本文主要是介绍32-读取Excel数据(xlrd),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本篇介绍如何使在python中读取excel数据。
一、环境准备
先安装xlrd模块,打开cmd,输入 pip install xlrd 在线安装。

二、基本操作
import xlrd# 打开excel表格
data = xlrd.open_workbook('test.xlsx')# 2.获取sheet表格
# 方式一:通过索引顺序获取
# table = data.sheets()[0] 或 table = data.sheet_by_index(0)
# 方式二:通过名称获取
table = data.sheet_by_name(u'Sheet1')# 3.获取总行数和总列数
nrows = table.nrows
ncols = table.ncols# 4.获取某行或某列的值
print(table.row_values(0)) # 获取第一行值
print(table.col_values(0)) # 获取第一列值三、在excel中存放数据
1)在test.excel中存放数据,第一行为标题。
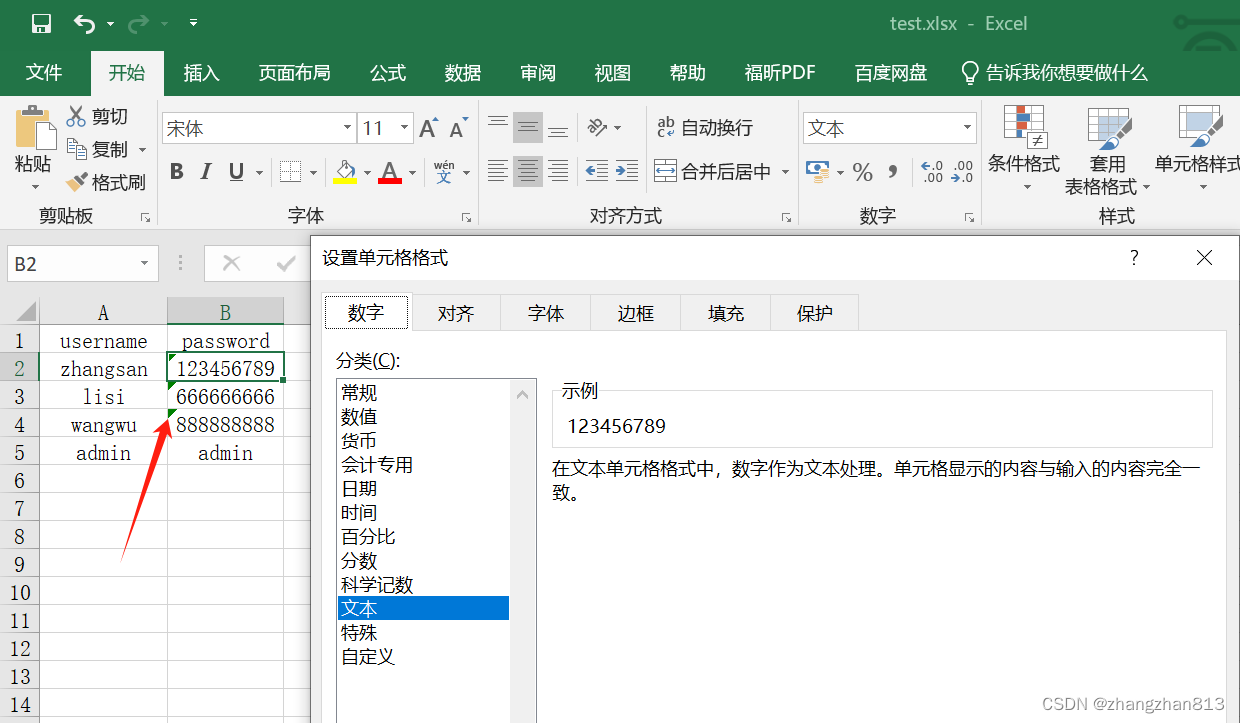
2)如果test.excel中的数据有纯数字,一定要右键 > 设置单元格格式 > 文本格式,不然读取的数据是浮点数。(先设置单元格的格式,然后在单元格中编辑数据,编辑成功单元格的左上角有个小三角图标,如下图红色箭头所示)
四、读取数据
将读取到的数据放在list列表中,列表中的元素是字典类型。
import xlrdclass ExcelUtil():def load_excel(self, excelPath, sheetName):self.data = xlrd.open_workbook(excelPath)self.sheet = self.data.sheet_by_name(sheetName)# 1.获取第一行作为keyself.keys = self.sheet.row_values(0)# 2.获取总行数self.rowNums = self.sheet.nrows# 3.获取总列数self.colNums = self.sheet.ncolsdef get_data(self):res = []j = 1for i in range(self.rowNums - 1):dict = {}values = self.sheet.row_values(j)for idx in range(self.colNums):dict[self.keys[idx]] = values[idx]res.append(dict)j += 1return resif __name__ == '__main__':excelPath = 'test.xlsx'sheetName = 'Sheet1'excelObj = ExcelUtil()excelObj.load_excel(excelPath, sheetName)print(excelObj.get_data())
五、执行报错
在执行上述代码时,报错:xlrd.biffh.XLRDError: Excel xlsx file; not supported。
1)原因分析
在Python中使用xlrd库读取.xlsx文件时报错,无法读取。这是由于当前Python中的xlrd版本过高导致的,高版本只支持.xls文件,删除了对.xlsx文件的读取方法。
2)解决办法
因此,只需要重装xlrd即可,win+R打开cmd,输入下文,即可解决该问题。
pip3 install xlrd==1.2.0六、执行结果
重新安装xlrd后,代码可正常执行。执行结果如下:
[{'username': 'zhangsan', 'password': '123456789'},{'username': 'lisi', 'password': '666666666'},{'username': 'wangwu', 'password': '888888888'},{'username': 'amdin', 'password': 'admin'}]这篇关于32-读取Excel数据(xlrd)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








