本文主要是介绍GPT-4o与SQL:大模型改变自身架构的能力有多强?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
尽管没有任何大型语言模型(LLM)骑过自行车,但它们显然理解骑行在人类交通领域中的作用。它们似乎为软件开发者提供的是一种类似语义的现实世界知识,结合了对技术世界的理解。我们在最近的一篇文章中清楚地看到了这一点,仅通过用自然语言描述,我们就能够生成一个简单的图书出版SQL架构。
虽然我对Llama 3创建架构的性能感到满意,但我之前在Oracle工作时期的一位同事指出,图书出版架构是一个相当为人熟知的例子。为了便于理解,这自然是件好事,但为了进一步拓展LLM的能力,本文中我将探索大型语言模型根据英语描述的问题调整其自身架构的能力如何。这一次,我将使用OpenAI的GPT-4o,因为它最近在代码审查方面为我提供了很好的帮助。
作为出发点,我们将从与第一篇文章中相同的问题开始,并总结答案,这个答案与上次相似。这一次,GPT-4o不仅为我们提供了一个ERD(实体关系图),还很好地解释了各实体间的关系:

和之前的尝试类似,它提出了以下这样的架构:
CREATE TABLE Author ( author_id INT AUTO_INCREMENT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), birth_date DATE, nationality VARCHAR(50)
); CREATE TABLE Publisher ( publisher_id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(100), address VARCHAR(255), contact_number VARCHAR(20), email VARCHAR(100)
); CREATE TABLE Book ( book_id INT AUTO_INCREMENT PRIMARY KEY, title VARCHAR(100), genre VARCHAR(50), publication_date DATE, isbn VARCHAR(20) UNIQUE, author_id INT, publisher_id INT, FOREIGN KEY (author_id) REFERENCES Author(author_id), FOREIGN KEY (publisher_id) REFERENCES Publisher(publisher_id)
);我更倾向于让表名使用所包含对象的复数形式,我认为这是被广泛接受的标准。
大型语言模型指出了这些关系限制:

因此,使用上次相同的示例数据,让我们在SQL沙盒环境DB Fiddle中检查是否能得到相同的结果。如果我们填充这些数据并添加上次的视图……
INSERT INTO Author (first_name, last_name, birth_date)
VALUES ('Iain', 'Banks', '1954-02-16'); INSERT INTO Author (first_name, last_name, birth_date)
VALUES ('Iain', 'M Banks', '1954-02-16'); INSERT INTO Publisher (name, address)
VALUES ('Abacus', 'London'); INSERT INTO Publisher (name, address)
VALUES ('Orbit', 'New York');INSERT INTO Book (title, author_id, publisher_id, publication_date)
VALUES ('Consider Phlebas', 2, 2, '1988-04-14');INSERT INTO Book (title, author_id, publisher_id, publication_date)
VALUES ('The Wasp Factory', 1, 1, '1984-02-15');CREATE VIEW ViewableBooks AS
SELECT Book.title 'Book', Author.first_name 'Author firstname', Author.last_name 'Author surname', Publisher.name 'Publisher', Book.publication_date
FROM Book, Publisher, Author
WHERE Book.author_id = Author.author_id
AND Book.publisher_id = Publisher.publisher_id;我们就能在下方的表格中从DB Fiddle获得所需的结果视图:
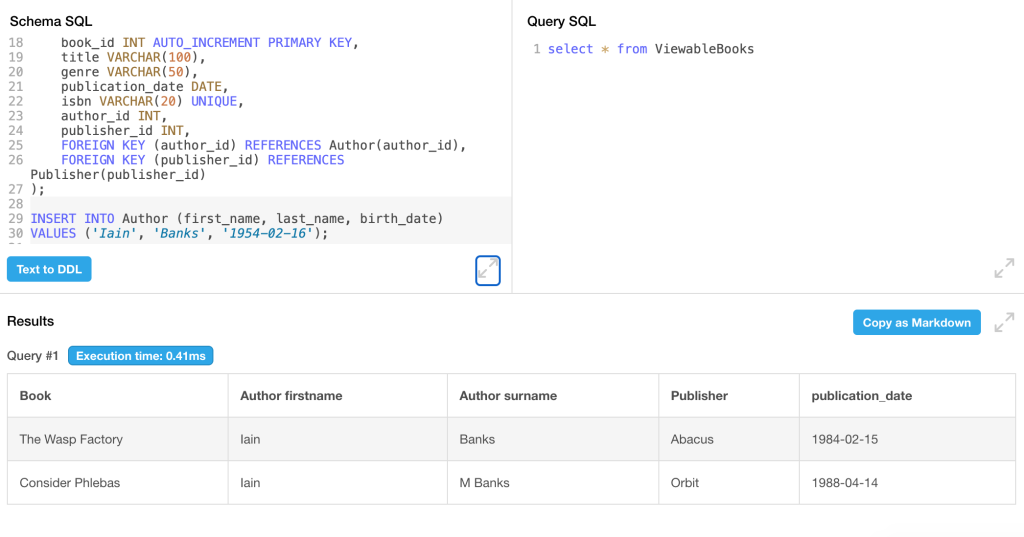
第二个姓氏中包含了中间名“M”,看起来有些别扭。接下来,我们将探讨与此相关的问题。
1.首次修改
正如我在前一篇关于SQL生成的文章中提到的,“Ian Banks”和“Ian M Banks”实际上是同一位作者。上次,我们没有解决这个笔名问题。所以,让我们要求大模型来修复这个问题:

所以这是个好的开始。这次它需要将“笔名”这一文学概念映射到它已经产生的现有架构设计上。因此,它不仅要发现现有的解决方案,还必须做更多的工作。首先,我们来看看新建立的关系:

这看起来是合理的。以下是经过修改的新表结构:
CREATE TABLE Pseudonym ( pseudonym_id INT AUTO_INCREMENT PRIMARY KEY, pseudonym VARCHAR(100), author_id INT, FOREIGN KEY (author_id) REFERENCES Author(author_id)
); CREATE TABLE Book ( book_id INT AUTO_INCREMENT PRIMARY KEY, title VARCHAR(100), genre VARCHAR(50), publication_date DATE, isbn VARCHAR(20) UNIQUE, pseudonym_id INT, publisher_id INT, FOREIGN KEY (pseudonym_id) REFERENCES Pseudonym(pseudonym_id), FOREIGN KEY (publisher_id) REFERENCES Publisher(publisher_id)
);这感觉也是正确的。架构现在将书籍关联到笔名,而不是直接关联到作者。让我们使用新的架构重新做一个dbfiddle,输入经过修改的数据以配合使用,并查看我们是否能再次获得理想的结果:
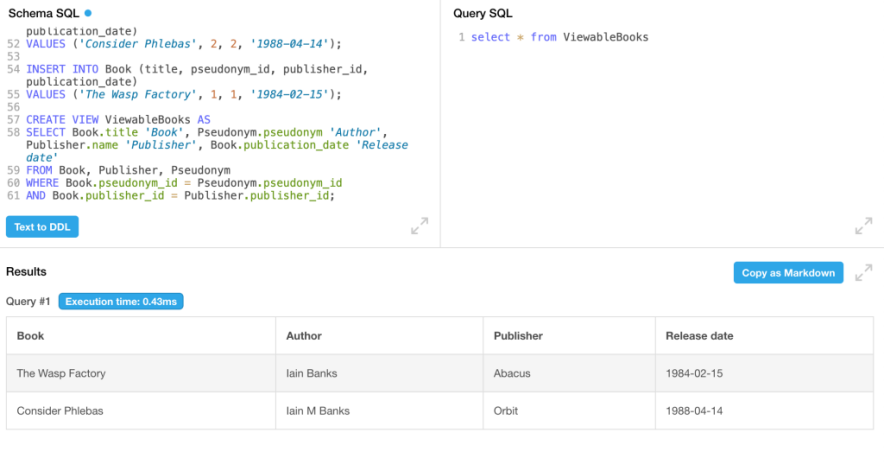
实际上,现在笔名栏只是一个字段,表格显得更加整洁了。
2.另一个修改请求
现在,我将提出进一步的架构修改要求。我们知道一本书可以有多个作者(你可能还记得上次Llama 3在没有提示的情况下就提出了这一点),所以我们希望GPT-4o再次修改其架构。

需要增加的那一个新表就是:
CREATE TABLE BookAuthor
( book_id INT, pseudonym_id INT, PRIMARY KEY (book_id, pseudonym_id), FOREIGN KEY (book_id) REFERENCES Book(book_id), FOREIGN KEY (pseudonym_id) REFERENCES Pseudonym(pseudonym_id)
);因此,关系变更如下:

(注意,在描述了最初几段关系后出现了奇怪的括号错误。这个错误在所有关系的描述中都有重复出现。它似乎阻止了文本“1:M”或“M:M”的打印——可能是由于表情符号混淆?)
当然,GPT-4o也在遵循单一的对话线索——它将其先前的工作内容纳入了上下文考虑。这种广受赞誉的能力确实使得与它的交互更加自然。总体而言,它表现得很好(并且非常迅速)地解析了我们的英语描述,以调整其建议的架构。
3.在我们太过兴奋之前
架构主要关乎事物之间的关系——并不需要对事物本身的深入了解。然而,这并不完全意味着大模型接管数据库设计的道路已经畅通无阻。
针对SQL查询和架构进行优化一直都有点儿像一门艺术。需要理解哪些常见查询会最适合某种设计、将涉及多少张表、查询间的依赖性、索引定义、分区等等。而这还只是在处理CAP定理困境——一致性与可用性之间的权衡——之前。在这些技术抽象之下,是人们对数据检索远非简单的预期。
我相信,随着时间的推移,大型语言模型与专业化的某种结合将逐步解决这些工程问题,但目前我们应该为GPT-4o能够高效地生成和修改合理架构的能力而感到胜利。
这篇关于GPT-4o与SQL:大模型改变自身架构的能力有多强?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




