本文主要是介绍DALL·E2最详细解读篇章,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CLIP被证明其可以学习到鲁棒的图像特征,可以有效的捕获图像的语义和风格,且具有很强的zero-shot能力。另外,Diffusion是目前最优的生成式框架,其推动了图像、视频生成任务的最先进性能。Classifier-Free Diffusion指导技术以样本多样性为代价提高了样本保真度,达到了最佳结果。本文通过结合这两种方法设计了一个图像生成模型DALL-E2,以充分利用CLIP的特征。
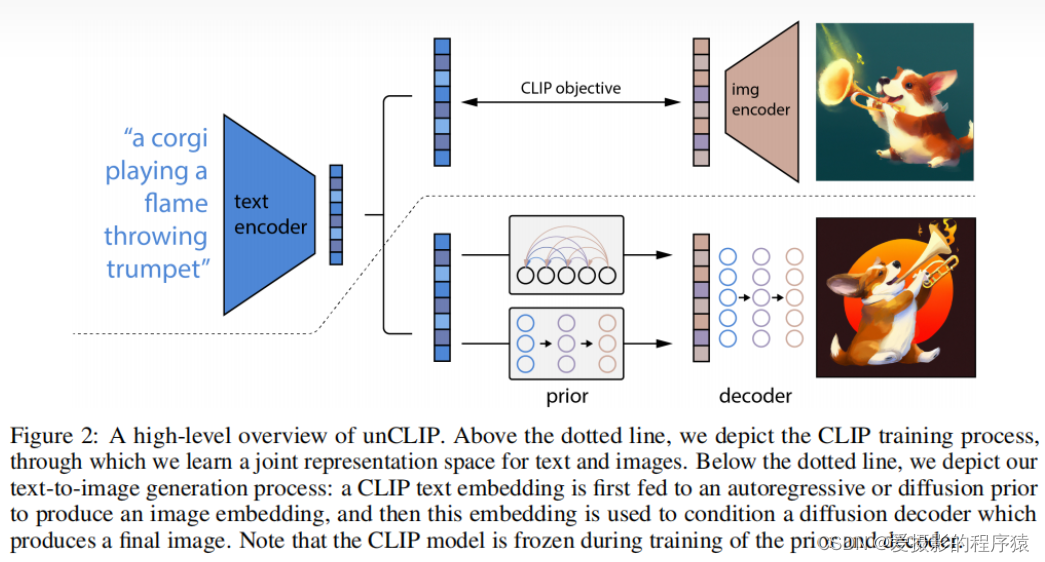
本文提出一个两阶段模型,首先给定一个文本标题,通过Prior模型生成类似CLIP的图像embedding,随后以图像embedding为条件,通过解码器生成图像。Prior和解码器都使用Diffusion模型。
采用图像embedding作为生成条件可以有效提高图像多样性,在保真度和符合文本标题主题方面损失最小。以图像embedding为条件的解码器还可以产生图像的变体,其生成在保留原始图像embedding的语义和风格的同时,可以改变图像embedding的非必要细节。如,利用CLIP的联合embedding空间能够以zero-shot的方式通过语言引导来操作图像。具体改进有:
- 通过以CLIP图像编码器监督Prior模型,得到Prior模型的可以从给定的文本标题生成可能的CLIP图像embedding
- 通过将本文方法与DALL-E、GLIDE比较,发现本文模型生成的样本在质量上与GLIDE生成相当,且更具多样性
- 开发了在 latent空间中训练Diffusion Prior的方法,并表明其具有与自回归 Prior相当的性能,但计算效率更高
- 将完整的文本条件图像生成堆栈称为unCLIP,因为其通过反转CLIP图像编码过程来生成图像(CLIP由图像生成图像embedding,unCLIP由图像embedding生成图像)

上图为unCLIP模型生成的 1024×1024 分辨率的图像示例。
框架
Method

本文的训练数据集由成对的图像/文本标题 (𝑥,𝑦) 组成。给定一组图像/文本对,其CLIP图像/文本embedding设为 𝑧𝑖 、 𝑧𝑡 ,并使用两个组件从文本标题中生成图像:
- 以文本标题 𝑦 为条件生成CLIP图像embedding 𝑧𝑖 的Prior模型 𝑃(𝑧𝑖|𝑦)
- 以CLIP图像embedding 𝑧𝑖 (和可选的文本标题 𝑦 )为条件生成图像 𝑥 的解码器模型 𝑃(𝑥|𝑧𝑖,𝑦)
解码器允许根据CLIP图像embedding来反转图像,Prior允许学习图像embedding本身。堆叠这两个组件可以得到生成模型:𝑃(𝑥|𝑦)=𝑃(𝑥,𝑧𝑖|𝑦)=𝑃(𝑥|𝑧𝑖,𝑦)𝑃(𝑧𝑖|𝑦)
基于此,可以通过首先使用Prior采样 𝑧𝑖 ,然后使用解码器采样 𝑥 ,从真实条件分布中采样 𝑃(𝑥|𝑦) 。整体结构如上图。
- Decoder
解码器以CLIP图像embedding(和可选的文本标题)为条件使用Diffusion模型来生成图像。具体,首先将CLIP embedding投影并添加到现有的timestep embedding,再将CLIP embedding投影到四个额外上下文tokens,并连接到GLIDE文本编码器输出序列,基于此修改GLIDE架构。其中保留了原始GLIDE模型的文本调节路径,假设其可以允许Diffusion模型学习CLIP未能捕捉的自然语言信息,但实验发现其在这方面提供的帮助很少。
以往Diffusion模型的工作表明,基于条件信息的guidance可以大大提高了生成的样本质量。故在训练过程中,10%的时间中随机的将CLIP图像embedding置为零,50%的时间中随机的丢弃文本标题(文本调节路径),基于此启用classifier-free guidance以提示生成样本质量。
编码器模型只使用了空间卷积(即没有注意力层),故为了生成高分辨率图像,本文训练了两个Diffusion上采样模型,一个将图像从 64×64 上采样到 256×256 分辨率,另一个会进一步将其上采样到 1024×1024 分辨率。为了提高上采样器的鲁棒性,训练过程中会略微破坏条件图像,第一个上采样阶段使用了高斯模糊,第二个阶段使用了更多样化的BSR退化。为了减少训练计算量并提高数值稳定性,模型在给定图像的四分之一的随机裁剪上进行训练,推理时则直接将模型应用于给定图像。文本标题上采样器使用没有guidance的无条件 ADMNets。
- Prior
Prior为一个从文本标题生成 𝑧𝑖 的模型,本文探索两个不同的方法:
- 自回归(AR)Prior:将CLIP的图像编码器编码的embedding 𝑧𝑖 转换为离散编码序列作为监督目标,并根据文本标题 𝑦 进行自回归预测
- Diffusion Prior:直接使用CLIP的图像编码器编码的embedding 𝑧𝑖 作为监督目标,并以文本标题 𝑦 为条件的Gaussian Diffusion模型建模
除了直接使用标题 𝑦 ,还可以将Prior条件设置为由CLIP文本编码器编码的文本embedding 𝑧𝑡 ,因为其为标题 𝑦 的确定性函数。为了提高生成的样本质量,在训练期间10%的时间会随机丢弃文本条件信息,以对AR和Diffusion Prior使用classifier-free guidance采样。
为了更有效地训练和采样AR Prior,首先通过主成分分析(PCA)降低CLIP图像embedding 𝑧𝑖 的维度。实验发现,按照特征值大小降序排列主成分,对原始的1024个主成分只保留前319个主成分,就能够保留几乎所有的原始信息。将这319个维度中的每一维都量化为1024个离散的buckets,并使用带有因果注意力mask的Transformer模型预测结果序列,这使得推理过程中需要预测的token数量减少了三倍,并提高了训练的稳定性。
对于AR Prior,使用CLIP文本编码器编码文本描述,作为AR Prior的序列条件的前缀。并添加一个tokens,表示CLIP文本embedding和CLIP图像embedding之间(量化)点积 𝑧𝑖·𝑧𝑡 ,这可以使模型根据更高的点积进行条件化,因为较高的文本/图像点积对应于更好地描述图像的标题。
对于Diffusion Prior,使用一串序列来训练一个具有因果注意力mask的仅解码器的Transformer,该序列由编码的文本、CLIP文本embedding、Diffusion timestep的embedding、含噪CLIP图像embedding和作为预测结果的未含噪CLIP图像embedding。为了提高生成质量,每个去噪过程中都会生成两个 𝑧𝑖 ,并选择与 𝑧𝑡 具有更高点积的 𝑧𝑖 来作为生成结果。Diffusion Prior会直接预测无噪声的 𝑧𝑖 ,并在此预测上使用均方误差损失:𝐿𝑝𝑟𝑖𝑜𝑟=𝐸𝑡∼[1,𝑇],𝑧𝑖(𝑡)∼𝑞𝑡[||𝑓𝜃(𝑧𝑖(𝑡),𝑡,𝑦)−𝑧𝑖||2]
实验
Image Manipulations
本方法允许将任何给定的图像 𝑥 编码为bipartite latent表示 (𝑧𝑖,𝑥𝑇) ,这足以使解码器产生准确的重建。latent的 𝑧𝑖 描述了由CLIP识别的图像特征,而latent的 𝑥𝑇 编码了解码器重建 𝑥 所需的所有残差信息。 前者通过使用CLIP图像编码器对图像编码获得,后者以 𝑧𝑖 为条件,并使用解码器对 𝑥 应用DDIM反演获得。本章描述了由这种bipartite表示启发的三种不同类型的操作。
- Variations

给定图像 𝑥 ,unCLIP可以生成基本内容相同,但在其他方面(形状和方向)有所不同的图像。具体过程,将解码器应用于 𝑥 的二部图表示 (𝑧𝑖,𝑥𝑇) ,其通过 η>0 的DDIM进行采样。当 η=0 时,解码器变得确定,将重建给定的图像 𝑥 。随着 η 的增加,会将随机性引入连续的采样步骤,导致最终生成的图像相对于原始图像的变化,这些变化可以阐述CLIP图像 embedding中捕获和丢失的信息。(如上图)
- Interpolations

unCLIP可以将两个图像 𝑥1 和 𝑥2 进行混合,并遍历发生在两图之间的CLIPembedding空间中的所有概念(如上图)。具体过程,使用球面插值旋转 𝑥1 和 𝑥2 的CLIPembedding 𝑧𝑖1 和 𝑧𝑖2 ,并产生中间CLIP表示 𝑧𝑖θ=𝑠𝑙𝑒𝑟𝑝(𝑧𝑖1,𝑧𝑖2,θ) 。因为 θ 从0到1变化,故沿着轨迹产生中间DDIM latent表示的方法有两种:
- 在DDIM反演latent变量 𝑥𝑇1 和 𝑥𝑇2 之间进行插值( 𝑥𝑇θ=𝑠𝑙𝑒𝑟𝑝(𝑥𝑇1,𝑥𝑇2,θ) ),这产生一个单一的轨迹,其两个端点为重建 𝑥1 和 𝑥2
- 将DDIM latent变量固定为整个轨迹中所有插值的随机抽样值。这导致 𝑥1 和 𝑥2 之间有无限多的轨迹,这些轨迹的端点通常也不再与原始图像重合
- Text Diffs

CLIP的一个关键优势在于,其将图像和文本embedding到了相同的latent空间中,从而允许用户通过语言引导图像操作(如上图)。具体过程,首先获取操作文本的CLIP文本embedding 𝑧𝑡 ,以及当前图像标题的CLIP文本 𝑧𝑡0 。然后,通过取它们的差并归一化来计算文本差异向量 𝑧𝑑=𝑛𝑜𝑟𝑚(𝑧𝑡−𝑧𝑡0) 。再用球面插值在CLIP图像embedding 𝑧𝑖 和文本差异向量 𝑧𝑑 之间旋转,产生中间CLIP表示 𝑧θ=𝑠𝑙𝑒𝑟𝑝(𝑧𝑖,𝑧𝑑,θ) ,其中 θ 从0线性增加到 [0.25,0.50] 中的最大值。最后通过解码插值 𝑧θ 来生成最终输出,在整个轨迹中将基础DDIM噪声固定为 𝑥𝑇 。
Probing the CLIP Latent Space

解码器模型可以可视化CLIP图像编码器编码的内容,这为探索CLIP的latent空间提供了独特的机会。回顾CLIP预测错误的情况,例如typographic attacks,在这些对抗性图像中,一段文本会覆盖在图像的主要对象之上,这导致CLIP预测了覆盖文本中描述的对象,而不是图像主要内容描述的对象。如上图,苹果可能被错误地分类为iPod。但即使这种情况,unCLIP的解码器仍然高概率生成了苹果的图片,即使CLIP预测的”Granny Smith”概率接近于零。

PCA重建提供了另一种探索CLIP latent空间结构的工具。基于PCA的主成分排序CLIP图像embedding的维度,当逐步增加重建所用的图像embedding维度时,在固定种子的解码器上使用DDIM对重建的图像embedding进行可视化,可观察到CLIP图像embedding的不同维度编码的语义信息。
早期的PCA维度保留了粗粒度的语义信息,如场景中物体的类型,而后期的PCA维度编码了细粒度的细节,如物体的形状和精确形式。例如,在第一个场景中,较早的维度似乎表示有食物和一个容器存在,而较晚的维度则表示有西红柿和一个瓶子。
Text-to-Image Generation
- Importance of the Prior

因为unCLIP是classifier-free guidance的,所以其解码器的条件可以是CLIP图像embedding或文本标题embedding或直接采用文本为条件。基于此进行实验,结果如上图。前两行为没有Prior模型的情况下,直接采用文本条件和文本embedding条件生成的样本,第三行为通过Prior模型的知识生成的样本。观察到,只采用文本的生成结果是最糟糕的,但基于文本embedding的约束zero-shot产生了合理的结果。故基于此观察,另一种方法是可行的训练解码器的方法是以CLIP文本embedding而不是CLIP图像embedding为条件。
故训练了两个模型,一个以CLIP文本embedding为条件的小型解码器,和一个小型unCLIP堆栈(Diffusion Prior和解码器)。基于此,实验比较了来自文本embedding解码器的生成样本,unCLIP堆栈的生成样本,以及从将文本embedding提供给unCLIP解码器通过zero-shot获得的生成样本。实验发现,这些方法在测试集上的FID分别为9.1、7.99和16.55,表明unCLIP方法是最好的。另外还对前两个设置进行了人工评估,实验发现,人类更偏好完整的unCLIP堆栈,其图像真实感为57.0%±3.1%,标题相似性为53.1%±3.1% 。
鉴于Prior的重要性,还比较了AR和Diffusion Prior。发现在所有情况下,Diffusion Prior在可比的模型大小和更少的训练计算量的情况下优于AR Prior。
- Human Evaluations
本节基于人工评估,将unCLIP与GLIDE的生成在图像真实感、标题相似性和样本多样性方面进行了比较。 对于真实感,用户会看到成对的图像,并在其中选择看起来更逼真的图像。对于标题相似度,用户会被提示一个标题,并从图像对中选择与标题更匹配的图像。在这两个评估中,还有第三个“不确定”选项。对于多样性,会向用户展示一对 4×4 网格的生成样本,并从两者中选择哪个更多样化,此评估使用MS-COCO验证集中的1000个标题来生成样本网格,并始终对相同标题生成的样本网格进行比较。

结果如上表。观察到,在与GLIDE进行两两比较时,Diffusion Prior比AR Prior表现总体而言更好。在逼真度方面,人类偏好稍稍倾向了GLIDE,但unCLIP与其差距非常小。另外,unCLIP在多样性方面取得了更好的结果,突出了其优势。
- Improved Diversity-Fidelity Trade-off with Guidance

与GLIDE相比,unCLIP能够生成更多样化的图像,在利用指导技术后可进一步提高样本质量。如上图,在不同指导尺度的GLIDE和unCLIP的生成。观察到,GLIDE生成的语义(相机角度、颜色、大小)会随着指导尺度增大而收敛,而unCLIP不存在这种问题,因为其语义信息在CLIP图像embedding中被冻结,因此在引导解码器时不会崩溃。

unCLIP在与GLIDE类似的图像真实感的情况下,保持了更多的多样性,但其标题匹配能力略差。故本节实验了在降低GLIDE的指导尺度的情况下,是否可以获得与unCLIP相同的多样性水平,同时保持更好的标题匹配能力。结果如上图,通过对GLIDE在几个不同指导尺度上执行人工评估,发现GLIDE在引导尺度为2.0时,其生成的真实感和标题相似性非常接近于unCLIP,但多样性仍然较差。

本节实验固定了unCLIP Prior的指导尺度,只改变解码器的指导尺度,并在MS-COCO的zero-shot配置下实验了两个模型的FID。结果如上图,发现指导技术对unCLIP的FID提升要比GLIDE高得多。同时也表明指导技术对GLIDE的多样性的伤害比unCLIP大得多,因为FID严重惩罚了非多样性。
- Comparison on MS-COCO

上表为在MS-COCO上对比了不同模型的文生图FID基准测试的结果。与GLIDE和DALL-E一样,unCLIP也没有直接在MS-COCO训练集上进行训练,但仍然可以以zero-shot泛化到其验证集。与其他zero-shot模型相比,unCLIP在用Diffusion Prior采样时实现了10.39的最先进水平的FID。

上图在MS-COCO的几个标题上,将unCLIP与最近的一些文生图模型的生成进行了可视化比较。观察到,与其他方法一样,unCLIP也捕捉到了文本prompt的现实场景。
- Aesthetic Quality Comparison
本文还将unCLIP与GLIDE进行了automated aesthetic quality评估,评估目标为每个模型制作的艺术插图和照片的效果。为此,通过提示GPT-3现有艺术品的标题(真实的和人工智能生成的),生成了512个“artistic”prompt标题。另外,使用了AVA数据集训练了一个CLIP线性检测器来预测人类的审美判断。对于每个模型和一组采样超参数,都会分别为每个prompt生成4张图像,并报告CLIP线性检测器在2048张图像的平均审美判断。

结果如上图。观察到,指导技术提高了GLIDE和unCLIP的aesthetic quality(unCLIP只对解码器指导)。因为指导通常会导致真实度和多样性的权衡,故还绘制了aesthetic quality与召回率的关系,实验结果显示,引导unCLIP并没有降低召回率,同时仍然具有较高的aesthetic quality。
Limitations and Risks
在CLIPembedding上调节图像生成虽然可以提高多样性,但unCLIP在标题属性绑定到对象方面的能力比相应的GLIDE模型更差。

如上图,提示模型必须将两个单独的对象(立方体)绑定到两个单独的属性(颜色)。

本文假设这种情况的发生是因为CLIP embedding本身没有显式地将属性绑定到对象,故从解码器进行的重建时经常会混淆属性和对象,如上图。

同时,类似的、可能相关的问题是unCLIP难以生成连贯的文本,如上图。unCLIP embedding可能无法精确编码呈现文本的拼写信息,因为CLIP文本编码器使用的BPE编码会模糊标题中单词的拼写,因此训练过程中模型需要独立地看到每个输入token(图像/文本token),以便学习渲染。

另外模型在复杂的场景中难以产生相关细节,如上图。本文假设这是由于解码器的层次结构限制,故以更高的基础分辨率训练unCLIP解码器应该能够缓解这一问题,但代价是额外的训练和推理计算量。
Appendix
Training Details

本文实验中使用的unCLIP模型全部采用以下描述的超参数进行训练。相比于原始unCLIP,unCLIP的生产版本训练了更长时间,且修改了原始架构,包括适应产品和安全要求的更改,并在经过aesthetic quality和安全性过滤的更大数据集上进行训练。上表为本文模型的模型和训练超参数,所有模型都使用Adam进行训练,并采用权重衰减和 β1=0.9 的动量。
本文采用的CLIP模型使用了ViT-H/16作为图像编码器,该编码器输入分辨率为 256×256 ,并具有宽度为1280的32个Transformer块。文本编码器为一个具有因果注意力mask的Transformer,具有宽度为1024的24个Transformer块。两个模型都使用 3×10−4 的学习率和 ρ=0.1 的SAM进行训练。
在训练编码器时,等概率的从CLIP和DALL-E采用的数据集(总共大约650万张图像)中采样数据。 在训练解码器、上采样器和Prior时,只使用DALL-E的数据集(大约250M张图像)。
unCLIP的解码器架构是35亿参数的GLIDE模型,并使用以学习过sigma进行训练。
使用ADMNet作为上采样器,在第一个上采样阶段,使用cosine noising schedule,每种分辨率下都有3层resblocks,通道数为320,另外还采用了高斯模糊(内核大小3,sigma 0.6)作数据增强。第二个上采样阶段,使用linear noising schedule,每种分辨率下有两层resblocks,通道数为192,并使用BSR退化进行训练。对于Diffusion过程,为了减少推理时间使用DDIM并手动调整降噪步骤数量, 256×256 模型有27个步骤, 1024×1024 模型有15个步骤。
对于AR Prior,使用宽度为2048的24个Transformer块的文本编码器和宽度为1664的24个因果注意力mask解码器。对于Diffusion Prior,使用宽度为2048的24个Transformer块,并用DPM进行采样,采样步骤为64步。
Random samples
下列图为DALL-Ev2由给定prompt生成的一些示例。



reference
Ramesh, A. , Dhariwal, P. , Nichol, A. , Chu, C. , & Chen, M. . (2022). Hierarchical text-conditional image generation with clip latents. arXiv e-prints.
这篇关于DALL·E2最详细解读篇章的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





