本文主要是介绍C++:Traits编程技法在STL迭代器中的应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 迭代器相应型别
- Traits(特性)编程技法——STL源代码门钥
- 迭代器相应型别一:value_type
- 迭代器相应型别二:difference_type
- 迭代器相应型别三:reference_type
- 迭代器相应型别四:pointer_type
- 迭代器相应型别五:iterator_category
- 以`advanced()`为例
- 取消单纯传递调用的函数
- 以`distance()`为例
- std::iterator的保证
本文将介绍STL库中迭代器的实现,汇总自:《STL源码剖析》。
迭代器相应型别
什么是迭代器的相应型别?迭代器所指向内容的类型便是其一。假设算法中必须声明一个变量,而该变量的类型与“迭代器所指向内容的类型”相同,那该怎么办呢?C++只支持sizeof,并未支持typeof。即使使用typeid,得到的也只是类型的名称(字符串),并不能拿来创建变量。
解决办法是:利用函数模板的参数推导机制。
例如:
template<class I, class T>
void func_impl(I iter, T t)
{T tmp; // 这里解决了问题,T就是迭代器所指内容的类型// ... 这里做原本func()应该做的全部任务
}template<class I>
void func(I iter)
{func_impl(iter, *iter); // fun()的工作移到func_impl()
}int main()
{int i;func(&i);return 0;
}
这个程序中我们以func()为对外接口,却把实际操作全部放在了func_tmpl()中,并将迭代器解引用后的内容作为参数传递给了func_tmpl(),由于func_tmpl()为函数模板,所以会自动推导迭代器解引用后的类型,也就是迭代器所指向内容的类型,本例中为T(int)。
迭代器相应型别不只有所指内容的类型这一种,一般最常用的有五种,然而并非任何情况下都可以用上面的模板参数推导机制来取得,我们需要更全面的解法。
Traits(特性)编程技法——STL源代码门钥
迭代器所指对象的类型,称为该迭代器的value_type。上面的技巧虽然可用于value_type,但并不全面:如果value_type必须用于函数的返回值,那就束手无策了,因为函数的模板参数推导机制只能推导参数类型,不能推导返回值类型。
而声明内嵌类型似乎是个解决办法,比如:
template<class T>
struct MyIter // 在迭代器内部声明自己的所指内容类型为 value_type
{typedef T value_type; // 内嵌类型声明T* ptr;MyIter(T* p = nullptr):ptr(p){}// ...
};template<class I>
typename I::value_type func(I ite) // 获取迭代器所指内容的类型可用 typename I::value_type
{// ...return *ite;
}
需要注意的是获取迭代器所指内容的类型可用I::value_type前必须加typename,因为类作用限定符后面不止可能是类型,也可能是静态成员,只有加上typename编译才能通过。
这样看起来解决了问题,事实上,确实解决了大部分迭代器的问题,但是有一种迭代器不行——原生指针。因为原生指针不是类类型,不能声明内嵌类型。解决原生指针作为迭代器的办法是,为原生指针进行模板的特化。
现在我们针对“迭代器为原生指针”的情况,设计特化版的迭代器。
下面这个类模板专门用来萃取迭代器的特性,而value_type正式迭代器的整形之一。
template<class I>
struct iterator_traits // 这个类的含义为:迭代器的特性
{typedef typename I::value_type value_type;
};
这里所谓特性的意义是,如果I有定义value_type,那么通过这个类的作用,萃取出来的value_type就是I::value_type。那么我们把这个类应用起来,原来的func()就应该这样写:
template<class I>
typename iterator_traits<I>::value_type func(I iter)
{// ...return *ite;
}
这样看起来,只是多封装了一层,有什么用呢?作用就是我们可以对原生指针迭代器做特化版本。如下:
template<class I>
struct iterator_traits<I*> // 偏特化——迭代器是个原生指针
{typedef I value_type;
}
于是,原始指针虽然不是类类型,但是也可以通过特化过的萃取模板来获得value_type。
但是还有一个问题,针对“指向常熟对象的指针(pointer-to-const)”,会发生什么?该种迭代器也是原生指针,且本身可以修改,但是指向的内容不能修改,所以他会匹配特化版本,所以我们得到的value_type就是const I,这并不是我们所希望的结果,因为如果我们就以const I来作为value_type来使用,那么在使用的过程中,如果我们要给这一类型的变量赋值,便会编译报错。所以无论是普通对象的迭代器还是常量对象的迭代器,我们萃取后想得到的value_type一定是非常量的。为了解决这个问题,我们只需再设计一个特化版本:
**pointer-to**-consttemplate<class I>
struct iterator_traits<const I*> // 偏特化——当迭代器是个pointer-to-const时
{ // 萃取出来的类型应该是 I 而非 const Itypedef I value_type;
}
现在,无论是类类型的迭代器,还是原生指针的迭代器,还是指向常量的原生指针的迭代器,我们都可以通过萃取来获得正确的value_type。
与value_type一样,其他的迭代器型别也可以通过萃取来获得。根据经验,常用的迭代器相应型别有五种:value_type,difference_type,pointer,reference,iterator_catagoly。所以设计的萃取类应该为:
class<class I>
struct iterator_traits
{typedef typename I::value_type value_type;typedef typename I::difference_type difference_type;typedef typename I::pointer pointer;typedef typename I::reference reference;typedef typename I::iterator_catagoly iterator_catagoly;
};
iterator_traits还需要为pointer和pointer-to-const设计特化版本,下面来介绍如何设计。
迭代器相应型别一:value_type
value_type就是迭代器所指对象的类型,任何一个想要使用STL算法的类,都应该定义自己的内嵌性别,做法如上。
迭代器相应型别二:difference_type
difference_type用来表示两个迭代器之间的距离,因此它也可以用来表示一个容器的最大容量,因为对于连续空间的容器而言,头尾之间的距离就是其最大容量。如果一个泛型算法提供计数的功能,例如STL中的count(),它的返回值必须使用迭代器的difference_type。
template<class I, class T>
typename iterator_trauts<I>::difference_type count(I first, I last, const T& val)
{typename iterator_trauts<I>::difference_type n = 0;while(first != last){if(*first == val)++n;++first;}return n;
}
针对相应类型的difference_type,萃取类针对两种原生指针的特化版本如下:
class<class I>
struct iterator_traits<I*>
{// ...typedef ptrdiff_t difference_type; // ptrdiff_t 定义于<cstddef>头文件,一般是 long int
};class<class I>
struct iterator_traits<const I*>
{// ...typedef ptrdiff_t difference_type;
};
现在,任何时候当我们需要任何迭代器I的difference_type可以这样写
typename iterator_traits<I>::difference_type
迭代器相应型别三:reference_type
迭代器以“迭代器所指对象的内容是否允许改变”可以分为两种,普通迭代器和const迭代器。
在C++中函数如果要传回左值,都是以by reference的方式进行,所以当p是个普通迭代器时,如果其value_type是T,那么*p的类型不应该是T,而应该是T&,同理,如果p是const迭代器,那么*p的类型不应该是const T,而是const T&。
这里所讨论的*p的类型,就是所谓的reference_type(引用类型),实现细节再下一节一并展示。
迭代器相应型别四:pointer_type
pointers和references分别代表指针和引用,我们以list的迭代器为例:
Item& operator*() const { return *ptr; } // Item 为list的结点类型
Item* operator&() const { return ptr; }
Item&便是list的reference_type,而Item*便是其pointer_type。
现在我们把reference_type和pointer_type加入萃取类。
template<class I>
struct iterator_traits
{// ...typedef typename I::reference_type reference; // 类类型的迭代器在迭代器类内部定义typedef typename I::pointer_type pointer; // reference_type和pointer_type
}; // 这里只做封装
针对两种原生指针类型的特化版本
template<class I>
struct iterator_traits<I*>
{// ...typedef I& reference;typedef I* pointer;
}template<class I>
struct iterator_traits<const I*>
{// ...typedef const I& reference;typedef const I* pointer;
}
迭代器相应型别五:iterator_category
根据移动特性和施行操作,迭代器被分为五大类:
- Input Iterator:这种迭代器所指的对象,不允许外界改变。只读
- Output Iterator:只写
- Forward Iterator:允许写入型算法,可以在这种迭代器所形成的区间上进行读写操作,这种迭代器只能单向移动
- Bidirectional Iterator:可双向移动
- Random Access Iterator:前四种迭代器都只供应一部分指针算出能力(前三种支持
operator++,第四种再加上operator--)第五种则涵盖所有指针算术能力,包括p±n,p[n],p1-p1,p1<p2。
这些迭代器的从属关系,可以用下图表示,注意,下图中的直线和箭头并非表示继承关系,而是所谓的概念于强化的关系。
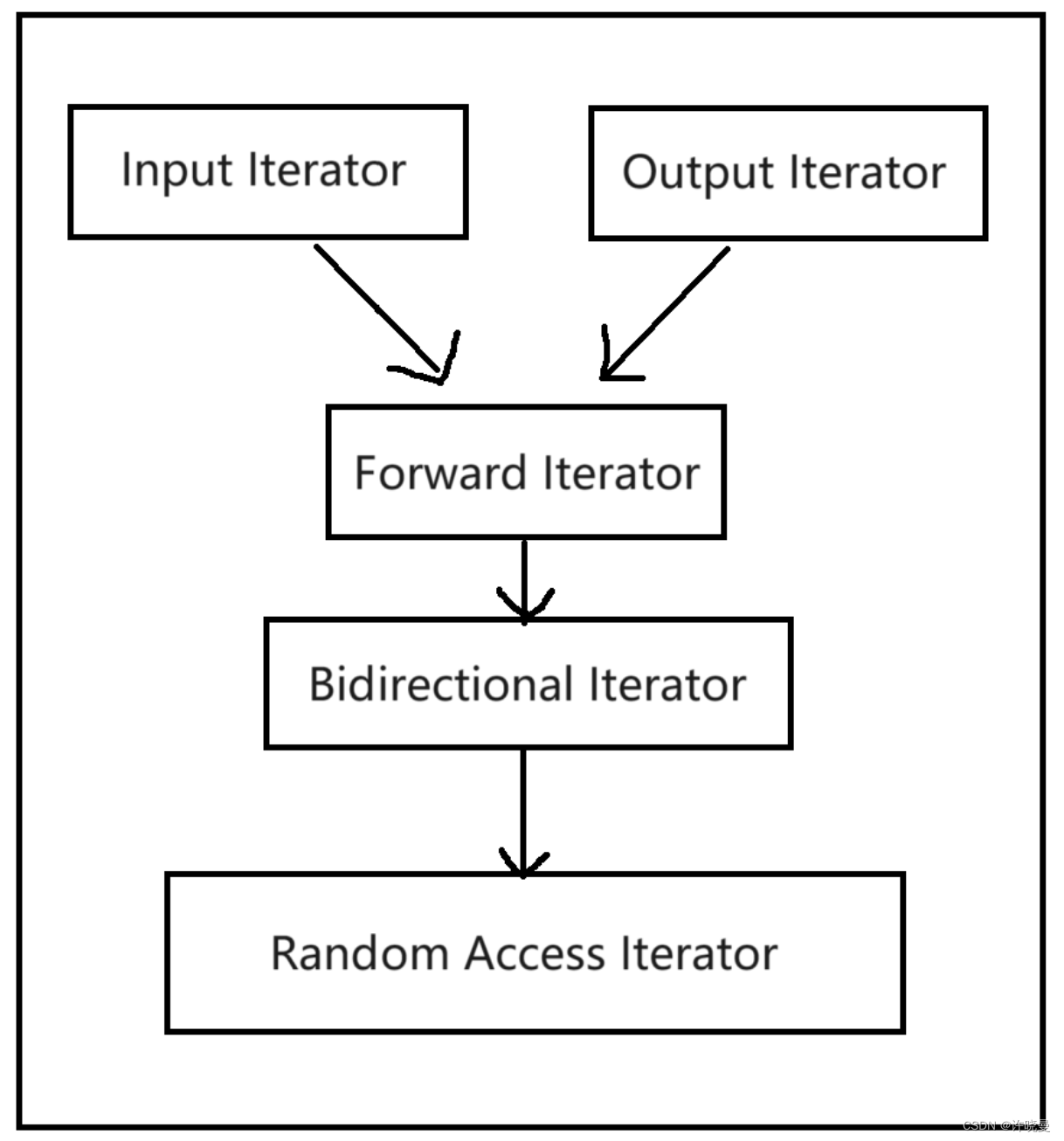
设计算法时,如果可能,我们尽量针对图中的某种迭代器提供一个明确定义,并针对更强化的某种迭代器提供另一种定义,这样才能在不同情况下提供最大效率。
假设有个算法可接受 Forward lterator,你以 Random Access lterator 喂给它它当然也会接受,因为一个 Random Access lterator 必然是一个 Forward lterator。但是可用并不代表最佳!
以advanced()为例
该函数有两个参数,迭代器p和数值n;函数内部将p累进n次(前进n距离)。下面有三份定义,一份针对 Input lterator,一份针对 Bidirectional lterator,另一份针对Random Access lterator。倒是没有针对 Forwardlterator 而设计的版本,因为那和针对 Input Iterator 而设计的版本完全一致。
template<class InputIterator, class Distance> // InputIterator版本
void advanced_II(InputIterator& i, Distance n)
{// 单向,逐一前进while(n--) ++i;
}template<class BidirectionalIterator, class Distance>
void advanced_BI(BidirectionalIterator& i, Distance n)
{// 双向,逐一前进if(n >= 0)while(n--) ++i;elsewhile (n++) --i;
}template<class RandomAccessIterator, class Distance>
void advanced_RAI(RandomAccessIterator& i, Distance n)
{// 双向,跳跃前进i += n;
}
现在,当程序调用 advance()时,应该选用(调用)哪一份函数定义呢?如果选择 advance_II(),对 Random Access lferator 而言极度缺乏效率,原本 O(1)的操作竟成为〇(N)。如果选择advance_RAI(),则它无法接受 Input lterator。我们需要将三者合一,下面是一种做法:
template<class InputIterator, class Distance>
void advance(InputIterator& i, Distance n)
{if(is_random_access_iterator(i)) // 此函数有待设计advance_RAI(i, n);else if(is_bidirectional_iterator) // 此函数有待设计advance_BI(i, n);elseadvance_II(i, n);
}
但是这种写法,程序在执行时期才能确定使用哪一个版本,会影响程序效率。最好能够在编译器就选择正确的版本,函数重载可以达成这个目标。
前述三个advance_xx()都有两个函数参数,型别都未定(因为都是template参数)。为了令其同名,形成重载函数,我们必须加上一个型别已确定的函数参数使函数重载机制得以有效运作起来。
设计考虑如下:如果iterator_traits有能力萃取出选代器的种类,我们便可利用这个迭代器类型”相应型别作为advanced()的第三参数。
我们定义五个类,代表五种迭代器类型:
// 五个作为标记用的类型(tag types)
struct input_iterator_tag {};
struct output_iterator_tag {};
struct forward_iterator_tag : {};
struct bidirectional_iterator_tag : {};
struct random_access_iterator_tag : {};
这些类只作为标记用,所以不需要任何成员。现在重新设计__advanced()(由于只在内部使用,所以函数名称加上特定的前导符),并加上第三参数,使它们构成重载。
template<class InputIterator, class Distance>
inline void __advance(InputIterator& i, Distance n, input_iterator_tag)
{// 单向,逐一前进while(n--) ++i;
}// 这是一个单纯的传调用函数。
template<class InputIterator, class Distance>
inline void __advance(InputIterator, Distance, forward_iterator_tag)
{// 单纯地进行传递调用__advanced(i, n, input_iterator_tag())
}template<class InputIterator, class Distance>
inline void __advance(InputIterator& i, Distance n, bidirectional_iterator_tag)
{// 双向,逐一前进if(n >= 0)while(n--) ++i;elsewhile (n++) --i;
}template<class InputIterator, class Distance>
inline void __advance(InputIterator& i, Distance n, random_access_iterator_tag)
{// 双向,跳跃前进i += n;
}
注意上述语法,每个__advance()的最后一个参数都只声明型别,并未指定参数名称,因为它纯粹只是用来激活重载机制,函数之中根本不使用该参数。如果硬要加上参数名称也可以,画蛇添足罢了。
行进至此,还需要一个对外开放的上层控制接口,调用上述各个重载的__advance()。这一上层接口只需两个参数,当它准备将工作转给上述的__advance()时,才自行加上第三参数:迭代器类型。因此,这个上层函数必须有能力从它所获得的迭代器中推导出其类型——这份工作自然是交给iterator_traits:
template<class InputIterator, class Distance>
void advanced(InputIterator& i, Distance n)
{__advanced(i, n, iterator_traits<InputIterator>::iterator_category())
}
因此,为了满足上述需求,iterator_traits必须再增加一个相应的类型:
template<class I>
struct iterator_traits
{// ...typdef typename I::iterator_category iterator_category;
};// 特化版本,注意原生指针是一种Random Access Iterator
template<class I>
struct iterator_traits<I*>
{// ...typdef random_access_iterator_tag iterator_category;
};template<class I>
struct iterator_traits<const I*>
{// ...typdef random_access_iterator_tag iterator_category;
};
你可能会有疑问,为什么上层的advance()的模板参数名称是InputIterator?按说advanced()可以接受任何类型的迭代器,为什么偏偏以InputIterator作为模板参数的名称?
这其实是STL算法的一个命名规则:以算法所能接受的最低阶迭代器类型,来为其他迭代器类型参数命名。
至此,我们便完成了我们的需求,但我们还可以对它进行优化:我们能否取消单纯传递调用的函数,即上面的inline void __advance(InputIterator, Distance, forward_iterator_tag),而让参数类型为forward_iterator_tag的直接去调用void __advance(InputIterator& i, Distance n, input_iterator_tag)?这就是下一节的内容。
取消单纯传递调用的函数
解决此问题的办法是:继承机制。
我们只需要为标记类型设置一定的继承关系,就可以达到目的。
// 五个作为标记用的类型(tag types),加入继承
struct input_iterator_tag {};
struct output_iterator_tag {};
struct forward_iterator_tag : public input_iterator_tag {};
struct bidirectional_iterator_tag : public forward_iterator_tag {};
struct random_access_iterator_tag : public bidirectional_iterator_tag {};
这样设置之后我们就可以删掉上述的nline void __advance(InputIterator, Distance, forward_iterator_tag),当我们传递的第三个参数类型为forward_iterator_tag时,会发生切片,自动去调用void __advance(InputIterator& i, Distance n, input_iterator_tag)。同时这种机制也保证了任何一个迭代器,其类型永远落在“该迭代器所隶属的各种类型种,最强化的那一个”,例如:int* 既是forward_iterator_tag,也是input_iterator_tag,也是bidirectional_iterator_tag,还是random_access_iterator_tag,那么,其类型应该归属为random_access_iterator_tag。
这样我们就干净利索地完成了所有任务。下面我们再以一个与advanced()相似的函数来帮助大家巩固理解“迭代器类型标签”
以distance()为例
该函数是一个迭代器操作函数,用来计算两个迭代器之间的距离。针对不同地迭代器类型,它可以由不同的计算方式,带来不同的效率。整个设计模式与advanced()如出一辙。
template<class InputIterator>
inline typename iterator_traits<InputIterator>::difference_type __distance(InputIterator first, InputIterator last, input_iterator_tag)
{typename iterator_traits<InputIterator>::difference_type n = 0;// 逐一累计距离while(first != last){++n;++first;}return n;
}template<class InputIterator>
inline typename iterator_traits<InputIterator>::difference_type __distance(InputIterator first, InputIterator last, random_access_iterator_tag)
{// 直接计算差距return last - first;
}template<class InputIterator>
typename iterator_traits<InputIterator>::difference_type distance(InputIterator first, InputIterator last)
{return __distance(first, last, iterator_traits<InputIterator>::iterator_category());
}
注意,distance()可接受任何类型的选代器;其template型别参数之所以命名为Inputterator,是为了遵循STL 算法的命名规则:以算法所能接受之最初级类型来为其迭代器型别参数命名。此外也请注意,由于迭代器类型之间存在着继承关系,“传递调用(forwarding)”的行为模式因此自然存在——这一点在前一节讨论过。换句话说,当客端调用distance()并使用Forwardlterators或Bidirectional lterators时,统统都会传递调用Inputlterator版的那个distance()函数。
std::iterator的保证
为了符合规范,任何迭代器都应该提供五个内嵌响应型别,以利于iterator_traits萃取。所以STL提供了一个iterator类如下,如果每个新设计的迭代器都继承自它,就可保证符合STL之需。
template<class Gategory, class T, class Distance = ptrdiff_t, class Pointer = T*, class Reference = T&>
struct iterator
{typedef Gategory iterator_catrgory;typedef T value_type;typedef Distance difference_type;typedef Pointer pointer;typedef Reference reference;
}
iterator类不含任何成员,纯粹只是型别定义,所以继承它并不会招致任何额外负担。由于后三个参数皆有默认值,故新的选代器只需提供前两个参数即可。
总结:
设计适当的相应型别(associated types),是选代器的责任。设计适当的迭代器,则是容器的责任。唯容器本身,才知道该设计出怎样的选代器来遍历自己,并执行迭代器该有的各种行为(前进、后退、取值、取用成员…)。至于算法,完全可以独立于容器和迭代器之外自行发展,只要设计时以迭代器为对外接口就行。
struct iterator
{typedef Gategory iterator_catrgory;typedef T value_type;typedef Distance difference_type;typedef Pointer pointer;typedef Reference reference;
}
iterator类不含任何成员,纯粹只是型别定义,所以继承它并不会招致任何额外负担。由于后三个参数皆有默认值,故新的选代器只需提供前两个参数即可。
总结:
设计适当的相应型别(associated types),是选代器的责任。设计适当的迭代器,则是容器的责任。唯容器本身,才知道该设计出怎样的选代器来遍历自己,并执行迭代器该有的各种行为(前进、后退、取值、取用成员…)。至于算法,完全可以独立于容器和迭代器之外自行发展,只要设计时以迭代器为对外接口就行。
traits 编程技法大量运用于STL实现品中。它利用“内嵌型别”的编程技巧与编译器的 template 参数推导功能,增强C++未能提供的关于型别认证方面的能力,弥补 C++ 不为强型别(strong typed)语言的遗憾。了解traits编程技法,就像获得“芝麻开门”的口诀一样,从此得以一窥 STL源代码堂奥。
这篇关于C++:Traits编程技法在STL迭代器中的应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





