本文主要是介绍计算机网络:数据链路层 - 扩展的以太网,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
计算机网络:数据链路层 - 扩展的以太网
- 集线器
- 交换机
- 自学习算法
- 单点故障
集线器
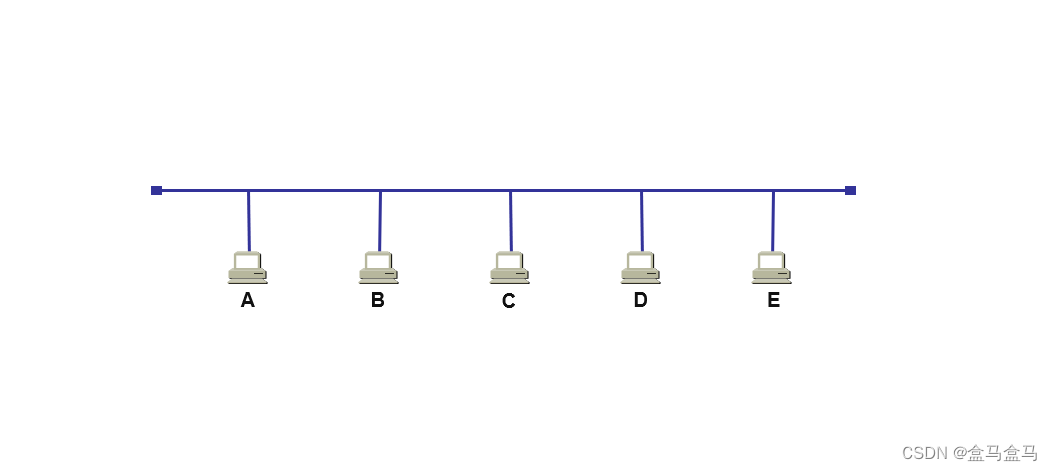
这是以前常见的总线型以太网,他最初使用粗铜轴电缆作为传输媒体,后来演进到使用价格相对便宜的细铜轴电缆。
后来,以太网发展出来了一种使用大规模集成电路,可靠性非常高的设备,叫做集线器,并且使用更便宜、更灵活的双绞线作为传输媒体。如图所示:

这是一个使用集线器和互联了四台主机的新型拓普的以太网,主机中的以太网卡以及集线器各接口之间通过双绞线电缆进行连接。
集线器上的各站共享逻辑上的总线资源,由于各个主机发送的信号依然存在碰撞的情况,所以使用的还是 CSMA/CD 协议来避免碰撞。
集线器只工作在物理层,它的每个接口仅简单的转发,不进行碰撞检测。碰撞检测的任务由各站的网卡负责。我们可将集线器简单看作是一条总线,但是相比于总线,集线器一般都有少量的容错能力和网络管理功能,例如若网络中某个网卡出现了故障,不停的发送帧,此时集线器也可以检测到这个问题。在内部断开与出故障网卡的连线,使整个以太网仍然能正常工作。-
使用集线器可以对以太网进行扩展。由于集线器只工作在物理层,所以更具体的说法是使用集线器在物理层扩展以太网。我们来举例说明:
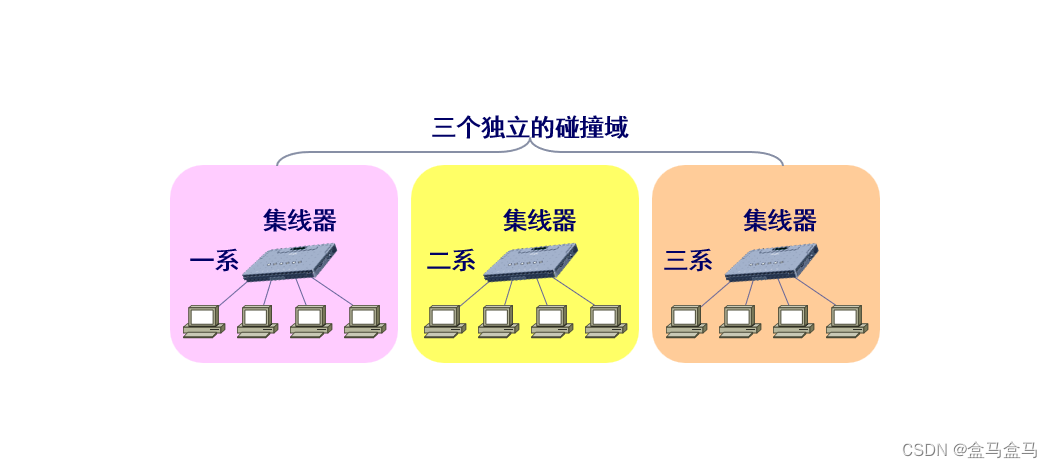
这三个以太网相互独立,各自共享自己的总线资源,是三个独立的碰撞域或冲突域,就是说这个域内部的主机有可能会发生相互碰撞。
但是这三个系之间,目前是不能进行通信的。
为了使各系的以太网能够相互通信,可再使用一个集线器将它们互联起来:
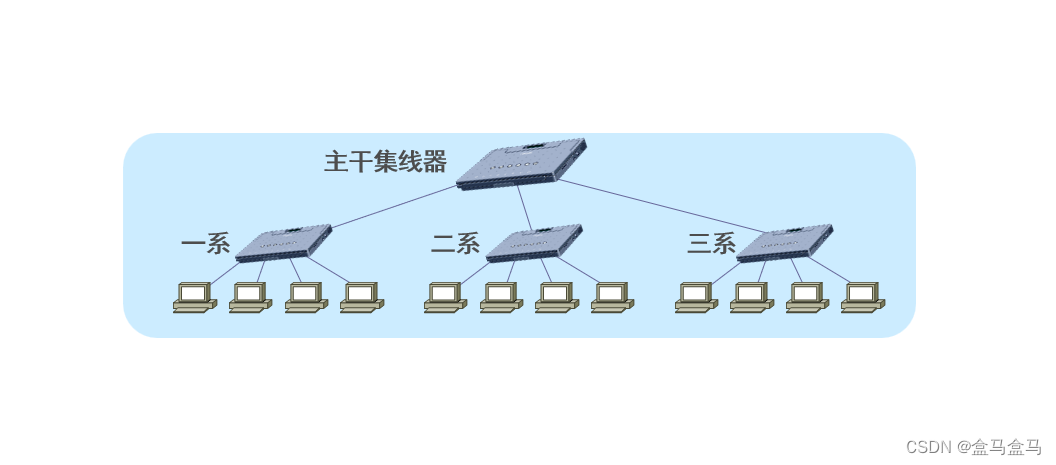
这样原来三个独立的以太网就互联成为了一个更大的以太网。
但是原来三个独立的碰撞域就合并成了一个更大的碰撞域。例如一系中的某台主机给 二系 中的某台主机发送数据帧。由于总线特性,该数据帧的信号会传输到整个网络中的一系,二系,三系的所有主机。
因此通过集线器来合并以太网的方式并不优秀,其虽然可以扩大以太网的覆盖范围,但是存在以下几个缺点:
- 碰撞域变大后,一个域中主机变多,数据发生碰撞的概率变大了
- 所有主机都共享该网络的带宽,扩展后整个网络的总带宽不变,被更多主机瓜分后,每个主机的带宽都减小了
- 集线器要求每个主机的数据率相同,不能兼容多种数据率的主机
在集线器之后发展出了更先进的网络互联设备,也就是以太网交换机。
交换机

交换机的每一个接口都是一个独立的碰撞域
为什么交换机可以做到隔离碰撞域呢?集线器在逻辑上可以看做一个总线,各个连接在集线器上的主机不受约束的发送消息,通过CSMA/CD协议来保证可靠传输,集线器上的任意两台主机之间都有可能会发生碰撞。
而交换机不一样,当交换机收到消息后,会根据MAC地址进行有针对性的转发,而不是粗暴的向所有端口转发,因此可以避免碰撞。
要注意的是:交换机会隔离碰撞域,但不会隔离广播域。
以太网交换机通常都有多个接口,每个接口都可以通过双绞线电缆与一台主机或另一个以太网交换机相连。一般都工作为全双工,也就是发送帧和接收帧可以同时进行。以太网交换机具有并行性能,同时连通多对接口,使多对主机能同时通信而无碰撞。
以太网交换机的接口一般都支持多种速率,例如 10 兆比特每秒、 100 兆比特每秒、 1G 比特每秒、实际比特每秒等。
以太网交换机工作在数据链路层,当然也包括物理层。收到帧后,在帧交换表中查找帧的目的 MAC 地址所对应的接口号,然后通过该接口转发帧。
那么交换机是如如何进行有针对性的消息转发的?这就涉及到交换机的核心算法:自学习算法。
自学习算法
在交换机中,会维护一张交换表,这个交换表存储了MAC地址与接口的映射关系,这样交换机就知道一个帧要往哪一个接口转发。
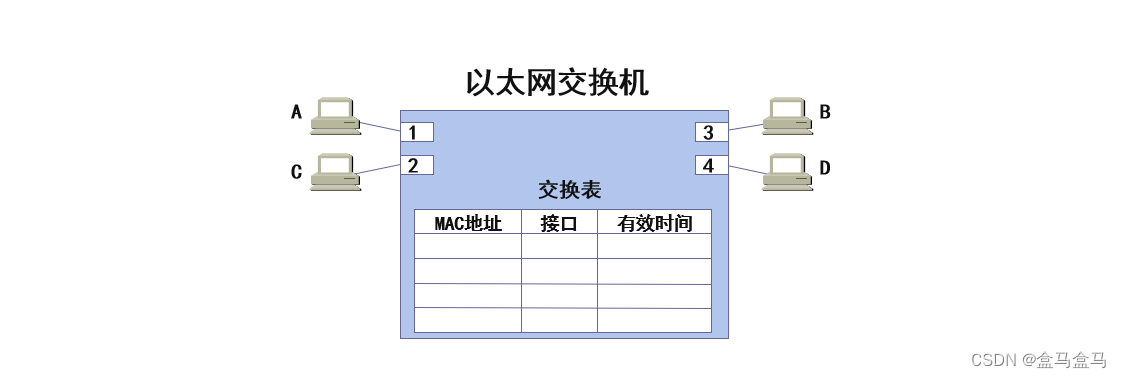
另外的,交换机还会额外维护一个有效时间,当交换表的某个条目超过有效时间,就会被从交换表中删除。
当交换机收到一个帧时,其会进行两个过程:自学习与转发。
自学习:
读取帧的
源地址,在交换表中查找该地址
- 如果交换表中原先存在该地址,更新该地址的
接口与有效时间条目- 如果交换表中原先不存在该地址,插入一个新的项目,并填入对应的
地址,接口,有效时间
转发:
读取帧的
目的地址,在交换表中查找该地址
- 如果没有,向除了帧进入的接口以外的所有接口转发该帧
- 如果有,判断该接口与进入的接口是否一致:如果一致,就丢掉这个帧,如果不一致,向该接口转发
接下来我们用一个案例帮助大家理解,现在我们尝试完成以下表格。
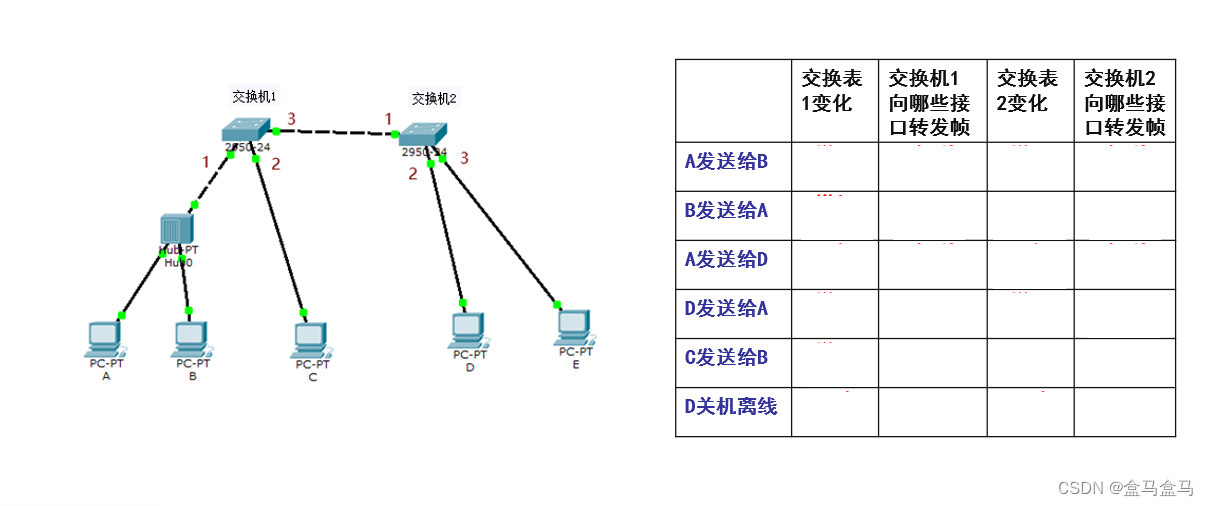
最初整个表是空的。
一开始A给B发送帧,一开始A发送的帧被传送到集线器,集线器收到帧后,只是粗暴的向除A外的所有接口转发,于是交换机1和B都会收到这个帧,B就可以收到A发送的数据了。但是这还没完,因为交换机1还要处理数据:
交换机1收到帧后,先进行自学习:帧的源地址为A的MAC地址,查找转发表后,发现没有A的地址,于是增加条目:
交换机1的转发表如下:
| MAC地址 | 接口 | 有效时间 |
|---|---|---|
| A的MAC地址 | 1 | 10 min |
在此我们假设有效时间默认为10 min,因为这个帧是从接口1传入的,所以转发表中的接口条目填入1。
自学习完成后,就要进行转发:
查找目的地址B的MAC地址,发现转发表中没有该地址,于是向接口1以外的所有接口转发,因为帧是从接口1进来的,所以不会向接口1再发送。
处于接口2的主机C收到帧后,发现帧的目的地址不是自己的,把它丢掉。处于接口3的交换机2收到该帧后,又要进行自学习和转发两个过程:
自学习:帧的源地址为A的MAC地址,查找转发表后,发现没有A的地址,该帧是从交换机2的接口1进入的,于是增加条目。
交换机2的转发表如下:
| MAC地址 | 接口 | 有效时间 |
|---|---|---|
| A的MAC地址 | 1 | 10 min |
随后再进行转发:查找目的地址B的MAC地址,发现转发表中没有该地址,于是向接口1以外的所有接口转发。主机C和D收到该帧后,发现目的地址不是自己,丢弃。
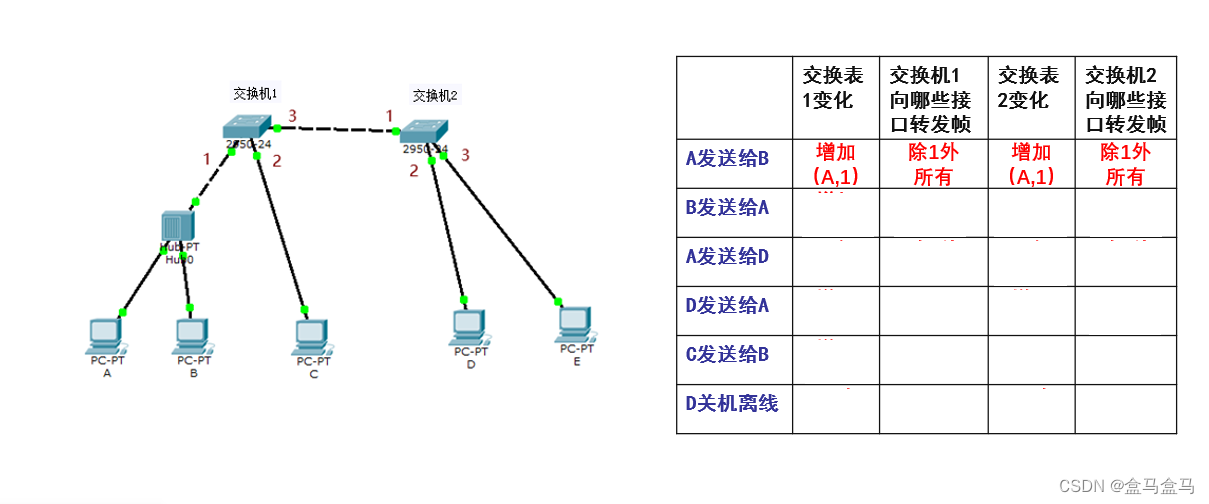
随后B再向A发送数据,由于A和B被连在同一个集线器中,此时A直接就通过集线器收到B的帧了,完成了传输。但是交换机1也会收到这个帧,此时要进行自学习和转发:
交换机1收到帧后,先进行自学习:帧的源地址为B的MAC地址,从接口1进入的交换机1,查找转发表后,发现没有B的地址,于是增加条目。
交换机1的转发表如下:
| MAC地址 | 接口 | 有效时间 |
|---|---|---|
| A的MAC地址 | 1 | 10 min |
| B的MAC地址 | 1 | 10 min |
随后进行转发:
查找目的地址A的MAC地址,发现转发表中有该地址,A处于接口1,而该帧就是从接口1进入的,所以交换机会直接丢弃这个帧,不会再进行转发了。
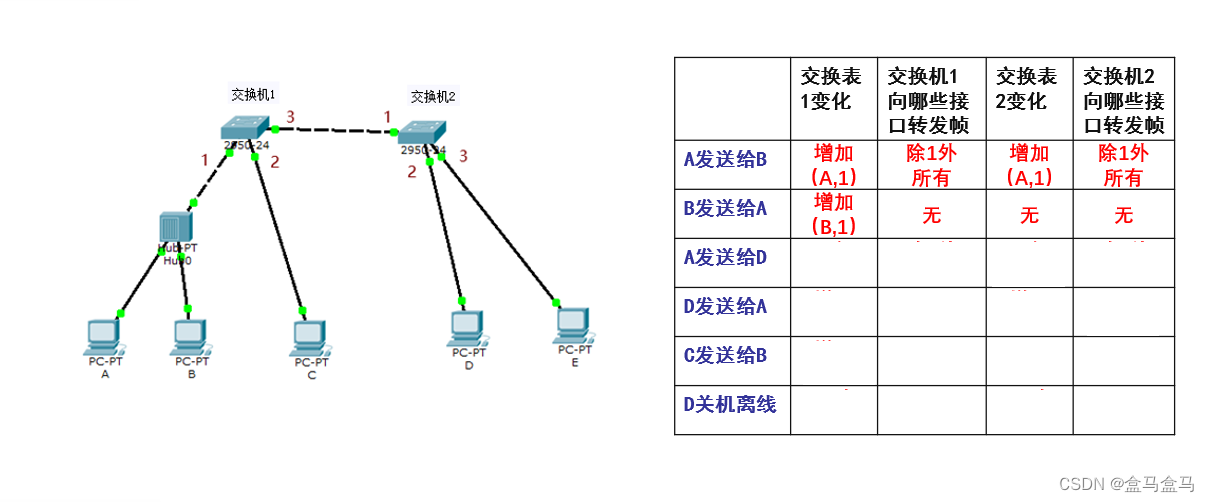
随后A再向D发送数据,交换机1会收到这个帧,此时要进行自学习和转发:
交换机1收到帧后,先进行自学习:帧的源地址为A的MAC地址,从接口1进入的交换机1,查找转发表后,发现有A的地址,于是进行更新接口和有效时间,以确保数据是最新的。
交换机1的转发表如下:
| MAC地址 | 接口 | 有效时间 |
|---|---|---|
| A的MAC地址 | 1 | 10 min |
| B的MAC地址 | 1 | 10 min |
上表中,A的接口和有效时间都更新了,只是和更新前没有区别而已(假设以上所有的发送过程执行的很快,所以有效时间没有变)。
随后进行转发:
查找目的地址D的MAC地址,发现转发表中没有该地址,于是向接口1以外的所有接口转发。
处于接口2的主机C收到帧后,发现帧的目的地址不是自己的,把它丢掉。处于接口3的交换机2收到该帧后,又要进行自学习和转发两个过程:
自学习:帧的源地址为A的MAC地址,查找转发表后,发现有A的地址,该帧是从交换机2的接口1进入的,于是更新条目。
交换机2的转发表如下:
| MAC地址 | 接口 | 有效时间 |
|---|---|---|
| A的MAC地址 | 1 | 10 min |
随后再进行转发:查找目的地址D的MAC地址,发现转发表中没有该地址,于是向接口1以外的所有接口转发。主机C收到该帧后,发现目的地址不是自己,丢弃。主机D收到该帧后,发现目的地址是自己,于是接收该帧,完成消息传送。
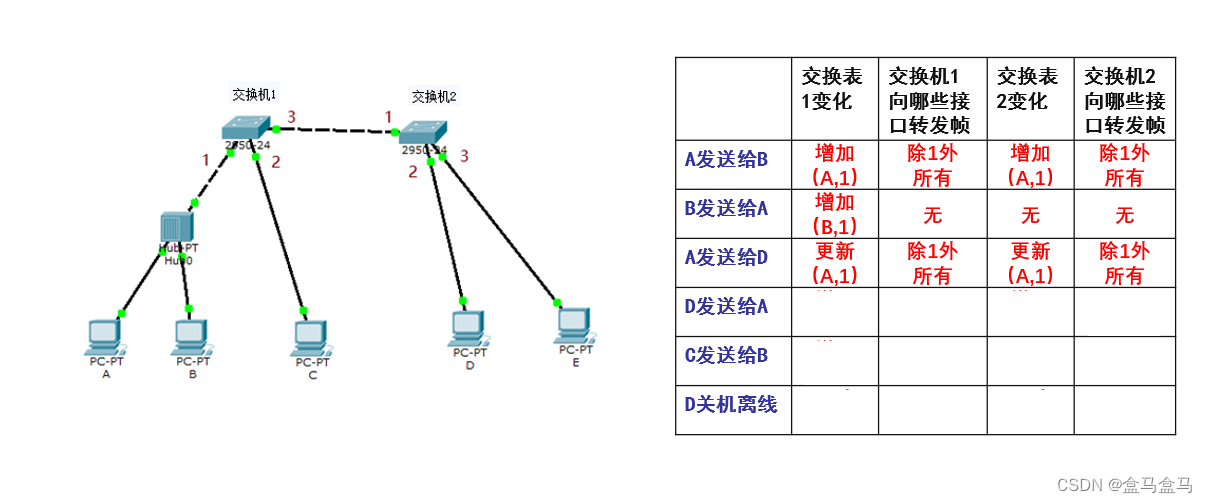
随后D再向A发送数据,交换机2会收到这个帧,此时要进行自学习和转发:
交换机2收到帧后,先进行自学习:帧的源地址为D的MAC地址,从接口3进入的交换机2,查找转发表后,发现没有D的地址,于是增加条目。
交换机2的转发表如下:
| MAC地址 | 接口 | 有效时间 |
|---|---|---|
| A的MAC地址 | 1 | 10 min |
| D的MAC地址 | 3 | 10 min |
随后进行转发:
查找目的地址A的MAC地址,发现转发表中有该地址,于是向接口1转发。
处于接口1的交换机1收到该帧后,又要进行自学习和转发两个过程:
自学习:帧的源地址为D的MAC地址,查找转发表后,发现没有D的地址,该帧是从交换机1的接口3进入的,于是增加条目。
交换机1的转发表如下:
| MAC地址 | 接口 | 有效时间 |
|---|---|---|
| A的MAC地址 | 1 | 10 min |
| B的MAC地址 | 1 | 10 min |
| D的MAC地址 | 3 | 10 min |
随后再进行转发:查找目的地址A的MAC地址,发现转发表中有该地址,于是向接口1转发。主机B收到该帧后,发现目的地址不是自己,丢弃。主机A收到该帧后,发现目的地址是自己,于是接收该帧,完成消息传送。

随后C再向B发送数据,交换机1会收到这个帧,此时要进行自学习和转发:
交换机1收到帧后,先进行自学习:帧的源地址为C的MAC地址,从接口2进入的交换机1,查找转发表后,发现没有C的地址,于是增加条目。
交换机1的转发表如下:
| MAC地址 | 接口 | 有效时间 |
|---|---|---|
| A的MAC地址 | 1 | 10 min |
| B的MAC地址 | 1 | 10 min |
| D的MAC地址 | 3 | 10 min |
| C的MAC地址 | 2 | 10 min |
随后进行转发:
查找目的地址B的MAC地址,发现转发表中有该地址,于是向接口1转发。主机A收到该帧后,发现目的地址不是自己,丢弃。主机B收到该帧后,发现目的地址是自己,于是接收该帧,完成消息传送。
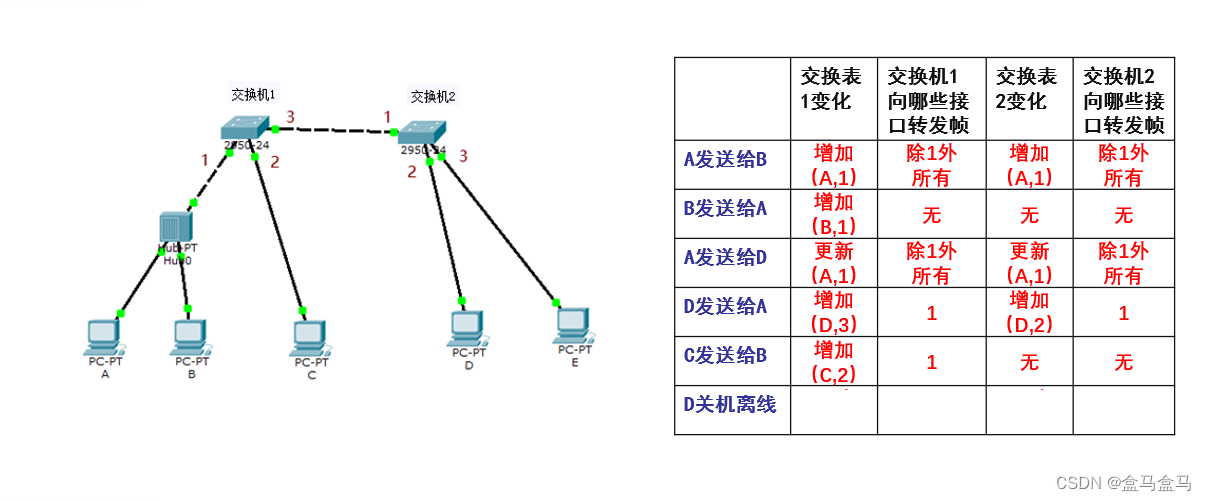
当D关机离线,等到交换机1和交换机2中的有效时间到了后,就会把D对于的条目给删掉:
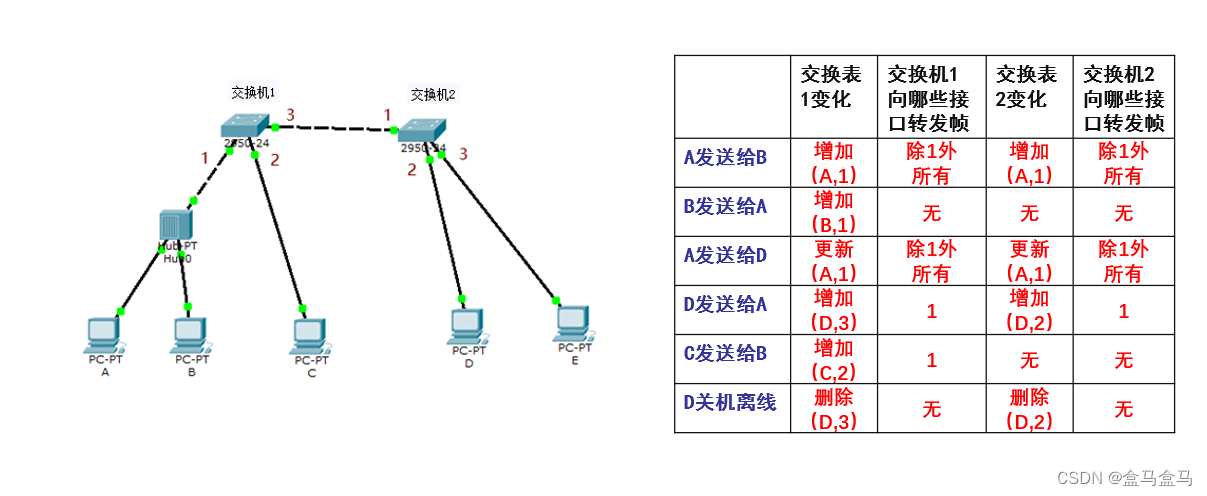
这个过程中,你会发现越到后面,交换机就会进行更加针对性的转发,以保证最高的效率。因为自学习算法相当于在累计前面转发的经验,让交换机知道当前链路更加详细的消息。
单点故障
现有如下拓扑结构:
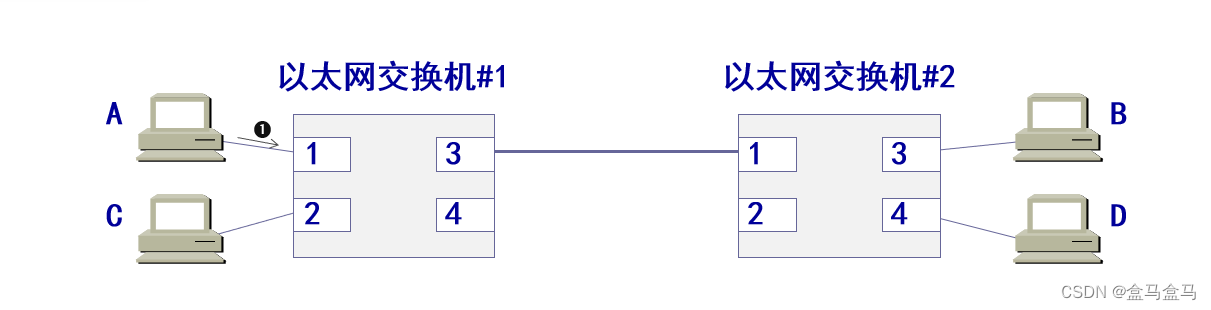
交换机1通过接口3来向B和D发送消息,而交换机2通过接口1向A和C发送消息。
假如现在3 - 1这段线路发生了错误,那么交换机1上面的主机和交换机2上面的主机就无法通信了,这就是单点故障问题。
为了避免单点故障,以太网中会增加一些冗余的链路
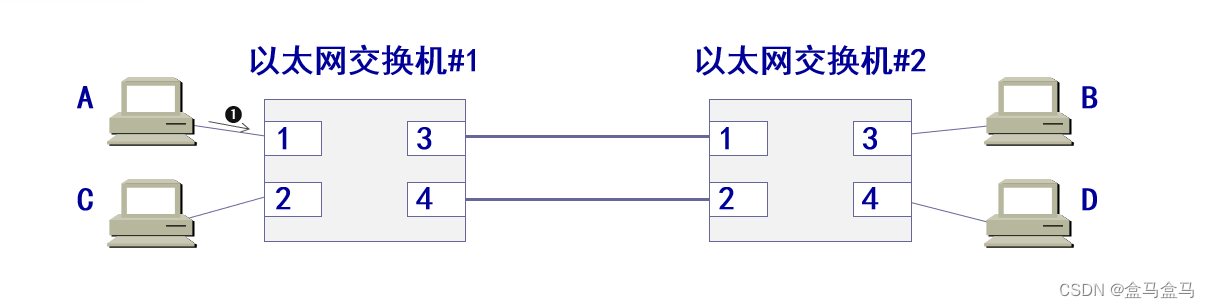
这样就算某一条链路发生单点故障,也有另外一条链路可以保证连接。但是这也带来了另外的问题,那就是网络环路问题,如下:
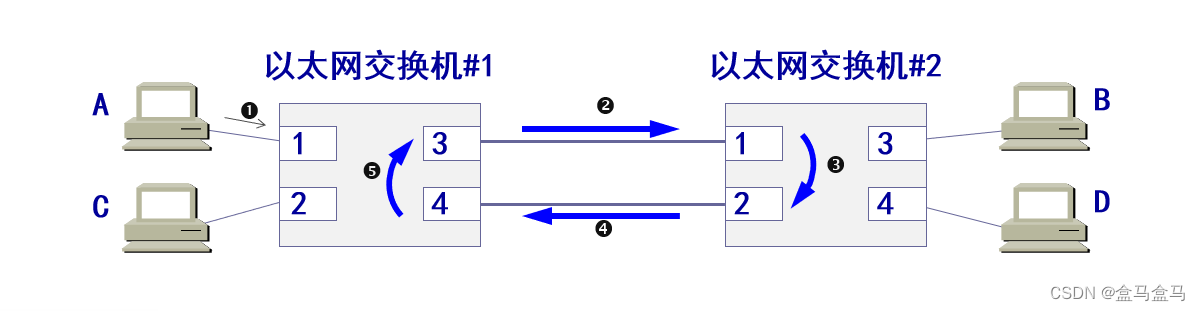
现在A要给D发送消息:
交换机1检测后,发现D在接口3,于是通过接口3转发该帧交换机2收到后,经过检测,发现没有D的消息,于是向2 3 4三个接口转发- 通过
接口2进入交换机1,此时交换机1检测后,发现D在接口3,于是通过接口3转发该帧
此时就已经进入了一个死循环,帧会在这个循环中不断转发,D会不断收到同一条消息。
对于这个问题,IE 的 802.1D 标准制定了一个生成树协议 STP(SpanningEE Tree Protocol)。STP 不改变网络的实际拓扑结构,但在逻辑上则切断某些链路以消除网络中的环路,使网络在逻辑上变成树状拓扑。
关于STP,本博客不做详解。
这篇关于计算机网络:数据链路层 - 扩展的以太网的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





