本文主要是介绍Redis的缓存击穿、缓存穿透和缓存雪崩是什么?怎么预防?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Redis的缓存击穿、缓存穿透和缓存雪崩是什么?怎么预防?
- 前言
- 缓存击穿
- 定义
- 解决思路
- 实现
- 加锁+设置过期时间+Lua脚本
- 刷新锁
- 缓存穿透
- 定义
- 实现
- 缓存雪崩
- 定义
- 解决思路
- 总结
前言
最近在CSDN上看到了一篇博客,Redis缓存击穿、雪崩、穿透!(超详细),详细讲述了缓存穿透、缓存击穿和缓存雪崩是什么。对我这个刚刚入门的人来说,看完之后非常震撼。

但是这篇博客没有给出具体的实现,并且在浏览大部分博客之后,发现大家在实现的过程中,并不能像这篇博客一样考虑的这么周全。
为此,博主准备基于大佬博客的思想来实现一下,更有效的避免缓存穿透、缓存击穿以及缓存雪崩。
缓存击穿
定义
这里我们首先简单描述一下什么是缓存击穿。
现在我们有一个热点数据,为了提升系统响应速度和可承担的并发量,我们使用Redis存储这个热点数据。
确实很有效,系统的速度和稳定性都提高了。但现在出现了一个问题,就是该热点数据存储在Redis的缓存过期了。
那会出现什么问题呢?
如果恰好在缓存过期的时候,突然涌入了大量请求,这时候因为缓存过期了,所以所有的请求都要访问数据库,从而导致我们的服务负载直接飙升,就有可能直接宕机了,这就是缓存击穿。
解决思路
那怎么避免呢?
我们可以使用大佬博客中提到的加锁的方式,这里简单描述一下,具体内容大家可以看原博客 Redis缓存击穿、雪崩、穿透!(超详细)。
注意哈,这里的锁肯定不是加在单个服务上,肯定要所有服务都能获取到才可以。
这里就可以使用redis的缓存来充当锁的作用了。因为redis的数据,所有服务都可以拿到,所以可以获取同一把锁,这就能保证只有一个服务可以拿到锁!
加锁的过程会出现问题
首先是一个服务加锁之后,服务宕机了怎么办?因为我们使用redis加锁,需要手动释放锁。此时,若加锁的服务宕机了,锁并没有释放,其他所有的请求就要一直等待。
其实就可以对锁设置过期时间,这样即使加锁服务宕机,当过期时间到了,锁也会自动释放。
到这一步,你会发现原来的加锁变成了加锁+设置过期时间两步操作,如果服务还没设置过期时间就宕机了,还是会出现锁一直不释放的问题。
那怎么办呢?
这个时候我们就可以使用Lua保证原子性了,也就是说上面两个过程被认为是一个原子操作,要么都执行,要么都不执行。
接下来是不是就啥都可以了呢?
很明显不是
前面只讨论加锁的服务宕机了怎么办,那么如果没有宕机,只是查询DB的速度比较慢,会不会有问题呢?
答案是会的
此时,若查询DB的时间超过了过期时间,那么锁就释放了,但事实上redis的缓存并没有更新。如果每条请求都出现这样的问题,那DB仍旧要承担较大的负载。
那怎么做呢,我们其实可以加一个线程,用这个线程来做一个延时操作,一旦到时间了redis中还没更新,那就延长锁的过期时间,这样就可以避免其他请求也去查询DB了。
另外还有关于redis集群的问题,详情大家可以看原博客。这里我们只给出单个节点实例的实现代码。
实现
加锁+设置过期时间+Lua脚本
这里我们要加锁和设置过期时间看作一条指令,可以使用Lua脚本。Lua脚本可以保证多条指令作为一个整体执行,从而避免了加锁但没有设置过期时间这样的问题。
Lua脚本
local key = ARGV[1]
local value = ARGV[2]
local addR = redis.call('set', key, value,'NX')
local expireR = redis.call('expire', key, 5000)
if addR and expireR thenreturn true
elsereturn false
end后来发现好像有自带的原子操作,行吧
local lock = redis.call('set', key, value, 'NX', 'PX', 5000)

那么怎么在Springboot里指向这个Lua脚本呢,首先我们要把这个脚本放在这个文件夹里

然后加锁和解锁代码如下
static DefaultRedisScript<Boolean> SECKILL_SCRIPT;static {SECKILL_SCRIPT = new DefaultRedisScript<>();//在resources目录下导入我们的脚本文件SECKILL_SCRIPT.setLocation(new ClassPathResource("lua/ntx.lua"));SECKILL_SCRIPT.setResultType(Boolean.class);}/*** 设置分布式锁*/public boolean tryLock(String key) {// 使用lua脚本保证原子性Boolean execute = (Boolean) redisTemplate.execute(SECKILL_SCRIPT,//这里就是我们上面静态代码块引入的脚步Collections.emptyList(),//这里要传key类型的参数,因为我上面写入redis缓存的key是用下面的第三部分参数args来拼出来的,//所以脚本是不需要key的,所以这里用方法传一个空集合,注意不要传nullkey.toString(), "1".toString());return BooleanUtil.isTrue(execute);}/*** 解锁** @param key*/public void unlock(String key) {try{redisTemplate.delete(key);}catch (Exception e){log.error("删除失败");}}
刷新锁
这里我们设置一个延时线程去做就可以
public class ThreadUtils {// 设置延时任务线程public static void prolongTime(RedisTemplate redisTemplate, String key, int ttl) {new Thread(() -> {Time.sleep(4000);if (redisTemplate.hasKey(key)) {redisTemplate.expire(key, ttl, TimeUnit.SECONDS);// 重置过期时间后别忘记在设置一个延时任务prolongTime(redisTemplate, key, ttl);}System.out.println("已成功更新redis,防止缓存击穿!");}).start();}
}
然后在获取锁之后,直接启动该线程,这里我们设置的等待时间相比于过期时间较短一些,是因为加锁和开启线程之间就有延迟,并且还有可能到时间并没有给延时线程分配时间片,因此设置的较短一点。
分布式的问题这里就不实现了。
缓存穿透
定义
缓存穿透类似击穿,区别在于击穿是数据库中有数据,而穿透是数据库中没有该数据。
什么场景会出现这种问题呢?
像是恶意攻击时会出现该问题,因为数据库中并没有该数据,并不会添加缓存,这就会导致每次查询都会访问DB,我们的Redis层就没用了,系统便无法承受原有的并发量。
现有的一种方法是设置null值。但是这些null值都是多余的数据,会占用大量的空间。
但现在合适的方法就是存储这些无效的key,那怎么能减少存储key所需容量呢?
这就要提到hash了,通过hash我们可以将一个复杂的字符串映射到某个bit上,这是最小的单位了。
因此我们可以使用bit存储这些关系。
但是有一个问题,hash表会出现碰撞现象,也就是说,不存在的值在映射之后可能和存在的值放在一个位置。但是我们不能像HashMap那样做一个拉链,因为bit只能存储是否存在,并不能存储其他关系了。
没有完美的方法。我们不能保证百分百正确,但可以尽量减轻这种问题。
我们可以想到hash表的升级版,布隆过滤器。
他与hash表的不同在于用多个hash函数去映射,这样一个key就对应多个bit。测试时,需要判断key的多个bit是否都为1,这样才能判断一个key是否存在,就可以减少误判率了。
因此,我们可以使用布隆过滤器存储我们已有的内容,然后在请求时,如果过滤器判断key不存在,直接返回,否则进行查询。
这是因为布隆过滤器的一个特点就是判断存在,key不一定存在,判断不存在,key一定不存在。
基于这种特性,判断不存在的,我们直接返回空就可以了,就不会访问DB,这可以帮我们过滤掉大量无效请求。
实现
首先引入依赖
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>31.0.1-jre</version>
</dependency>
布隆过滤器
这里我们直接向IOC容器中注入一个自定义的布隆过滤器,如下所示。
package com.xiaow.movie.vo;import com.google.common.hash.BloomFilter;
import com.xiaow.movie.service.VideoService;
import com.xiaow.movie.vo.aware.VideoBloomFilterAware;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;import java.util.List;/*** @ClassName VideoBloomFilter* @Author xiaow* @DATE 2024/6/10 17:39**/
@Component
public class VideoBloomFilter implements VideoBloomFilterAware {@AutowiredVideoService videoService;private BloomFilter<Long> filter;@Overridepublic void setFilter(BloomFilter filter) {this.filter=filter;}public void initFilter() {// 将数据库中id导入到布隆过滤器中List<Integer> ids = videoService.getIds();for (Integer id : ids) {this.filter.put(Long.valueOf(id));}}public void addValue(Long id) {// 加入新的内容this.filter.put(id);}public Boolean exist(Long id) {// 判断是否存在return this.filter.mightContain(id);}
}但是有小伙伴可能注意到了为什么要继承一个VideoBloomFilterAware?
这里因为我们用到了VideoService ,是IOC容器管理的。我们最开始是在构造方法里直接使用VideoService提取videoid,但是发现空指针。
这是为啥呢?
Bean对象的生命周期如下图所示
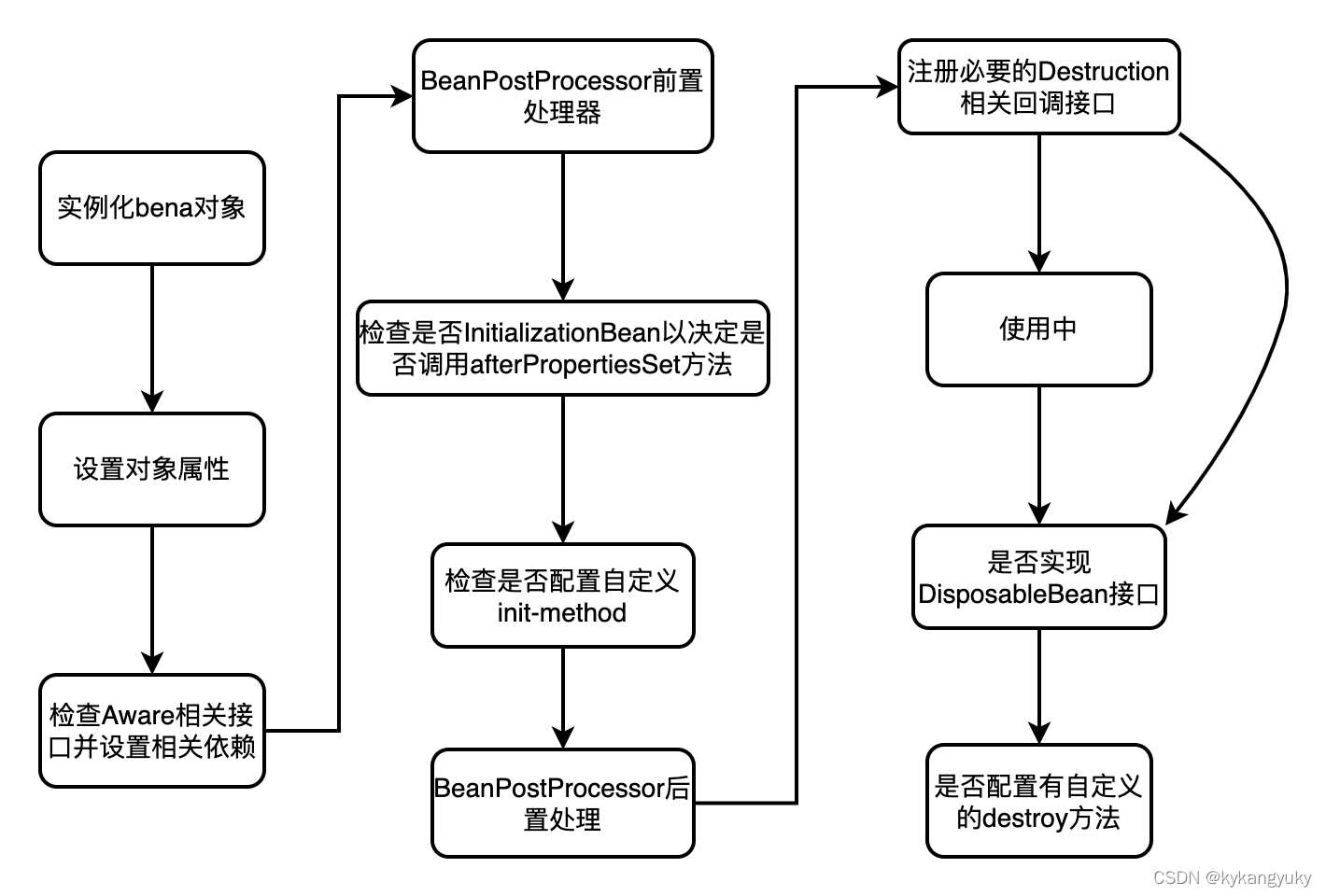
可以看到哈,实例化的时候会调用构造方法,但是此时并没有对对象属性进行赋值,这就导致了我们VideoService仍为空,因此我们在BeanPostProcessor阶段使用VideoService注入id到布隆过滤器中。
Aware和BeanPostProcessor的代码如下
public interface VideoBloomFilterAware extends Aware {void setFilter(BloomFilter filter);void initFilter();
}@Component
public class VideoBloomFilterPostProcessor implements BeanPostProcessor {
// 预计填充数量Long capacity = 10000L;// 错误比率double errorRate = 0.01;@Overridepublic Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {if(bean instanceof VideoBloomFilterAware){BloomFilter<Long> longBloomFilter = BloomFilter.create(Funnels.longFunnel(), capacity, errorRate);((VideoBloomFilterAware) bean).setFilter(longBloomFilter);((VideoBloomFilterAware) bean).initFilter();}return bean;}
}
到现在为止,布隆过滤器已经初始化好了,我们只需要在接口里判断一下就可以了
Boolean exist = videoBloomFilter.exist(Long.valueOf(id));if (exist)// 存在则进行查询return Result.succ(videoService.getOneMutex(id));else// 不存在,直接返回return Result.fail("没有该视频");
缓存雪崩
定义
Redis中大量缓存失效,此时又涌入了大量请求,此时所有请求同时访问DB,导致数据库负载过高。
这其实可以认为是缓存击穿的一种特殊情况。
解决思路
这个比较简单,大家设置key的时间在一个范围内,不要是统一的,就可以有效避免缓存雪崩的问题,或则可以在查询时做一个随时的延时,这样也可以避免大量请求同时访问DB。
总结
根据大佬的博客思路,写了一些实现,欢迎大家进行指正。

这篇关于Redis的缓存击穿、缓存穿透和缓存雪崩是什么?怎么预防?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









