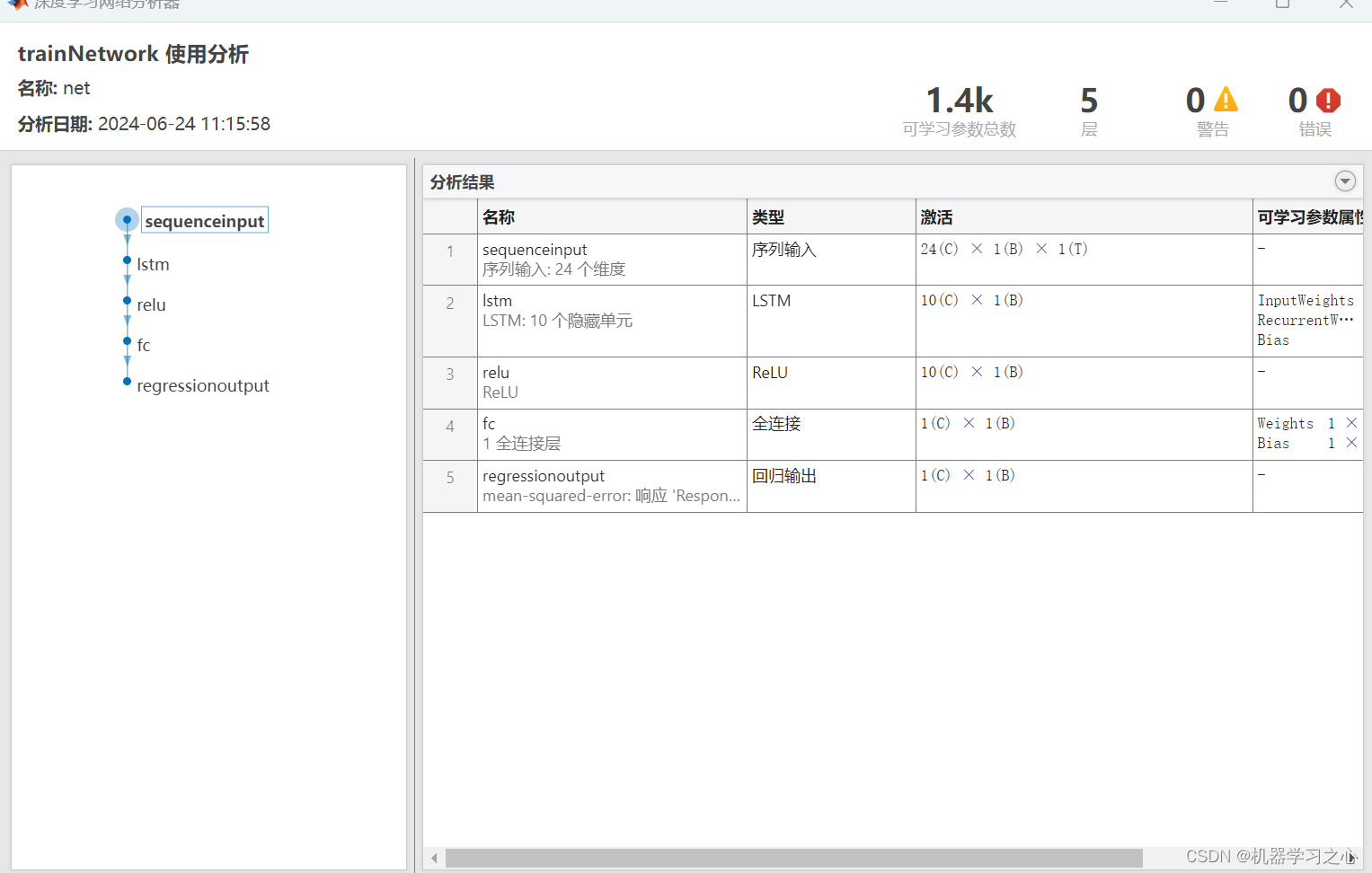
本文主要是介绍爬取京东商品图片的Python实现方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言
在数据驱动的商业环境中,网络爬虫技术已成为获取信息的重要手段。京东作为中国领先的电商平台,拥有海量的商品信息和图片资源。本文将详细介绍如何使用Python编写爬虫程序,爬取京东商品的图片,并提供完整的代码实现过程。
爬虫基础
在开始编写爬虫之前,需要了解一些基本的网络爬虫概念:
- HTTP请求:爬虫通过发送HTTP请求获取网页数据。
- HTML解析:解析返回的HTML文档,提取所需信息。
- 会话管理:使用Session保持登录状态和Cookies。
环境准备
- Python:编程语言。
- Requests:发送HTTP请求。
- BeautifulSoup:解析HTML文档。
- Lxml:解析库,BeautifulSoup的后端解析器。
安装所需库:
pip install requests beautifulsoup4 lxml
爬虫实现步骤
1. 设置请求头和代理
为了避免被识别为爬虫,需要设置User-Agent和代理IP。
import requests
from bs4 import BeautifulSoup# 代理服务器配置
proxyHost = "www.16yun.cn"
proxyPort = "5445"
proxyUser = "16QMSOML"
proxyPass = "280651"# 构建包含代理服务器认证信息的代理URL
proxy_url = f"http://{proxyUser}:{proxyPass}@{proxyHost}:{proxyPort}"# 请求头,包含User-Agent
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}# 使用代理的requests会话
session = requests.Session()
session.headers.update(headers)# 配置代理,支持HTTP和HTTPS
session.proxies = {'http': proxy_url,'https': proxy_url
}# 示例使用会话对象发送请求
def get_page(url):try:response = session.get(url)response.raise_for_status() # 检查请求是否成功return response.textexcept requests.exceptions.HTTPError as errh:print(f'HTTP Error: {errh}')except requests.exceptions.ConnectionError as errc:print(f'Error Connecting: {errc}')except requests.exceptions.Timeout as errt:print(f'Timeout Error: {errt}')except requests.exceptions.RequestException as err:print(f'OOps: Something Else: {err}')# 使用get_page函数获取网页内容
# html_content = get_page('http://example.com')
2. 发送请求
使用Requests库发送GET请求。
def get_page(url):response = requests.get(url, headers=headers)return response.text
3. 解析HTML
使用BeautifulSoup解析HTML,提取商品图片链接。
def parse_page(html):soup = BeautifulSoup(html, 'lxml')img_tags = soup.find_all('img')img_urls = [img.get('data-src') for img in img_tags if 'data-src' in img.attrs]return img_urls
4. 保存图片
下载并保存图片到本地。
def save_images(img_urls, folder='images'):for i, url in enumerate(img_urls):try:response = requests.get(url, stream=True)if response.status_code == 200:with open(f'{folder}/img_{i}.jpg', 'wb') as f:for chunk in response.iter_content(1024):f.write(chunk)else:print(f'Failed to download image: {url}')except Exception as e:print(f'Error occurred while downloading image {url}: {e}')
5. 主函数
整合以上步骤,实现爬取京东商品图片的功能。
def crawl_jd(keyword):search_url = f'https://search.jd.com/Search?keyword={keyword}&enc=utf-8'html = get_page(search_url)img_urls = parse_page(html)save_images(img_urls)if __name__ == '__main__':crawl_jd('笔记本电脑')
注意事项
- 遵守robots.txt:在爬取前,检查目标网站的robots.txt文件,确保爬虫行为符合规定。
- 请求频率控制:避免过快发送请求,以免给服务器造成负担。
- 异常处理:代码中应包含异常处理逻辑,确保程序稳定运行。
这篇关于爬取京东商品图片的Python实现方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!

![[word] word设置上标快捷键 #学习方法#其他#媒体](https://img-blog.csdnimg.cn/img_convert/7a1ef11f92414f74d152e768c38640bf.gif)