本文主要是介绍【智算101】为什么用好大模型,离不开“向量数据库“呢,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关注【云原生AI百宝箱】公众号,获取更多云原生AI消息
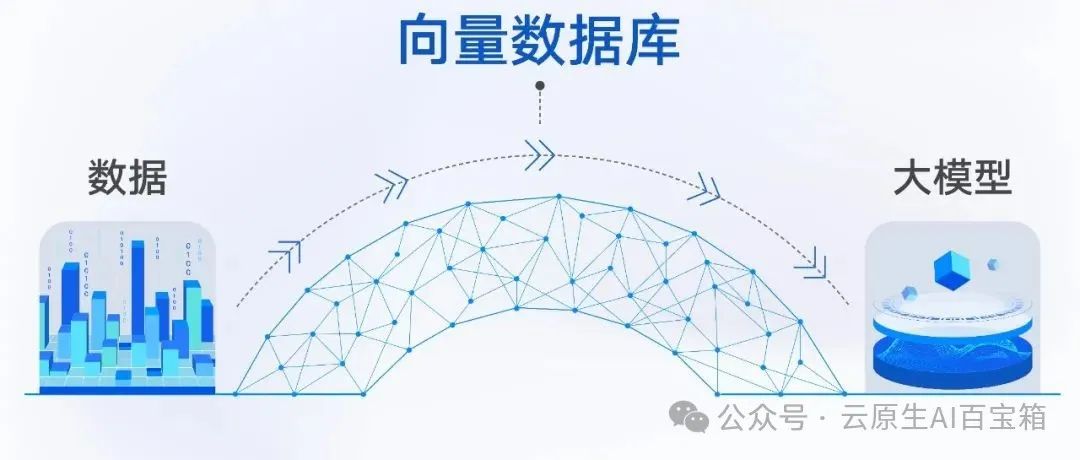
大模型离不开向量数据库回答这个问题之前,我们先来理解一下什么是向量。

这是一个苹果,但在发明苹果这个词之前,人们怎么描述它呢?

颜色、大小、形状、纹理,找到更多的特征,就能对苹果的定义更清晰。
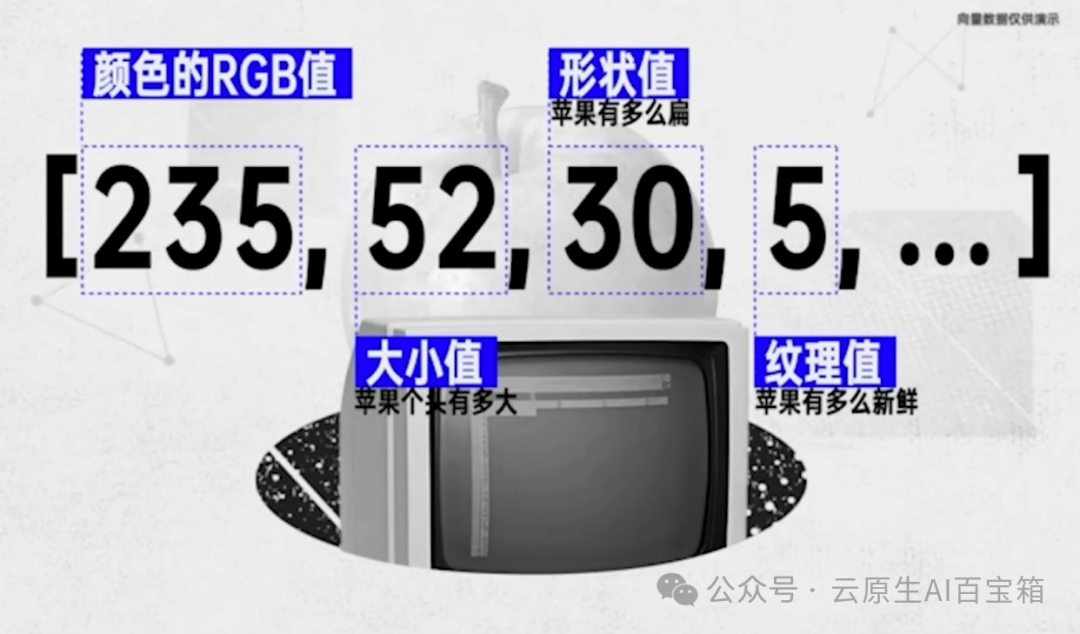
把这些特征用数字表述就可以得到一个数组,就是向量。

当复杂的图形变成了计算机熟悉的数字,它就认识苹果了。当新的苹果出现,计算机还能认出来它吗?当然。

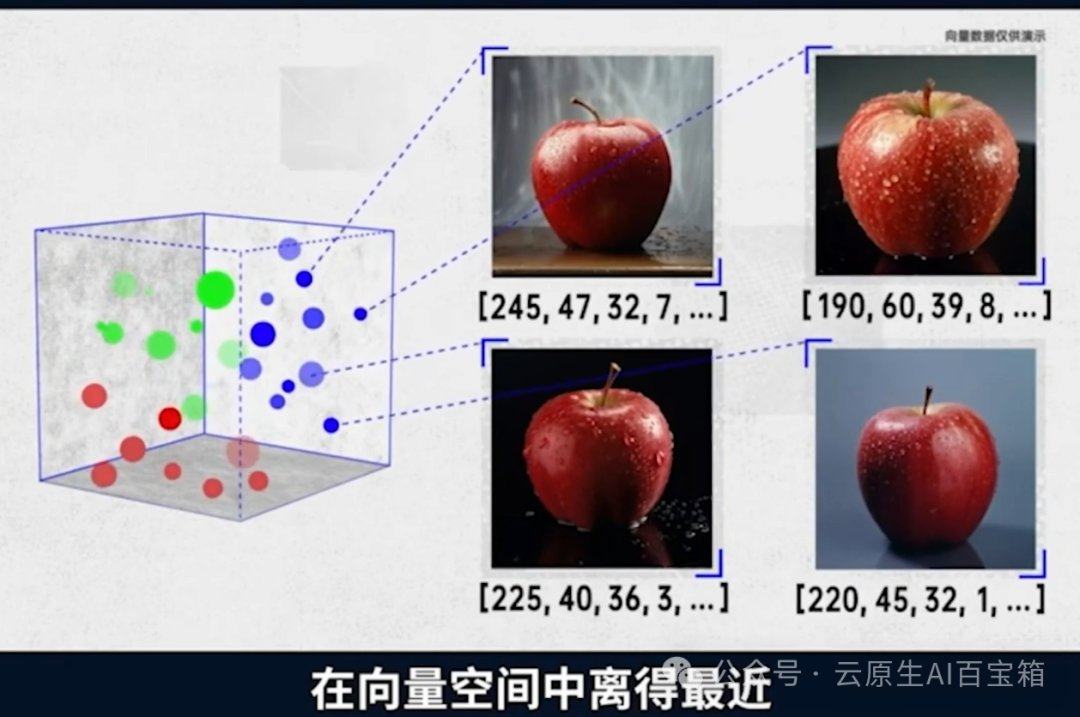
因为这些图像,在向量空间中离得最近,相似性最高。今天让我们惊叹不已的人工智能,往往通过上千个向量维度来学习、训练,他们就像是AI大模型的眼睛。

当AI大模型遇上庞大的向量数据,这组黄金搭档如何让硅基生物更聪明呢?以大语言模型为例,简单来说,在训练时,喂给它的词句都会先转化为向量数据。
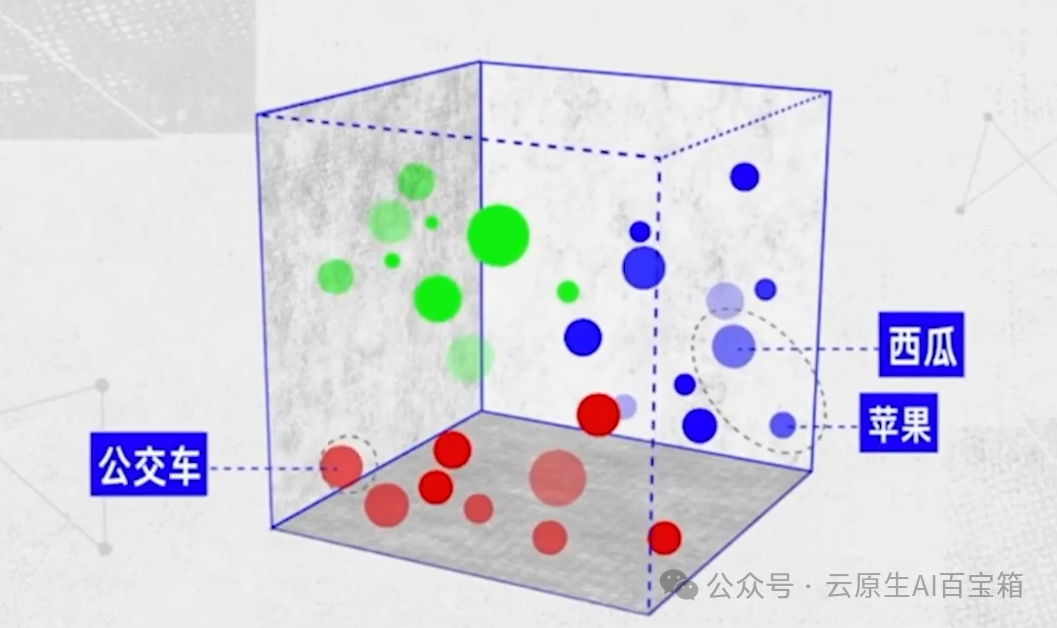
当训练数据里出现多组类似的语言时,在向量数据组成的高维空间相近的词汇就会距离更近,语言模型就可以逐渐捕捉到词汇间的语义和语法,比如他会更明白苹果和西瓜与异常接近,和公交车相差甚远。
接下来模型要对对上下文进行理解,此时transformer架构就开始发挥作用,从每个词自身出发,观察和其他词之间的关系权重。

云原生AI百宝箱
行万里路,此处相逢,共话云原生AI之道。 偶逗趣事,明月清风,与君同坐。
63篇原创内容
公众号
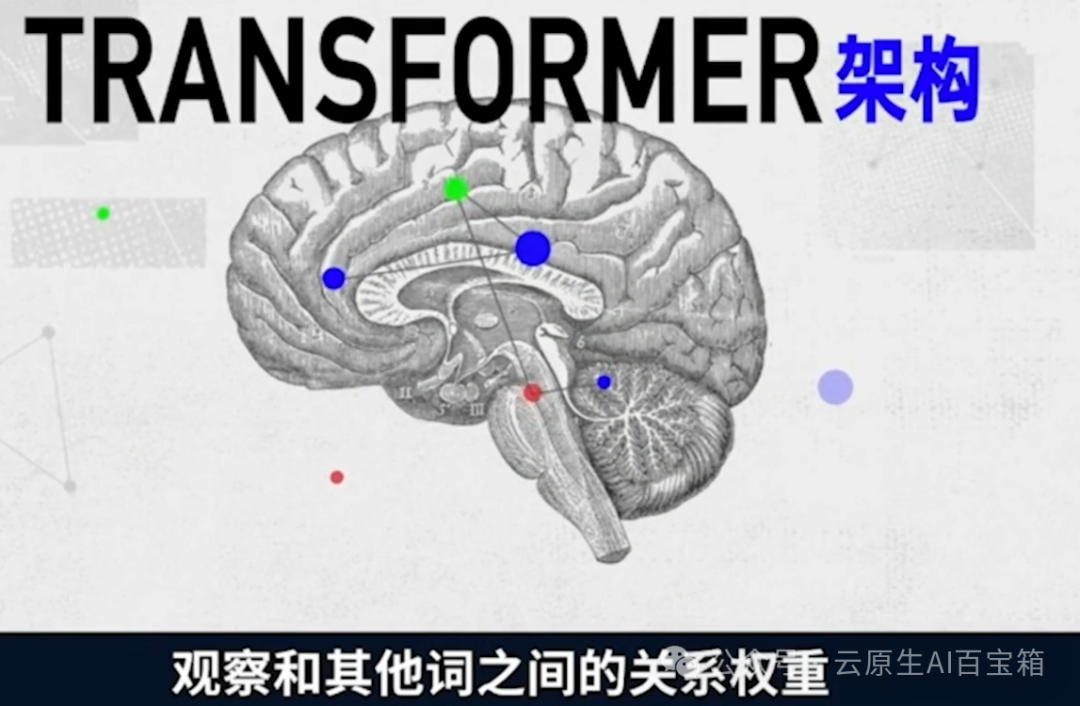
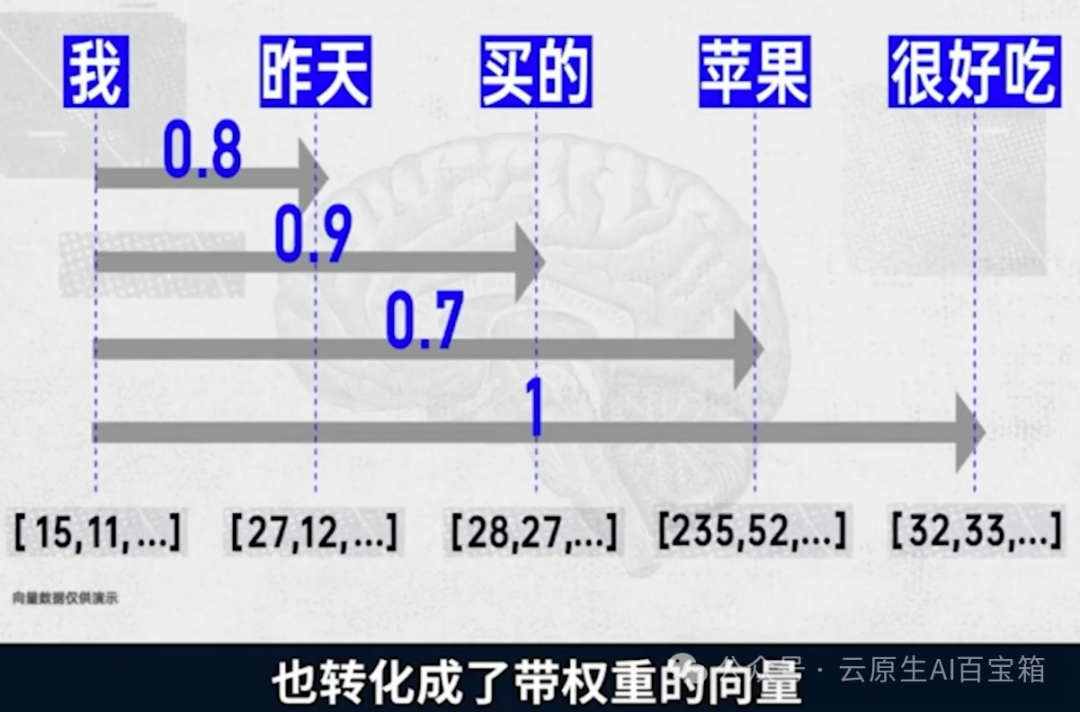
例如,这句话里很好吃,和我关系权重最大,权重结果被当做新的维度记录下来,一句更复杂的话,也转化成了带权重的向量。

语言模型经过查询、计算,生成权重最高的答案输出给你,一次问答就完成了。
实际上,大模型训练推理过程更为复杂,他们需要处理如文本、图像、音视频等大量非结构化数据,并转化为向量数据进行学习。这些数据的规模动辄过亿,向量的维度可能高达数千。
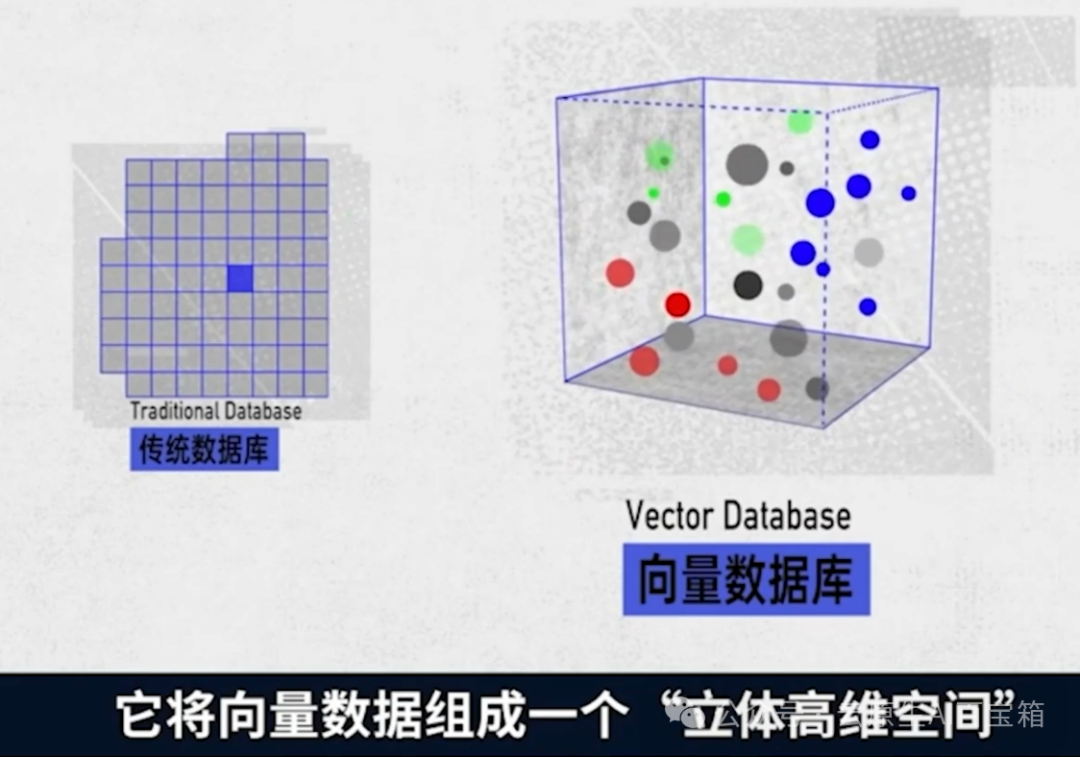
在选择数据库时,传统数据库只能进行行列检索,一一对应,再输出精准的答案。
但向量数据库则是专门为非结构化数据检索而设计,它将向量数据组成一个立体高维空间,在空间中进行模糊检索,能够快速输出权重最高的答案。
推荐阅读
- 叮,你收到一份来自CNCF的云原生景观简介
- 要魔改Kubernetes,我们可以从哪里扩展
- 问题排查太烦心,试试GPT的超能力
- Copa:无需重建镜像,直接修补容器漏洞
- 玩转K8s网络:16张图带你从小白到专家
- 1000节点集群,5秒搭建好
- 流量何处来又往何处去,这次一目了然
- Kubernetes CNI 插件选型和应用场景探讨
- 块/文件/对象存储难统一管理,试试这个集大成者
- GPU越来越难买,如何提高利用率
- 监控外部服务太复杂?ServiceMonitor 和 PrometheusRule有妙招
- 容器快了,却不安全了,Rootless 安排上
- 还在Jenkins点点,快来体验Tekton的灵活自动化
- 懒人福音:LazyDocker轻松驾驭容器,操作高效省心
这篇关于【智算101】为什么用好大模型,离不开“向量数据库“呢的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








