本文主要是介绍浅解Reids持久化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Reids持久化
RDB
redis的存储方式:
rdb文件都是二进制,很小,里面存的是数据
实现方式
redis-cli链接到redis服务端
使用save命令
注:不推荐 因为save命令是直接写到磁盘里面,速度特别慢,一般都是redis快要关机的时候使用这个命令
使用bgsave 后台保存异步执行
在配置文件里面配置:
save 900 1 #900秒内至少有一次修改 就执行bgsave
save 300 10
save “” #禁用rdb 默认开启
说明:
rdb有自己的压缩 不建议开启 因为会消耗很多cpu资源 多占点磁盘空间 没关系的
dump.db是rab数据保存的文件
实现原理:
fork一个子进程在后台执行
AOF
实现原理:
每次都记录写命令,逐渐累加,很像一个写操作的日志文件
实现方式:
配置文件手动开启,可以设置文件名字,可以设置执行频率(默认是先写到缓冲区,然后每一秒把所有的缓冲区写到aof文件)
区别:
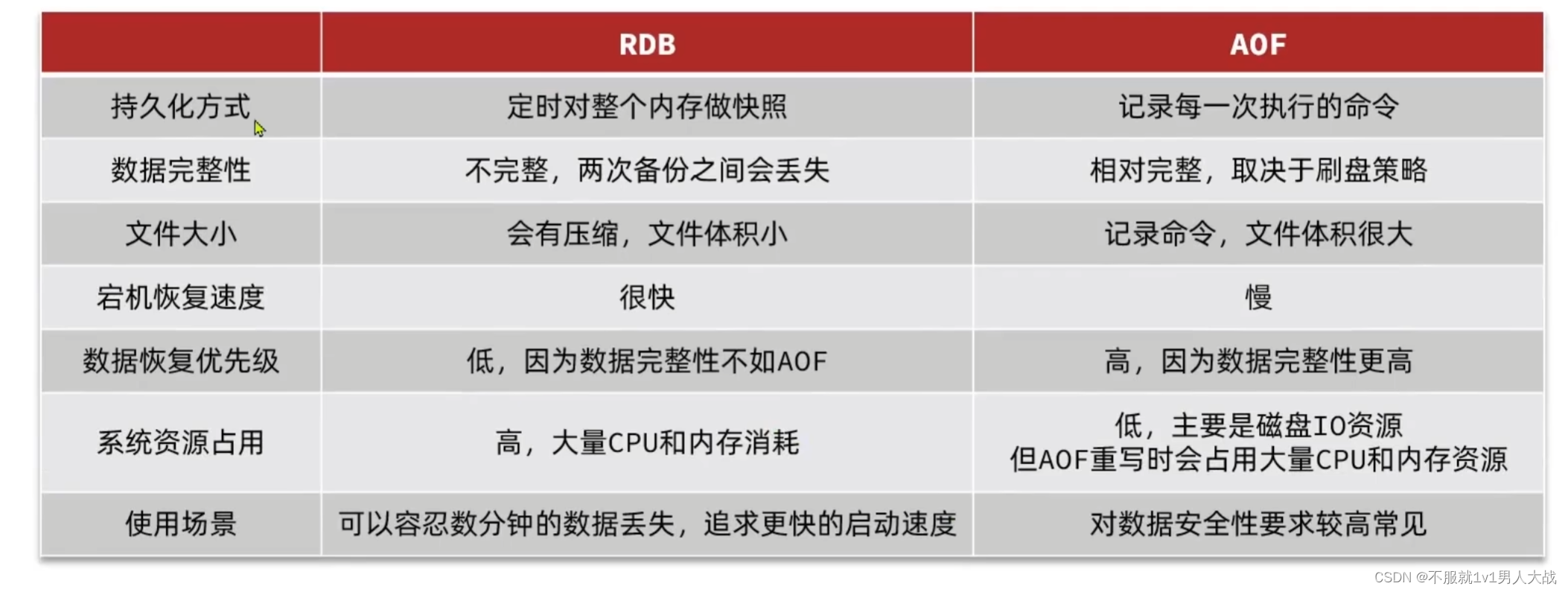
rdb:主要用于数据备份(主要用于故障恢复),aof主要用于持久化
这篇关于浅解Reids持久化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









