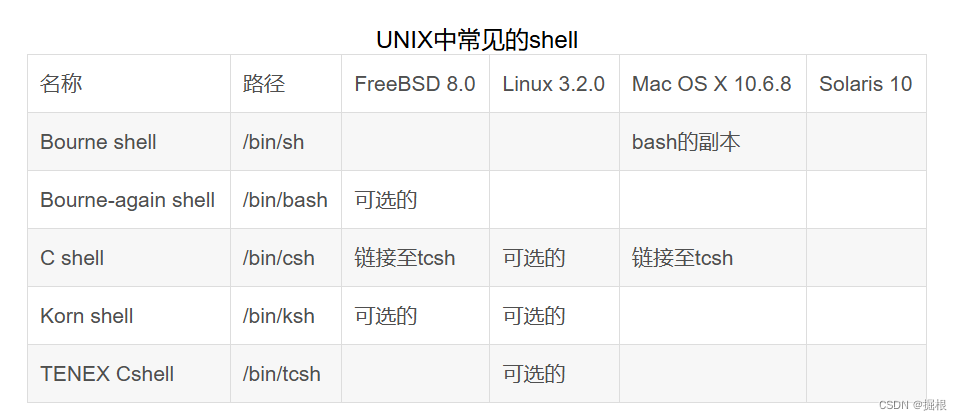
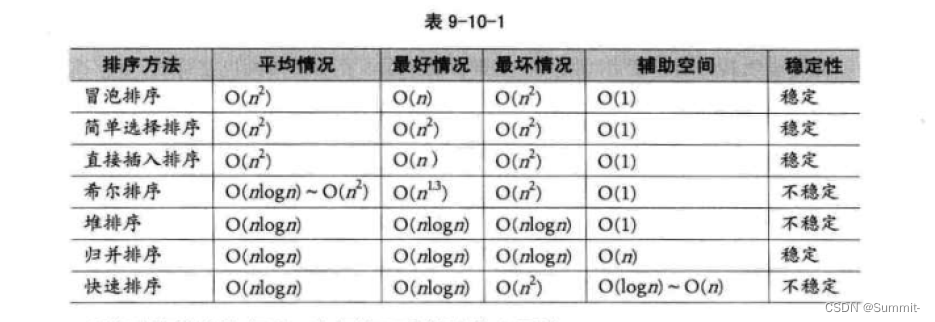
本文主要是介绍希尔排序(Shell_sort),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
希尔排序常用于插入排序的数据预处理,用于提升插入排序的大数据处理速度
将插入排序的函数改为n递增即可使用希尔排序
间隔为n的插入排序:
将i初始值改为1,然后j循环所有的1改为n即可
void Insertion_sort(int *arr,int size,int n)
{int i,j;for(i = 0;i < size;++i)//第一个元素不用排序{int t = arr[i];for(j = i-n;j >= 0 && arr[j] > t;j-=n){arr[j+n] = arr[j];//直接覆盖,速度更快(将前一个覆盖到后面)}arr[j+n] = t;//因为是覆盖,所以要最后赋值}
}如
10
3 1 2 8 7 5 9 4 6 0先以5为间隔
排序为
0 1 2 4 3 5 8 6 9 7然后以2为间隔
0 1 2 4 3 5 8 6 9 7最后以1为间隔
0 1 2 3 4 5 6 7 8 9希尔排序虽然看着多了跟多步,但是在大数据的情况下要比单纯的插入排序快上不少
c++代码如下:
#include <bits/stdc++.h>using namespace std;void print_arr(int *arr,int size)
{for(int i = 0;i < size;++i){cout << arr[i];if(i != size-1){cout << " ";}}
}void Insertion_sort(int *arr,int size,int n)
{int i,j;for(i = 0;i < size;++i)//第一个元素不用排序{int t = arr[i];for(j = i-n;j >= 0 && arr[j] > t;j-=n){arr[j+n] = arr[j];//直接覆盖,速度更快(将前一个覆盖到后面)}arr[j+n] = t;//因为是覆盖,所以要最后赋值}
}void Shell_sort(int *a,int length)
{int n = length/2;while(n >= 1){Insertion_sort(a,length,n);n /= 2;}
}int main()
{int n;cin >> n;int arr[n];for(int i = 0;i < n;++i){cin >> arr[i];}Shell_sort(arr,n);print_arr(arr,n);cout << endl;
}这篇关于希尔排序(Shell_sort)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!