本文主要是介绍Redis 双写一致原理篇,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
我们都知道,redis一般的作用是顶在mysql前面做一个"带刀侍卫"的角色,可以缓解mysql的服务压力,但是我们如何保证数据库的数据和redis缓存中的数据的双写一致呢,我们这里先说一遍流程,然后以流程为切入点来谈谈redis和mysql的双写一致性是如何保证的吧
流程
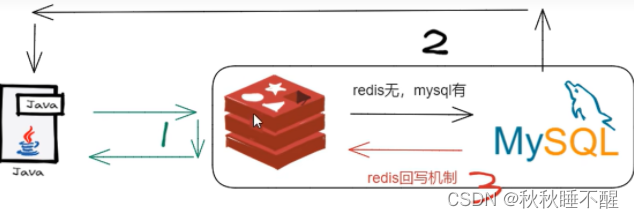
首先我们先看一个图
这就是进行一次查询的基本流程
第一步就是查询redis看看是否有对应的热点数据,没有的话,就去mysql进行查询
mysql查询到了再进行回写进redis,这样下一个用户来进行查询的时候,这里就可以直接从redis进行查询对应的数据了
但是这里就会涉及到很多问题了,如何保证双写一致性??
我更新数据的更新策略是先更新mysql还是先更新redis??
下面我们慢慢说
缓存双写一致性的理解
这里查询如过redis有数据那么就进行立即返回
如果redis没有数据那么就打到mysql中查看数据并进行回写
这里的缓存我们可以分为两种
只读缓存和可写缓存
可写缓存这里我们也分为两种写入策略
同步直写策略和异步缓写策略
同步直写策略就是读取完mysql的数据迅速进行一个回写操作
如果这里想保存数据的高度一致,就最好是使用同步缓写的操作
比如这个时候我们想把一个vip的状态进行快速的切换,充值成功立马就得更新
异步缓写策略就是我们一个物流状态的更新,或者是订单成功的积分操作都可以使用一个异步的操作,因为这个操作是非即时性质的
但是这里也可能导致很多错误
比如假设这里回写失败了咋办
我们可以使用一个消息队列等来进行对应的补偿重试机制
假设高并发的情况下出现了对应的数据进行覆盖
或者可能出现mysql死锁mysql负载过高的情况
这里我们就可以使用双检加锁策略解决问题
这里主要是为了保证每次只有一个请求打在mysql上,减少mysql服务器的负载
至于后面的值覆盖问题一会儿再说
我们展示一段代码再进行对应的讲解
@Service @Slf4j public class UserService {public static final String CACHE_KEY_USER = "user:";@Resourceprivate UserMapper userMapper;@Resourceprivate RedisTemplate redisTemplate;/*** 业务逻辑没有写错,对于小厂中厂(QPS《=1000)可以使用,但是大厂不行* @param id* @return*/public User findUserById(Integer id){User user = null;String key = CACHE_KEY_USER+id;//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysqluser = (User) redisTemplate.opsForValue().get(key);if(user == null){//2 redis里面无,继续查询mysqluser = userMapper.selectByPrimaryKey(id);if(user == null){//3.1 redis+mysql 都无数据//你具体细化,防止多次穿透,我们业务规定,记录下导致穿透的这个key回写redisreturn user;}else{//3.2 mysql有,需要将数据写回redis,保证下一次的缓存命中率redisTemplate.opsForValue().set(key,user);}}return user;}这段代码对于并发量低的情况下还是可以使用的
但是假设这里redis的数据同一时间有很多用户访问,但是redis没有,得去mysql的底单数据表去查询,这里我们就得考虑万一都打在mysql上,导致mysql的压力过大就不好了,所以我们建议加锁,每次只让一个线程去操作对应的用户即可
这里代码示例可以在mysql操作加上一个互斥锁
注意这里我们检查了两次,这是因为假设a线程和b线程都查询到redis没有这个数据,但是此时a线程被调度走了,b线程已经将数据带回来了,此时再调度到a线程a线程直接查询redis即可,避免给mysql更大的压力,下面我们展示加锁后的代码
/*** 加强补充,避免突然key失效了,打爆mysql,做一下预防,尽量不出现击穿的情况。* @param id* @return*/public User findUserById2(Integer id){User user = null;String key = CACHE_KEY_USER+id;//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql,// 第1次查询redis,加锁前user = (User) redisTemplate.opsForValue().get(key);if(user == null) {//2 大厂用,对于高QPS的优化,进来就先加锁,保证一个请求操作,让外面的redis等待一下,避免击穿mysqlsynchronized (UserService.class){//第2次查询redis,加锁后user = (User) redisTemplate.opsForValue().get(key);//3 二次查redis还是null,可以去查mysql了(mysql默认有数据)if (user == null) {//4 查询mysql拿数据(mysql默认有数据)user = userMapper.selectByPrimaryKey(id);if (user == null) {return null;}else{//5 mysql里面有数据的,需要回写redis,完成数据一致性的同步工作redisTemplate.opsForValue().setIfAbsent(key,user,7L,TimeUnit.DAYS);}}}}return user;}}
更新策略
我们知道mysql和redis的数据得保证一致性,但是这个强一致性是不太好保证的,我们只能保证最终一致性,那么mysql和redis我们先保证谁的数据更新呢,就是我们接下来要探讨的问题了
注:这里的策略仅供参考,以实际需求为准
策略1:停机更新
首先第一个策略不是很常用但是很有效,直接在用户量较少的时候停机进行服务降级更新
此时让运维工程师使用单线程来操作即可,因为多线程出错的概率更大
策略2:先更新数据库,再更新redis
先更新数据库再更新redis可能导致一些异常,举例如下
假设现在更新mysql成功了,但是redis回写却失败了
这里就很可能导致数据库和缓存中的数据就不一致了
策略3:先更新redis,再更新数据库
这也是存在和以上差不多的情况的
技术上可以做,但是不太推荐,因为我们一般是将mysql作为一个底单数据库的
这里异常情况下数据同样是不一致的
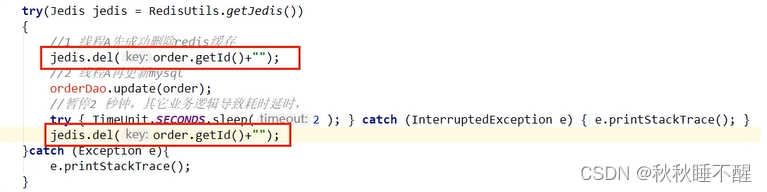
策略4:先删除缓存,再更新数据库
这也不太行假设先删除redis的数据,而mysql还没更新完成
这个时候有一个线程来读取缓存的数据没找到,读取mysql就可能导致了脏读问题,
然后将对应的脏数据回写进了redis,此时mysql更新完了发现缓存中已经有数据了
这里就引入一种延时双删的策略
我们非常悲观的以为一定会有这么一个线程读取脏数据
所以我们在mysql更新结束之后我们对redis在进行一次删除的操作
但是这里延迟的时间不一定好确定,一般是写数据在业务耗时加上100ms即可
还有就是使用后台监控的策略(咱们后面再说)
策略5:先更新数据库再删除缓存
最后一个策略就是较为折中的策略,我们选择先更新数据库再删除缓存
这里的缺点是假设a线程没有更新完mysql并且删除缓存之前就有另外的线程读取对应的数据
这里可能就导致读到了缓存里面的旧值
这里也是有一些成熟的解决方案的
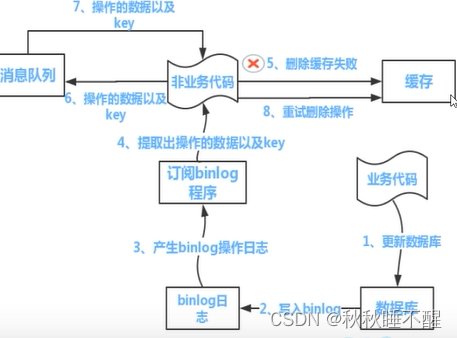
下面我们介绍一下流程
比如使用阿里的canal
其实也就是在更新完数据库之后,写入mysql的binlog日志文件中
订阅程序或者是消息中间价提取出对应的key
然后另起一段非业务代码来获取这里的信息
尝试删除缓存,删除失败的话就将这里的数据发送给消息队列
然后重新重消息队列中获取数据重新复写缓存
流程图如下
我们其实就是做不到强一致性,所以我们之只能采取最终一致性的方案
这也就导致了充值话费或者是短信有一定的滞后性
小总结
我们大多数情况下都是先更新数据库,再删除缓存
这是因为先删除缓存能保证每次获取数据的时候是直接访问数据库,可能导致数据库负载过高
其次就是即时使用延时双删的操作,这里可能延时的时间也不好计算等等



这篇关于Redis 双写一致原理篇的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







