本文主要是介绍计划任务 之 一次性的计划任务,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
计划任务
作用:定时自动完成特定的工作
计划任务的分类:
(1)一次性的计划任务
- 例如下周三对系统的重要文件备份一次
(2)周期性重复计划任务
- 例如每天晚上12:00备份一次
一次性的任务计划:
- at
- batch
周期性计划任务
- crontab
- anacron
at一次性任务计划
at 时间ctrl+d 保存退出 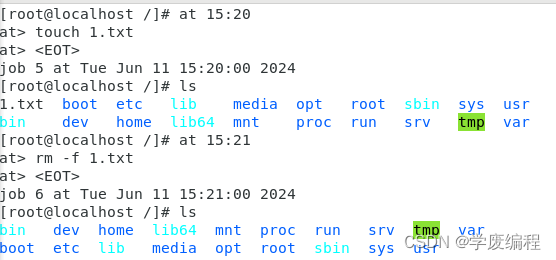
选项:
- -q:指定任务计划的队列编号
- -l:显示尚未执行的计划任务(等同于命令atq)
- -d num:删除指定编号的计划任务(等同于命令atrm)
- -c num:显示指定编号的计划任务的具体的命令
- -f file time :从文件中读取要执行的操作
-q:指定任务计划的队列编号
例子:
![]()
-l:显示尚未执行的计划任务(等他于命令atq)
例子:
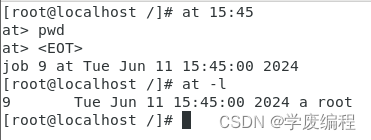
9:编码
Tue jun 11 15:45:00 2024:计划任务执行时间
a:队列编号
root:发起计划任务的用户
-d num:删除指定编号的计划任务(等他于命令atrm)
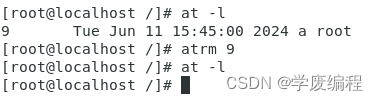
-c num:显示指定编号的计划任务的具体的命令
![]()
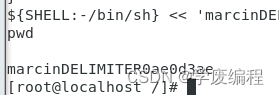
-f file time :从文件中读取要执行的操作
从1.txt中读取命令
第一步:创建一个1.txt

vi到1.txt里面写入要执行的命令

第二步:读取1.txt中的命令(16:02执行)
at -f 1.txt 16:02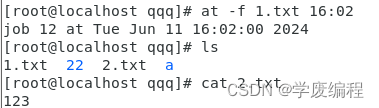
at计划任务中时间的表达方式:
时间设置:
at允许使用一套相当复杂的指定时间的方法。
- 能够接受在当天的hh:mm(小时:分钟)式的时间指定。假如该时间已经过去,那么就放在第二天执行。
- 也能够使用midnight(深夜)、noon(中午)、teatime(午茶时间,一般是下午4点)等比较模糊的词语来指定时间。
- 用户还能够采用12小时计时制,即在时间后面加上AM(上午)或者PM(下午)来说明是上午还是下午。
- 也能够指定命令执行的具体日期,指定格式month day(月 日)或mm/dd/yy(月/日/年)或dd.mm.yy(日.月.年) 指定的日期必须跟在指定时间后面。
- 上面介绍的都是绝对计时法,其实还能使用相对计时法,这对于安排不久就要执行的命令是很有好处的。指定格式为:now + count time-units,now就是当前时间,time-units是时间单位,这里能够是minutes(分钟)、hours(小时)、days(天)、weeks(星期)count是时间的数量,究竟是几天,还有几个小时,等等。
- 更有一种计时方法是直接使用today(今天) 、tomorrow(明天) 来指定完成命令的时间。
特殊方式:
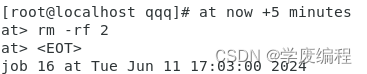
(1)now+5 minutes 5分钟后执行这个计划任务
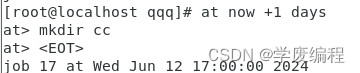
(2)now+3 days 3天后的现在时间
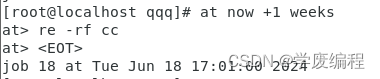
(3)now+3 weeks 3周
(4)am 上午
- 4am+1weeks
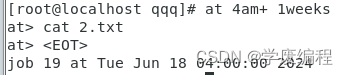
(5)12:00+1day

/etc/con.deny
黑名单文件(文件中出现的用户不能创建计划任务)
这篇关于计划任务 之 一次性的计划任务的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






