本文主要是介绍⌈ 传知代码 ⌋ 深度知识追踪,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
💛前情提要💛
本文是传知代码平台中的相关前沿知识与技术的分享~
接下来我们即将进入一个全新的空间,对技术有一个全新的视角~
本文所涉及所有资源均在传知代码平台可获取
以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦!!!
以下内容干货满满,跟上步伐吧~
📌导航小助手📌
- 💡本章重点
- 🍞一. 概述
- 🍞二. 论文方法
- 🍞三. 实验部分
- 🍞四. 关键代码
- 🫓总结
💡本章重点
- 深度知识追踪
🍞一. 概述
知识追踪的任务是对学生的知识进行建模,以便准确预测学生在未来的学习互动中的表现。简言之,我们利用学生的历史答题序列数据,通过分析学生与题目的交互结果,来推断学生当前的知识水平以及题目的特征,从而预测学生在未来题目上的表现。
过去的模型大多依赖于人工定义的交互函数,例如IRT模型,该模型定义了学生能力参数以及题目的难度、区分度和猜测性参数。
虽然也有改进不依赖交互函数的模型,如刘淇提出的NeuralCD模型,但它们更适用于对学生历史答题数据的静态评估,无法实现动态追踪,存在冷启动问题。
深度知识追《Deep Knowledge Tracing》踪将时间上“深度”的灵活递归神经网络(RNN)应用到知识追踪任务中。这一系列模型使用大量的人工“神经元”来表示潜在的知识状态及其时间动态,并且允许从数据中学习学生知识的潜在变量表示,而不是直接硬编码。通过这种方法,深度知识追踪模型解决了冷启动问题,并且能够动态追踪学生的知识状态变化,使得模型更适用于真实的学习情境。
这里对 EduKTM 的DKT方法进行改进,修改了参数,提高了正确率。
🍞二. 论文方法
传统的递归神经网络(RNNs)将输入序列 映射为输出序列 ,这是通过计算一系列隐藏状态 实现的,隐藏状态可以被看做来自过去观测的相关信息的编码,用于对未来的预测,如下图所示:

具体地说,DKT首先根据学生的历史做题情况将每个学生的交互转换为输入序列,以便RNN模型可以处理。对于唯一练习数量较少的数据集,使用one-hot编码表示学生的每次交互,其中包括练习题的编号以及学生是否正确回答。而对于具有大量唯一练习的数据集,则采用随机向量表示每个交互,以避免one-hot编码的维度爆炸问题。
接着,DKT使用RNN模型对转换后的学生交互序列进行训练。这些模型将学生的历史信息编码为一系列隐藏状态,从而捕捉学生知识状态的时间动态。最后,DKT输出一个与练习数量相等的向量,其中每个条目表示学生在相应练习上回答正确的预测概率。通过这种方式,DKT能够实现对学生知识状态的动态追踪,从而提高了对学生未来表现的预测准确性。同时,由于采用了RNN等深度学习模型,DKT还能够适应不同规模和复杂度的学生交互数据集,具有较好的泛化能力。
🍞三. 实验部分
数据集
Assistment 数据集是一个用于教育领域的常用数据集,用于研究和评估教育技术和学习分析模型。该数据集由来自辅助学习(Assistments)在线学习平台的真实学生交互数据组成。这些数据包括学生对在线练习题的回答情况、每个练习的元数据(如题目内容、难度等)、学生的个人信息(如年级、性别等)以及其他与学习过程相关的信息。

实验步骤
- step1:安装环境依赖
- step2:下载数据集,将其变成one-hot编码

- step3:进行训练
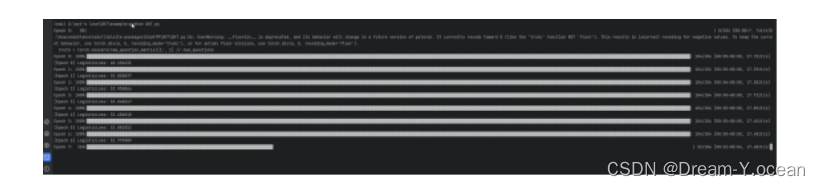
- 实验结果

🍞四. 关键代码
import numpy as np
import torch
import torch.utils.data as Data
from torch.utils.data.dataset import Dataset
import tqdmNUM_QUESTIONS = 123
BATCH_SIZE = 64
HIDDEN_SIZE = 10
NUM_LAYERS = 1def get_data_loader(data_path, batch_size, shuffle=False):data = torch.FloatTensor(np.load(data_path))data_loader = Data.DataLoader(data, batch_size=batch_size, shuffle=shuffle)return data_loadertrain_loader = get_data_loader('./data/2009_skill_builder_data_corrected/train_data.npy', BATCH_SIZE, True)
test_loader = get_data_loader('./data/2009_skill_builder_data_corrected/test_data.npy', BATCH_SIZE, False)
#%% md
# Training and Persistence
#%%
import logging
logging.getLogger().setLevel(logging.INFO)
#%%
from EduKTM import DKTdkt = DKT(NUM_QUESTIONS, HIDDEN_SIZE, NUM_LAYERS)
dkt.train(train_loader, epoch=30)
dkt.save("dkt.params")
#%% md
# Loading and Testing
#%%
dkt.load("dkt.params")
auc = dkt.eval(test_loader)
print("auc: %.6f" % auc)
🫓总结
综上,我们基本了解了“一项全新的技术啦” 🍭 ~~
恭喜你的内功又双叒叕得到了提高!!!
感谢你们的阅读😆
后续还会继续更新💓,欢迎持续关注📌哟~
💫如果有错误❌,欢迎指正呀💫
✨如果觉得收获满满,可以点点赞👍支持一下哟~✨
【传知科技 – 了解更多新知识】
这篇关于⌈ 传知代码 ⌋ 深度知识追踪的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





