拉第笼[下面的表情]:

奶茶早上看到马斯克的发言,第一反应是觉得非常好笑,尤其是法拉第笼的部分,认为马斯克可能是因为嫉妒心作祟导致的大破防。要知道,苹果的隐私政策可以说比 Android 制造商谷歌(其他智能手机的操作系统)的政策更为严格。苹果都不被允许的话。。。。

但是,刚刚整理这些资料时,奶茶重新审视了他的发言,突然也觉得他说的有一些道理。
如果在系统层面进行整合,对用户数据的收集和训练,用户数据的隐私和安全谁来保障呢?要知道Apple是以其可靠性、安全性、可用性而闻名,但是这次将生成式AI塞进系统,只谈技术上的起飞闭口不谈保护和隐私的界线,这是否太过疯狂了?

Apple Intelligence来了,数据从哪里来?
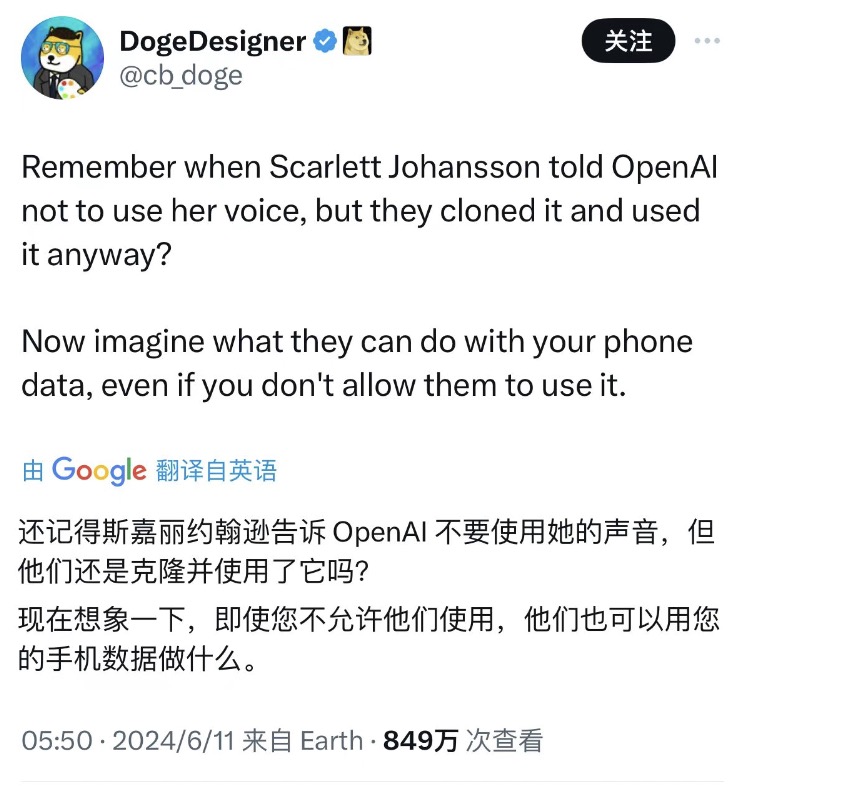
一位网友列举了一些“罪证”来证明Apple Intelligence的数据源不透明,存在巨大的数据隐私隐患,苹果试图将这种未经同意就从互联网上删除数据的技术推向公众。以下是推测的潜在数据源列表:
-
首先一个可能的数据源是名为DataComp的研究项目。DataComp是一个由大学研究人员、苹果和LAION(是的,LAION)研究人员合作的项目,旨在构建一个更大版本的LAION,使用完全相同的网页抓取技术。LAION 5B由Stability AI资助,最初作为研究项目进行,后来用于商业目的。DataComp AI团队使用与LAION相同的方法构建大型数据集,并得到了Apple、Google和Stability AI等公司的支持。这项研究会像Stability AI对LAION所做的那样最终用于商业用途吗?


-
另一个线索是苹果GenAI可能使用了某种形式上的Stable diffusion,发布会上的图像看起来确实可能如此。网友提及Apple 在 2022 年 12 月官宣了稳定扩散模型现在可以在其平台上运行。

-
还有一个可能的数据源是老牌的 Dall-3,因为 Apple 最近与 Open Ai 达成了交易。网友提到需要注意的是,Open Ai也从未透露过他们在任何事情上使用的数据集……
网友指出比起技术带给我们的震撼,我们必须清楚的记住生成式人工智能的运作依赖于大规模的过度扩张和对私人和知识产权的侵犯。
所有生成式AI的公司都是如此。
当苹果将这项技术强加给我们时,要记住他们也不例外,不要用崇拜的炒作来看待这一声明,而要用紧迫感和审视来看待,因为一家大型科技公司正试图将这种极度剥削性的技术正常化,这是它应得的。
至少要问“你从哪里获得的数据?。
小结
奶茶还准备了一些这次发布会相关的一些meme梗图给大家品鉴!








参考资料
[1]https://machinelearning.apple.com/research/datacomp
[2]https://machinelearning.apple.com/research/stable-diffusion-coreml-apple-silicon
[3]https://x.com/kortizart/status/1800261496686981161?s=46
这篇关于马斯克怒了,禁止员工使用苹果设备,抨击库克出卖数据给OpenA的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





