本文主要是介绍【C语言】预处理详解(下卷),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
紧随上文。
命令行定义
比如关机命令:
shutdown -s -t 60其中-s,-t是命令行参数。
传的参数不同,效果也不同。
许多C的编译器提供了一种能力,允许在命令行中定义符号,用于启动编译过程。
如,当我们根据同一个源文件要编译出一个程序的不同版本时,这个特点有些用处。(假如某个程序中声明了一个某个长度的数组,如果机器内存有限,我们需要一个很小的数组,但是另外一个机器内存大些,我们需要一个数组能够大写。)
这个假如的例子:
#include <stdio.h>int main()
{int arr[SZ];int i = 0;for(i = 0; i< SZ; i ++){arr[i] = i;}for(i = 0; i< SZ; i ++){printf("%d " ,arr[i]);}printf("\n" );return 0;
}可以看到,我们全程并没有给SZ赋值,但是我们可以通过命令行定义来给SZ指定值:
gcc test.c -D SZ=10 -o test这是在用gcc来编译test.c时我们用-D选项来指定代码中SZ的值。-o指定我们编译生成的可执行程序名字为test。然后:
./test我们就打印出了要的内容,0~9。
我们可以改为-D SZ=100,其他不变,就打印出0~99。可以根据需要,在参数部分修改指定。
条件编译
在编译一个程序的时候我们如果要将一条语句(一组语句)编译或者放弃是很方便的。这是因为有条件编译指令的存在。
什么是条件编译?满足条件才参与编译,不满足就不参与编译。
常见的条件编译指令:
1.
#if 常量表达式
//…
#endif
//常量表达式由预处理器求值
如:
#deifne _DEBUG_ 1
#if _DEBUG_
//…
#endif
举个例子:
(注意:#if和#endif要首尾呼应,配套使用。)
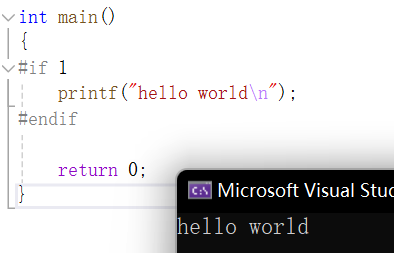
#if 1 条件为真,所以会打印。而如果是这样,就不会打印:
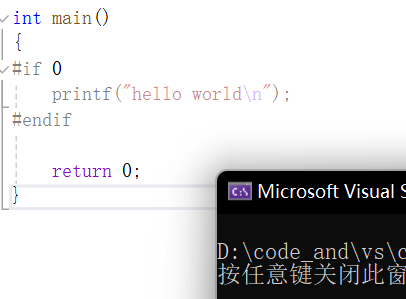
再举一个例子:
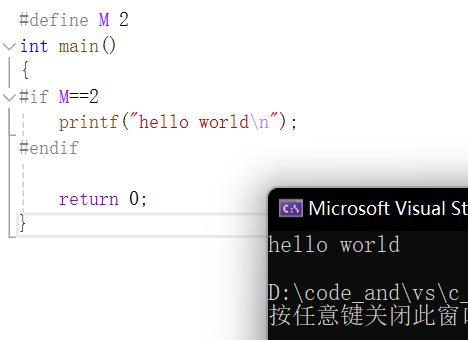
这个代码是怎么做的呢?其实是在预处理时变成:
int main()
{printf("hello world\n");return 0;
}#if后表达式为真,所以把预处理指令#if #endif都删了,只留下这一句实际代码。
如果改成
#if M==3为假,预处理后就变成了:
int main()
{return 0;
}所以,当我们一整段代码都不想要时,便可以这么写:
#if 0
#define M 2
int main()
{printf("hello world\n");return 0;
}
#endif如果写成这样是不行的:
int main()
{int a = 2;
#if a==2printf("hello world\n");
#endifreturn 0;
}a是变量而非常量表达式。打印的代码不参与编译。
为什么?因为局部变量时程序运行起来才会创建的,而预处理在运行之前发生。
这是错误的写法。
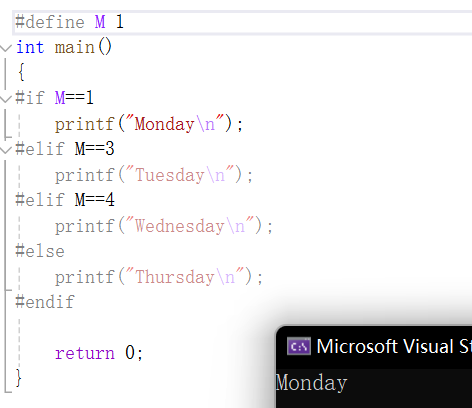
多个分支的条件编译:
2.
#if 常量表达式
//…
#elif 常量表达式
//…
#else
//…
#endif
演示: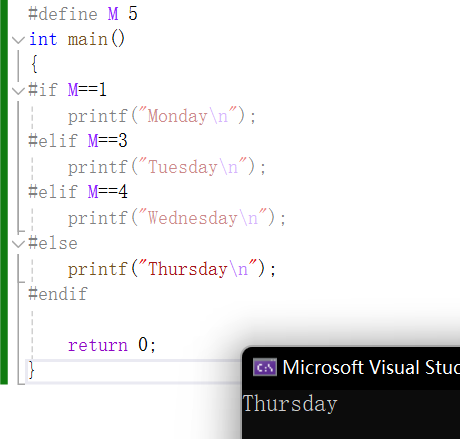
和if if…else else语句类似,只会选某一种情况进入。如果前面有一个满足后面的都不会执行,前面都不满足就执行else。
判断是否被定义:
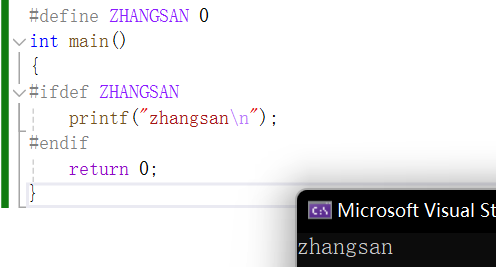
3.
#if defined(symbol)
#ifdef symbol
(两行等效)
意思是如果定义过symbol,就怎么样。
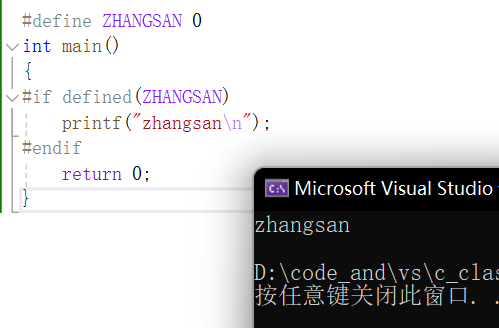
举例:
int main()
{
#if defined(ZHANGSAN)printf("zhangsan\n");
#endifreturn 0;
}意思是如果我们定义过符号ZHANGSAN,就会执行此后(#endif之前)的代码,而现在我们没有定义过,所以不会打印。
定义的常量是什么值不重要,定义过就会打印。
另一种写法:
这一组指令还有与其逻辑相反的一组指令:
意思是如果没被定义的话,怎么样:
#if !defined(symbol)
#ifndef symbol
举例:
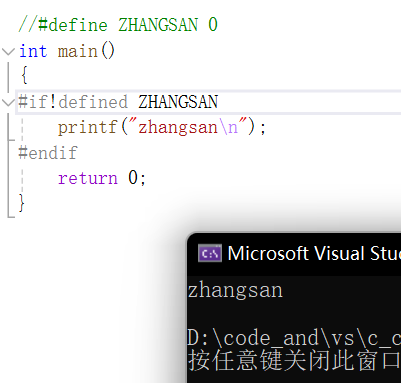
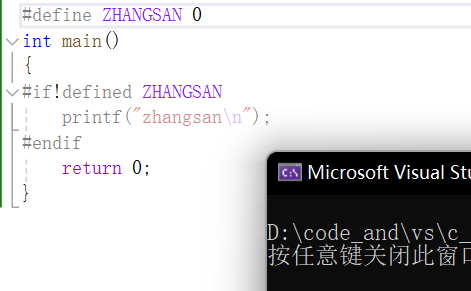
当然也可以换成等效的另一写法。
嵌套指令
例子:
#if defined(OS_UNIX)#ifdef OPTION1unix_version_option1();#endif#ifdef OPTION2unix_version_option2();#endif
#elif defined(OS_MSDOS)#ifdef OPTION2msdos_version_option2();#endif
#endif首先是一分为二,上面和下面的外层条件编译指令二选一进入(或者都没定义都不进入),然后进入了一个之后,又是一分为二(也可以都没定义,都不执行)。
和if语句一样,逻辑上可以嵌套。
这种使用在头文件中非常普遍。一般用在跨平台性代码的编写。写一份代码希望在不同平台都能跑。
头文件的包含
头文件的包含有两种形式
1.#include<stdio.h>
2.#include"xxx.h"
这两种形式的区别是什么?
#include"xxx.h"的形式是自己创建的头文件的包含,叫本地文件包含。
#include<stdio.h>一般指标准库中头文件的包含。
它们的区别体现在查找策略上:
本地文件包含的查找策略:
先在源文件所在目录下查找,如果该头文件未找到,编译器就像查找库函数头文件一样在标准位置查找头文件。如果找不到就提示编译错误。
源文件所在目录(路径)我们知道在哪(就是电脑上当前工程的文件夹),那么标准库的目录在哪呢?
Linux环境的标准头文件的路径:
/usr/includeVS环境的标准头文件的路径(不确定):
C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\include
//VS2013的默认路径(可以用Everything找)
标准库中头文件的包含的查找策略:
在标准位置查找头文件,如果找不到就直接提示编译错误。
这样是不是可以说,对于库文件也可以使用""的形式包含?
确实可以,但是这样查找的效率就低一些,当然这样也不容易区分库文件还是本地文件了。
如果能区分时就应该写对应的的方式,不要统一用""。
嵌套文件包含
当我们包含头文件时其实就是将头文件内容拷贝过来,写了几次就会在预处理拷贝几份:
#include"test.h"
#include"test.h"
#include"test.h"
#include"test.h"
#include"test.h"这样就真的拷贝了五份头文件。
所以有时不小心多次包含时,同一份代码就可能拷贝了多次。可能会导致编译时间变长。
在编写大型的工程时,可能会无奈发生这样的情况:
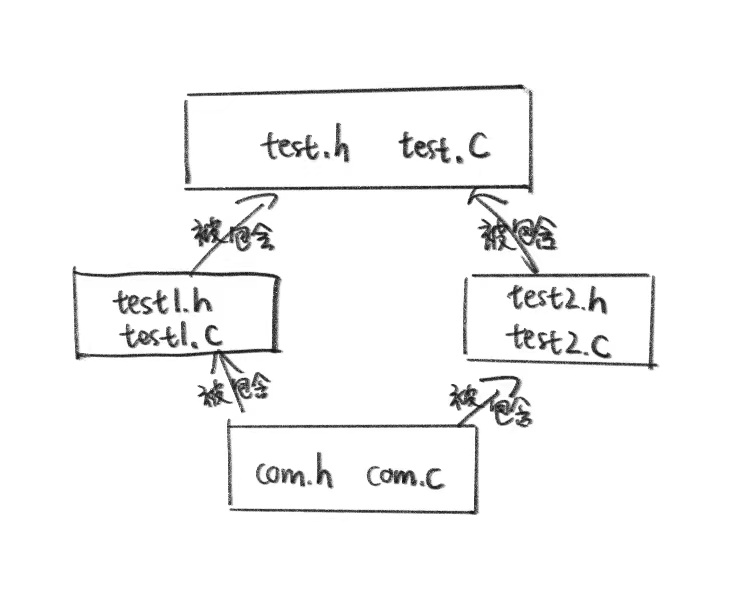
如果我们把test.h写成这样:
#ifndef __TEST_H_
#define __TEST_H_int Add(int x, int y);struct S
{char c;int i;
};#endif那么就算我们包含5次test.h,也只会拷贝一次。
还有一种更简单的方式:
#pragma onceint Add(int x, int y);struct S
{char c;int i;
};在VS中我们创建新的.h文件时,它会自己在开头加上这一句。
其他预处理指令
这些是我们已学过的预处理指令:
#define
#include
#if#endif
#ifdef
#ifndef
#elif
#pragma
#undef
#else
还有其他的预处理指令:
1 #error
2 #pragma
3 #line
4 #pragma pack() 在结构体博客介绍过
……
可以自行了解。
本文结束,祝阅读愉快^_^
这篇关于【C语言】预处理详解(下卷)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






