本文主要是介绍关于Java的Collection 全方面了解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
深入JAVA 关于Collection 全方面了解
搜罗了很多资料,没有怎么校对,格式也很乱。如有错漏,有空再改。
一、Collection接口和实现类的层次关系
如图所示:图中,实线边框的是实现类,折线边框的是抽象类,而点线边框的是接口
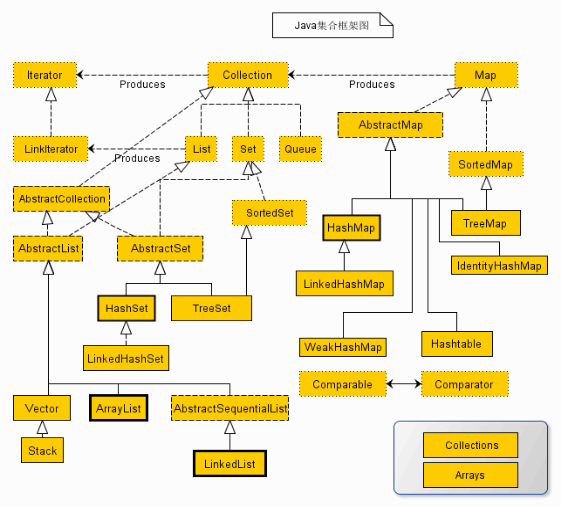
- Collection接口是集合类的根接口。
- List接口,一个有序的集合,可以包含重复元素,提供按索引访问的方式。
- Set接口,没有存储顺序,不能包含重复元素。
- Map接口,是java.util包中的接口,与Collection接口没有关系,相互独立,但属于集合类的一部分。以键值对存储数据<key,value>,键不可重复。可以是对象对对象
- Iterator接口,迭代器,所有集合类都实现了Iterator接口。
二、几个重要的接口和类简介
- List(有序,可重复)
- 存放的对象是有序的,按照add的顺序存放,对象是可以重复的。
- List关注的是索引,拥有一系列和索引相关的方法,查询速度快。
- List插入或删除数据时,要移动数据,所以比较慢。
- Set(无序,不可重复)
- 存放的对象是无序的,不可重复。集合中的对象不按特定的方式排序,只是简单地把对象加入到集合。
- Map(键值对、键唯一、值可以重复)
- 存储的是键值对,键不可重复,值可以重复,根据键得到值。
- 对Map集合遍历时要先得到键的Set集合,对Set集合进行遍历,得到对应的值。
- Iterator(迭代器)
- 所有集合类都实现了
- 遍历并选择序列中的对象,可以从迭代器所指向的Collection移除元素。
| 接口 | 实现类 | 是否有序 | 是否重复 | 内部实现 | 优缺点 |
| List (自带索引的,除了迭代器获取元素方法外,可以使用get(int index方法来获取元素) | ArrayList | 是 | 是 | 基于数组 | 查找快,增删慢 |
| LinkedList | 链表实现 | 增删快,查找慢(可以实现队列或栈的数据结构) | |||
| Vector | 于ArrayList相同,线程同步 | 线程安全,效率低,浪费空间(相对于ArrayList) | |||
| Set (底层其实就是Map接口实现的,想一想Map的键唯一) | HashSet | 否 | 否 (取决于hashCode和equals方法) | 哈希表实现 | 存取速度快,线程不安全 |
| LinkedHashSet | 带有双向链表的哈希表结构 | 非线程安全,保持存取顺序,保持了查询速度较快特点 | |||
| TreeSet | 是(二叉排序树) | 红黑树 | 非线程安全,按自然排序或比较器存入元素以保证元素有序。 元素唯一性取决于ComparaTo方法或Comparator比较器 | ||
| Map | HsahMap | 否 | 使用key-value来映射和存储数据,key必须唯一,value可以重复 | 哈希表实现 | 存取速度快,线程不安全 |
| HashTable | 哈希表实现 | 保留了存取速度,线程安全 | |||
| TreeMap | 是(二叉排序树) | 红黑树 | 认对元素进行自然排序 |
PS:
Vector 为什么不推荐
Vector唯一的优势就是线程安全,但是现在有Collections.synchronizedListt方法拿同步的List,于是Vector被淘汰了。并且相对ArrayList来说很浪费空间。Vector满空间后需要扩容一倍。
关于hashCode和equals方法
- 在以哈希表为数据结构的容器中,其存放地址取决于hashCode方法计算的值,如果hashCode的值相同,则用equals方法判断是否相同,如果都相同则判定为相同元素。
- 在以哈希表为数据结构的容器使用过程中,已经加入的元素不可以变更hashCode方法所依赖的域的值,否则会导致元素hashCode值已变化,但是其在容器中的位置却没有变化,后果是接下来的remove等操作将因为无法找到该元素而移除失败,进一步导致内存泄露。
比较器
1. Comparable接口
自定义类如果实现该接口,那么重写该接口唯一的方法comparaTo(E),可以让该类具有可比较性。
2. Comparator接口
实现该接口的类被称之为比较器,一般只具有一个方法,就是重写的这个接口的compara(E o1, E o2)方法,实现两个对象之间的比较。
三、遍历方式
在类集中提供了以下四种的常见输出方式:
- Iterator:迭代输出,是使用最多的输出方式。
- Object next( ) : 返回迭代器刚越过的元素的引用,返回值是Object
- boolean hasNext( ) : 判断容器是否还有可供方位的元素
- void remove( ): 删除迭代器刚越过的元素
- ListIterator:是Iterator的子接口,专门用于输出List中的内容。
- boolean hasPrevious( ) : 判断是否有前一个元素
- Object previous( ) : 获取前一个元素
- void add(e):添加元素
- int nextIndex( ) : 获取next后续元素的索引
- void set(E e) : 替换制定的元素
- 可以并发执行操作, Iterator执行并发操作会出现不确定性行为
- foreach输出:JDK1.5之后提供的新功能,可以输出数组或集合。
- 底层还是迭代器
- for循环
PS: 迭代器指向的位置是元素之前的位置
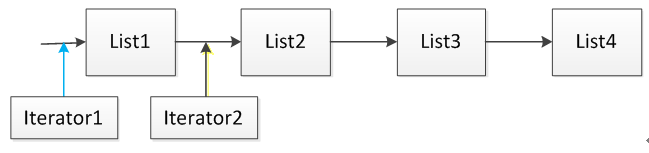
这里假设集合List由四个元素List1、List2、List3和List4组成,当使用语句Iterator it = List.Iterator()时,迭代器it指向的位置是上图中Iterator1指向的位置,当执行语句it.next()之后,迭代器指向的位置后移到上图Iterator2所指向的位置
最常用的是Iterator的形式
Iterator it = arr.iterator(); // 获取迭代器
while(it.hasNext()){ // 进行遍历Object o = it.next;...
} 对于List的遍历
// 遍历List:
List<String> list = new ArrayList<String>();
list.add("a");
list.add("b");
list.add("c");
// 1,增强的for循环
for (String str: list) {System.out.println(str);
}
// 2,下标
for (int i = 0; i < list.size(); i++) {System.out.println(list.get(i));
}
// 3,迭代器
for (Iterator<String> iter = list.iterator(); iter.hasNext();) {String elt = iter.next();System.out.println(elt);
}对于Set的遍历
Set set = new HashSet();set.add(new String("11"));
set.add(new String("222"));// 增强的for循环
for (String elt : set) {System.out.println(elt);
}
// 迭代器
Iterator i = set.iterator();//先迭代出来while(i.hasNext()){//遍历System.out.println(i.next());
}对于Map的遍历
// 1、通过获取所有的key按照key来遍历
Map map = new HashMap();
map.put("key1","lisi1");
map.put("key2","lisi2");
map.put("key3","lisi3");
map.put("key4","lisi4");
//先获取map集合的所有键的set集合,keyset()
Iterator it = map.keySet().iterator();//获取迭代器
while(it.hasNext()){Object key = it.next();System.out.println(map.get(key));
}// 2、通过Map.values()遍历所有的value,但不能遍历keyfor (String v : map.values()) {System.out.println("value= " + v);
}// 3、通过Map.entrySet遍历key和value,推荐,尤其是容量大时Map map = new HashMap();//将map集合中的映射关系取出,存入到set集合
Iterator it = map.entrySet().iterator();
while(it.hasNext()){Entry e =(Entry) it.next();System.out.println("键"+e.getKey () + "的值为" + e.getValue());
} PS:
第一种方法:KeySet()
将Map中所有的键存入到set集合中。因为set具备迭代器。所有可以迭代方式取出所有的键,再根据get方法。获取每一个键对应的值。 keySet():迭代后只能通过get()取key 。取到的结果会乱序,是因为取得数据行主键的时候,使用了HashMap.keySet()方法,而这个方法返回的Set结果,里面的数据是乱序排放的。
第二种方法:entrySet()
Set<Map.Entry<K,V>> entrySet() //返回此映射中包含的映射关系的 Set 视图。(一个关系就是一个键-值对),就是把(key-value)作为一个整体一对一对地存放到Set集合当中的。Map.Entry表示映射关系。entrySet():迭代后可以e.getKey(),e.getValue()两种方法来取key和value。返回的是Entry接口。
四、主要实现类的区别小结
Vector和ArrayList
1,vector是线程同步的,所以它也是线程安全的,而arraylist是线程异步的,是不安全的。如果不考虑到线程的安全因素,一般用arraylist效率比较高。
2,如果集合中的元素的数目大于目前集合数组的长度时,vector增长率为目前数组长度的100%,而arraylist增长率为目前数组长度的50%。如果在集合中使用数据量比较大的数据,用vector有一定的优势。
3,如果查找一个指定位置的数据,vector和arraylist使用的时间是相同的,如果频繁的访问数据,这个时候使用vector和arraylist都可以。而如果移动一个指定位置会导致后面的元素都发生移动,这个时候就应该考虑到使用linklist,因为它移动一个指定位置的数据时其它元素不移动。
ArrayList 和Vector是采用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,都允许直接序号索引元素,但是插入数据要涉及到数组元素移动等内存操作,所以索引数据快,插入数据慢,Vector由于使用了synchronized方法(线程安全)所以性能上比ArrayList要差,LinkedList使用双向链表实现存储,按序号索引数据需要进行向前或向后遍历,但是插入数据时只需要记录本项的前后项即可,所以插入数度较快。
注意:Vector唯一的优势就是线程安全,但是现在有Collections.synchronizedListt方法拿同步的List,于是Vector被淘汰了。并且相对ArrayList来说很浪费空间。Vector满空间后需要扩容一倍。
Arraylist和Linkedlist
1.ArrayList是实现了基于动态数组的数据结构,ArrayList的内部实现是基于内部数组Object[ ]
2.LinkedList基于链表的数据结构。
3.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
4.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。 这一点要看实际情况的。若只对单条数据插入或删除,ArrayList的速度反而优于LinkedList。但若是批量随机的插入删除数据,LinkedList的速度大大优于ArrayList. 因为ArrayList每插入一条数据,要移动插入点及之后的所有数据。
HashMap与TreeMap
1、 HashMap通过hashcode对其内容进行快速查找,而TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用TreeMap(HashMap中元素的排列顺序是不固定的)。
2、在Map 中插入、删除和定位元素,HashMap是最好的选择。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。使用HashMap要求添加的键类明确定义了hashCode()和 equals()的实现。
两个map中的元素一样,但顺序不一样,导致hashCode()不一样。
同样做测试:
在HashMap中,同样的值的map,顺序不同,equals时,false;
而在treeMap中,同样的值的map,顺序不同,equals时,true,说明,treeMap在equals()时是整理了顺序了的。
HashTable与HashMap
1、同步性:Hashtable是线程安全的,也就是说是同步的,而HashMap是线程序不安全的,不是同步的。
2、HashMap允许存在一个为null的key,多个为null的value 。
3、hashtable的key和value都不允许为null。
总结:
1、如果线程要求安全,使用Vector(不推荐) ,Hashtable
2、如果不要求线程安全,应使用ArrayList(推荐),LinkedList,HashMap
3、如果要求键值对,则使用HashMap(推荐)、Hashtable
4、如果数据很大,又要线程安全考虑Vector(不推荐)
Java8 更新的新特性
1.Lambda表达式
在java8中新增加了一个forEach方法,可以使用Lambda表达式来遍历集合元素
Collection books=new HashSet();
//调用foreach方法循环遍历集合
books.forEach(obj->System.out.println("迭代元素:"+obj)); 2.使用Lambda遍历Iterator
java8中为Iterator增加了一个forEachRemaining方法,,也可以使用Lambda来遍历
Collection books=new HashSet();
//获取books集合对应的迭代器
Iterator it=books.iterator();//使用lambda表达式(目标类型是Comsumer)来遍历集合元素
it.forEachRemaining(obj ->System.out.println("输出的结果是"+obj)); 3.java8中增加的Predicate操作集合
在java8中为Collection集合增加了一个removeIF方法,也可以用来操作lambda
List<String> list = new ArrayList<String>(){{// 为list添加数据addAll(Arrays.asList("wangzhen456liupei123".split("")));add("1521"); // 纯数字数据add("wanghzen123") // 数字+字符数据add("wangzhen"); // 纯字符串 }
};
System.out.println("初始数据:" + list);
Pattern pattern = Pattern.compile("\\d");//匹配数字
Predicate<String> filter = s -> pattern.matcher(s).find();
list.removeIf(filter);//移除 System.out.println(list);// 超简略写法
list.removeIf(s -> Pattern.compile("\\d").matcher(s).find()); 4.Stream操作集合
在java8中还增加了Stream、intStream、LongStream、DoubleStream等流式API,并且java8中还为每个API提供了对应的Builder,例如StreamBuilder、IntStreamBuilder等
5.Collection操作集合
在java8中还为Collection提供了stream()默认方法,改方法用来返回该集合对应的流
这篇关于关于Java的Collection 全方面了解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




