本文主要是介绍本地运行ChatTTS,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
TTS 是将文字转为语音的模型,最近很火的开源 TTS 项目,本地可以运行,运行环境 M2 Max,差不多每秒钟 4~~5 个字。本文将介绍如何在本地运行 ChatTTS。
下载源码
首先下载源代码
git clone https://github.com/2noise/ChatTTS
安装依赖
安装项目所需依赖
cd ChatTTS
pip install -r requirements.txt
打开 example.ipynb
项目中自带了一个示例代码,直接在 VSCode 中打开,默认模型从 Hugginface 下载,我添加了一段代码,从 ModelScope 下载,再从本地读取模型。
from modelscope import snapshot_download
## 产看日志的中 Model 下载位置
model_dir = snapshot_download('pzc163/chatTTS')chat = ChatTTS.Chat()
# chat.load_models()# Use force_redownload=True if the weights updated.
# chat.load_models(force_redownload=True)# If you download the weights manually, set source='locals'.
# 修改 local_path 到指定位置
chat.load_models(source='local', local_path='/mnt/workspace/.cache/modelscope/pzc163/chatTTS')
运行
按 Notebook 中步骤运行就可以生成语音了。
启动 UI
根目录下运行
python web-ui.py

QA
如果遇到 Normalizer pynini WeTextProcessing nemo_text_processing ,
- 安装依赖
conda install -c conda-forge pynini=2.1.5 && pip install nemo_text_processing
conda install -c conda-forge pynini=2.1.5 && pip install WeTextProcessing
- 如果问题依然存在,可以将代码注释掉
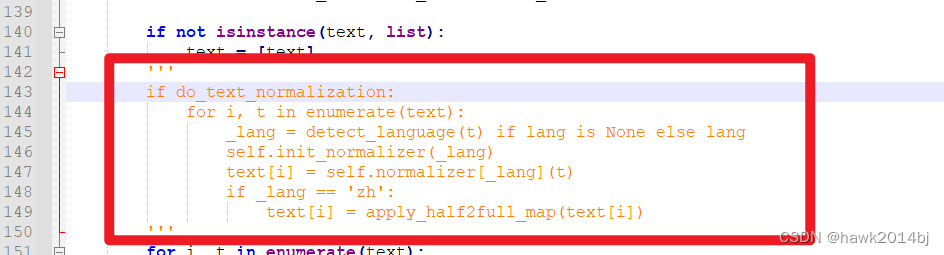
具体解决方案参见 issue 164
这篇关于本地运行ChatTTS的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








