本文主要是介绍为什么使用Java8中的并行流运算耗时变长了?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在文章开头
近期对迭代的功能进行压测检查,发现某些使用并发技术的线程任务耗时非常漫长,结合监控排查定位到的并行流使用上的不恰当,遂以此文分享一下笔者发现的问题。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的 java coder ,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

问题复现
需求背景
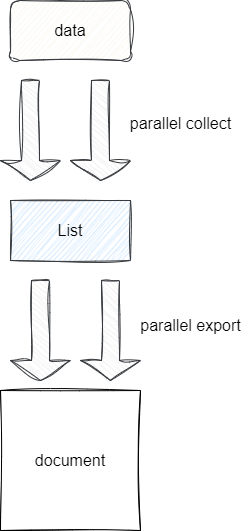
这里笔者先简单介绍一下当前功能的使用背景,当前功能是一些大数据量的计算密集型任务定时执行,在常规优化效率有限的情况下,考虑到复用性,笔者通过JDK8底层内置的并行流完成这些任务的计算。
对应优化思路如下,可以看到针对每一批数据,笔者都是通过并行流采集出集合并将其写入文档:
常规串行计算
我们给出第一段代码示例,为了更专注于本文并行流问题的剖析,笔者对于两个并行线程所执行的数据采集和写入文档的操作通过原子类并发计算来模拟:
public static void main(String[] args) throws Exception {AtomicInteger atomicInteger = new AtomicInteger();CountDownLatch countDownLatch = new CountDownLatch(2);long beginTime = System.currentTimeMillis();//模拟采集5000w数据并写入本地文档中new Thread(() -> {IntStream.range(0, 5000_0000).forEach(i -> atomicInteger.getAndIncrement());countDownLatch.countDown();}, "t1").start();//模拟采集5000w数据并写入本地文档中new Thread(() -> {IntStream.range(0, 5000_0000).forEach(i -> atomicInteger.getAndIncrement());countDownLatch.countDown();}, "t2").start();//等待两个线程结束countDownLatch.await();//输出耗时long endTime = System.currentTimeMillis();System.out.println("atomicInteger: " + atomicInteger.get());System.out.println("time: " + (endTime - beginTime) + " ms");}
输出结果如下,可以看到1e的数据耗时大约需要1.6s:
atomicInteger: 100000000
time: 1620 ms
单任务并行流
我们再进行更进一步的优化,将某个线程的任务使用并行流进行原子运算(模拟业务操作):
public static void main(String[] args) throws Exception {AtomicInteger atomicInteger = new AtomicInteger();CountDownLatch countDownLatch = new CountDownLatch(2);long beginTime = System.currentTimeMillis();//模拟并行流采集5000w数据并写入本地文档中new Thread(() -> {IntStream.range(0, 5000_0000).parallel().forEach(i -> atomicInteger.getAndIncrement());countDownLatch.countDown();}, "t1").start();//模拟采集5000w数据并写入本地文档中new Thread(() -> {IntStream.range(0, 5000_0000).forEach(i -> atomicInteger.getAndIncrement());countDownLatch.countDown();}, "t2").start();//等待两个线程结束countDownLatch.await();//输出耗时long endTime = System.currentTimeMillis();System.out.println("atomicInteger: " + atomicInteger.get());System.out.println("time: " + (endTime - beginTime) + " ms");}
从输出结果来看,性能表现提升了几毫秒,相对于最后生产上业务的数据量而言,可能会提升更多:
atomicInteger: 100000000
time: 1337 ms
双并行流运算
结合上述结果,我们大胆提出,是否所有任务都通过通过并行流进行运算,程序的执行性能是否会在此提升:
public static void main(String[] args) throws Exception {AtomicInteger atomicInteger = new AtomicInteger();CountDownLatch countDownLatch = new CountDownLatch(2);long beginTime = System.currentTimeMillis();//模拟并行流采集5000w数据并写入本地文档中new Thread(() -> {IntStream.range(0, 5000_0000).parallel().forEach(i -> atomicInteger.getAndIncrement());countDownLatch.countDown();}, "t1").start();//模拟并行流采集5000w数据并写入本地文档中new Thread(() -> {IntStream.range(0, 5000_0000).parallel().forEach(i -> atomicInteger.getAndIncrement());countDownLatch.countDown();}, "t2").start();//等待两个线程结束countDownLatch.await();//输出耗时long endTime = System.currentTimeMillis();System.out.println("atomicInteger: " + atomicInteger.get());System.out.println("time: " + (endTime - beginTime) + " ms");}
很明显,从最终的耗时来看,执行时间不减反增了,这是为什么呢?
atomicInteger: 100000000
time: 1863 ms
详解多任务采用并行流导致执行低效的原因
实际上并行流底层所采用的线程池是一个在程序启动初始化期间就会创建的线程池common,程序初始化时它会检查用户的是否有配置java.util.concurrent.ForkJoinPool.common.parallelism这个参数,如果有则基于这个参数的数值为common创建定量的线程,后续的我们的并行流运算的执行都会提交到该线程池中。
这就意味着我们上述的操作中,所有线程中千万的执行子项都通过同一个线程池进行并行运算,这期间线程池的忙碌程度可想而知,这也就是为什么笔者在进行压测时明明某些数据量不是很大的任务耗时却非常大的本质原因:
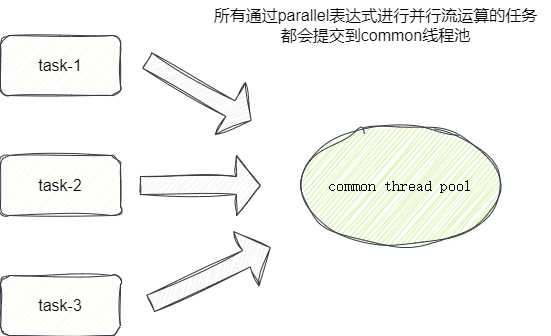
对于该问题,笔者也通过StackOverflow看到并行流设计的思想,设计者认为对于计算密集型任务,默认情况下,它将通过一个初始化一个CPU核心数一致的线程池,让所有并行运算共享一个线程池,进行并行流运算时使用的线程永远在核心数以内,由此也会出现相同的缺点,所有并行运算依赖同一个线程池,可能会导致大量任务大耗时或者大阻塞:
This also means if you have nested parallel streams or multiple parallel streams started concurrently, they will all share the same pool. Advantage: you will never use more than the default (number of available processors). Disadvantage: you may not get “all the processors” assigned to each parallel stream you initiate (if you happen to have more than one). (Apparently you can use a ManagedBlocker to circumvent that.)
这一点我们也可以在ForkJoinPool的静态代码块中
static {// initialize field offsets for CAS etctry {//......//调用makeCommonPool完成线程池创建和初始化common = java.security.AccessController.doPrivileged(new java.security.PrivilegedAction<ForkJoinPool>() {public ForkJoinPool run() { return makeCommonPool(); }});int par = common.config & SMASK; // report 1 even if threads disabledcommonParallelism = par > 0 ? par : 1;}
对应的我们步入makeCommonPool方法即可看到线程池的创建逻辑,即判断用户是否有通过java.util.concurrent.ForkJoinPool.common.parallelism指定线程数,若没有则按照CPU核心数完成初始化:
private static ForkJoinPool makeCommonPool() {//......try { // ignore exceptions in accessing/parsing properties//获取用户对于common线程池中线程数的配置String pp = System.getProperty("java.util.concurrent.ForkJoinPool.common.parallelism");if (pp != null)parallelism = Integer.parseInt(pp);//......} catch (Exception ignore) {}//......//若小于parallelism小于0则说明用户没有指定,则直接按照CPU核心数创建线程池if (parallelism < 0 && // default 1 less than #cores(parallelism = Runtime.getRuntime().availableProcessors() - 1) <= 0)parallelism = 1;//基于CPU核心数创建 ForkJoinPool线程池return new ForkJoinPool(parallelism, factory, handler, LIFO_QUEUE,"ForkJoinPool.commonPool-worker-");}
解决方案
很明显,对于该问题就是因为多个并行运算跑到了单个线程池中,我们的解决方式无非是以下几种:
- 提升线程池线程数量已处理更多的并发运算。
- 业务上避免大量并发运算去竞争
common线程池。
结合业务场景,笔者对于并行流的使用更多是计算密集型任务,通过java.util.concurrent.ForkJoinPool.common.parallelism去提升线程数并不会带来提升,所以在笔者结合业务场景通过压测计算出每个定时任务的耗时,大约是5分钟,所以笔者通过调整定时任务的执行间隔由原来的3min改为5min保证任务错峰执行解决该问题:

小结
我是 sharkchili ,CSDN Java 领域博客专家,开源项目—JavaGuide contributor,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

参考
Custom thread pool in Java 8 parallel stream:https://stackoverflow.com/questions/21163108/custom-thread-pool-in-java-8-parallel-stream
ForkJoinPool的commonPool相关参数配置
:https://www.jianshu.com/p/1b5f4ea0074a
这篇关于为什么使用Java8中的并行流运算耗时变长了?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





