本文主要是介绍来自工业界的知识库 RAG 服务(三),FinGLM 竞赛获奖项目详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景介绍
前面介绍过工业界的 RAG 服务 QAnything 和 RagFlow 的详细设计,也介绍过来自学术界的 一些优化手段。
前一阵子刚好看到智谱组织的一个金融大模型比赛 FinGLM,主要做就是 RAG 服务的竞赛,深入研究了其中的几个获奖作品,感觉还是有不少亮点。整理一些获奖项目的设计方案,希望对大家有所启发。
FinGLM 比赛
FinGLM 比赛介绍
FinGLM 是基于一定数量的上市公司财报构建知识库,使用 ChatGLM-6B 作为大模型完成知识库问答。需要回答的问题包含三类:
- 初级问题,可以直接从原文中获得信息进行回答,比如直接问特定公司某一年的研发费用,考察的是能否正确检索到内容的能力;
- 中级问题,需要对原文中内容进行统计分析和关联,比如问某公司某一年研发费用的增长率,考虑的是能否检索到内容并进行二次加工得到结果的能力;
- 高级问题,安全开放的问题,比如问研发项目是否涉及国家战略,考察的是检索到内容并综合处理的能力;
可以看到使用一个相对小的大模型 ChatGLM-6B,需要能准确回答上面的这些问题,对于内容的检索以及架构精细设计要求还是很高的,直接使用 最原始的 RAG 框架 肯定是不够的, 发挥不稳定的向量检索大概率是无法帮你获奖的。
比赛难点
我根据决赛答辩过程中的一些反馈,整理此比赛中的一些难点:
- 财报中包含大量的数据,掺杂文本内容与表格数据,很多精细的问题都需要依赖表格进行回答,如何进行精细的处理,保证原始文档中的内容可以正确检索到;
- 不同类型的问题需要不同的处理方案,如何区分不同的问题进行有针对性的解决;
- ChatGLM-6B 模型较弱,稍微复杂的情况就无法正确处理,甚至模型的输出就不可控了,如果保证稳定输出正确的答案;
- 用户问题与文档使用中词汇可能不是完全一致的,这会导致精确的检索更加困难;
获奖项目介绍
在天池的 决赛文章 可以看到最终获奖的队伍,本文主要想介绍的是项目是决赛获得第三名的 “ChatGLM反卷总局” 团队的项目,为什么没有选择前面的团队的项目,主要原因是:“ChatGLM反卷总局” 是获奖作品中性价比最高的实现方案:
- 其他团队或多或少都做了模型的微调,甚至获得第一名团队微调了 2 到 3 个模型,“ChatGLM反卷总局” 没有做任何的微调就取得了不错的成绩;
- 在原始 chatGLM 做关键词提取效果很差的情况下,其他团队都是靠微调解决,“ChatGLM反卷总局” 基于原始模型 + 正则表达式就实现了不错的效果;
- 实现方案比较轻量,没有引入太多额外的服务,生产环境可以方便应用;
项目方案详解
方案设计
项目设计的整体流程如下所示:
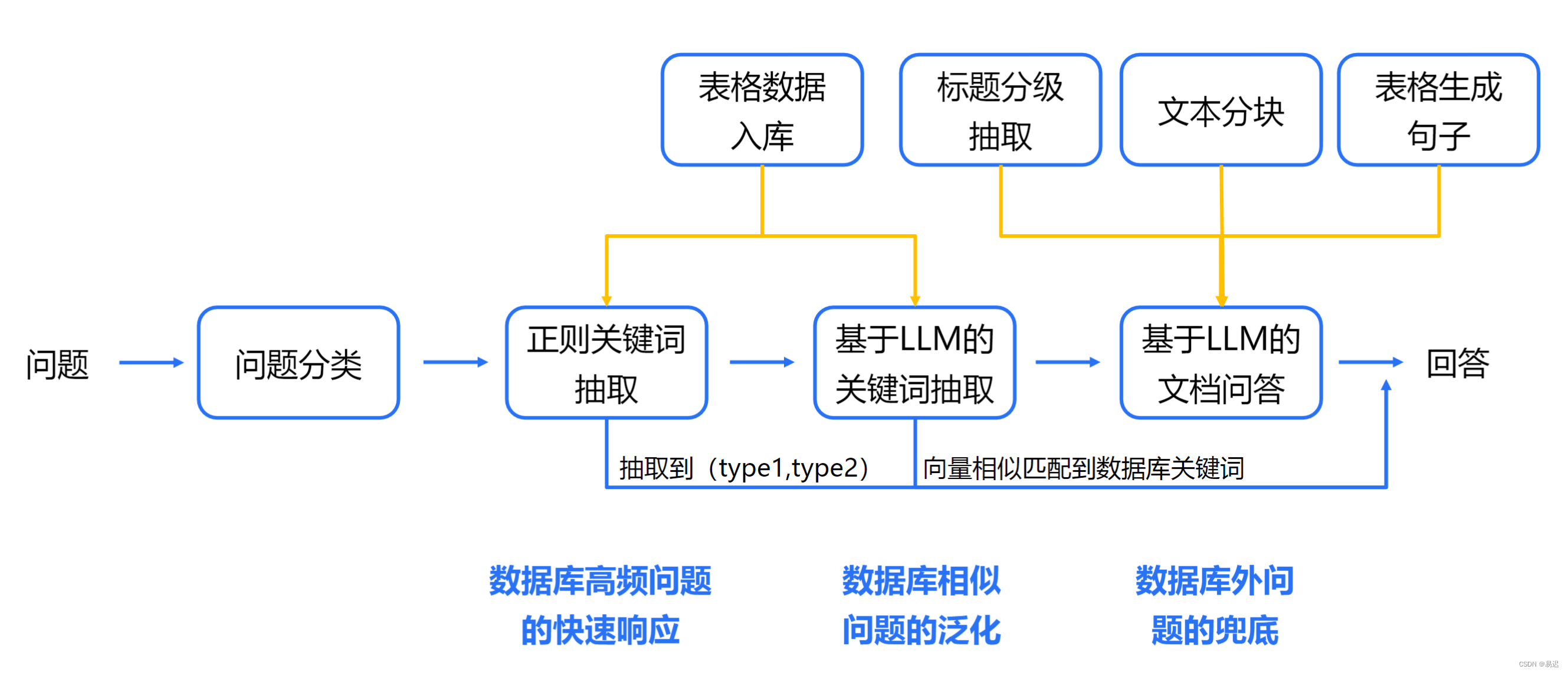
整理流程主要包含三个核心模块:
- 问题分类,不同类型的问题需要采取的方案完全不同,在选择处理方案时需要先确定是什么类型的问题,方便进行有针对性的处理;
- 关键词抽取,因为内容的检索主要使用关键词检索,因此需要从原始问题中提取对应的关键词;
- 表格与文档内容的检索与回答,根据问题类型的不同从不同来源获取数据,并执行必要的外部处理(主要是额外的数学计算),处理后提供给大模型得出最终结果;
问题分类
不同类型的问题存在不同的处理方案,因此在回答前需要先进行分类,分类的正确性对结果影响很大。分类一般是根据实际的测试问题进行归纳总结得出类型和判断依据, 之后就可以自动化分类。这部分不少团队是通过微调 chatGLM 模型实现线上分类的。
此项目是基于简单的规则判断,这个只能算是一个取巧方案,没有太多可说的东西。可以简单看看对应的实现:
if '保留' in q['question'] and com_match != '':question_type = 'calculate'
elif com_match != '' and len(year_match) > 0 and ('分析' in q['question'] or '介绍' in q['question'] or '如何' in q['question'] or '描述' in q['question'] or '是否' in q['question'] or '原因' in q['question'] or '哪些' in q['question'] or len(com_normal_keywords) > 0) and '元' not in q['question'] and len(com_info_keywords) == 0:question_type = 'com_normal'
elif com_match != '' and len(year_match) > 0:question_type = 'com_info'
elif com_match == '' and judge_tongji(q['question']):question_type = 'com_statis'
else:question_type = 'normal'q['question_type'] = question_type
if '增长率' in q['question']:q['question_type'] = 'com_info'代码有点糙,应该是根据实际问题总结出来的。但是在实际生产环境中,如果问题分类可以通过简单规则直接区分出来,确实没必要做大模型的微调或复杂的意图识别了。
关键词抽取
常规的 RAG 服务一般是基于向量进行检索,但是此项目主要使用的是关键词进行检索,支持了关键词 + 向量的混合检索,貌似决赛还因为镜像过大最终没有使用向量检索,因此主要依赖的就是关键词检索。
而关键词抽取的效果直接影响关键词检索的效果,因此这一步相当重要,此项目使用的两种方案:
- 正则关键词抽取;
- 基于 LLM 的关键词抽取
同一内容在问题中的使用的关键词可能与文档中使用的关键词存在一些差异,因此还需要进行关键词的泛化。
正则关键词提取
正则关键词的提取完全是通过已有的关键词表进行匹配得到的,效果优劣与原始的关键词表的覆盖范围有很大关系。具体的实现简化如下:
# 各个来源的关键词列表汇总find_keywords = list(attr_mapping_title.keys() | gongshi_mapping.keys() | com_normal_attr_mapping_title.keys())
find_keywords.sort(key=len, reverse=True)# 构建正则表达式,可以匹配关键词表中存在的关键词attr_regex_pattern = r'(?:' + '|'.join(find_keywords) + r')'
attr_regex = re.compile(attr_regex_pattern, re.IGNORECASE)# 从原始问题 q 中提取关键词,并实施去重attr_match = attr_regex.findall(q['question'])
attr_match.extend(attr_regex.findall(q['question'].replace('的','')))
keywords = list(set(attr_match))
这个是通过简单的匹配覆盖常规的关键词提取,主打的就是快,即使无法命中也有 LLM 提取关键词兜底。
基于 LLM 的关键词提取
常规的 ChatGLM-6B 模型较小,抽取关键词的效果很可能不佳。常规方案是构造训练数据进行微调,但是此项目用了一种有意思的方案:
项目使用 Few Shot 去提升 ChatGLM-6B 的提取关键词的效果,与常规 Few Shot 不同在于,构造的 Few Shot 是放在历史聊天记录中的,而不是拼接在 prompt 中的。
对应的实现简化后如下所示:
cls_history = [("现在你需要帮我完成信息抽取的任务,你需要帮我抽取出句子中三元组,如果没找到对应的值,则设为空,并按照JSON的格式输出", '好的,请输入您的句子。'),("<year><company>电子信箱是什么?\n\n提取上述句子中的关键词,并按照json输出。", '{"关键词":["电子信箱"]}'),("根据<year>的年报数据,<company>的公允价值变动收益是多少元?\n\n提取上述句子中的关键词,并按照json输出。",'{"关键词":["公允价值变动收益"]}'),("<company>在<year>的博士及以上人员数量是多少?\n\n提取上述句子中的关键词,并按照json输出。",'{"关键词":["博士及以上人员数量"]}'),("<company><year>年销售费用和管理费用分别是多少元?\n\n提取上述句子中的关键词,并按照json输出。",'{"关键词":["销售费用","管理费用"]}'),("<company><year>的衍生金融资产和其他非流动金融资产分别是多少元?\n\n提取上述句子中的关键词,并按照json输出。",'{"关键词":["衍生金融资产","其他非流动金融资产"]}'),...
]prompt = f'{question}\n\n提取上述句子中的关键词,并按照json输出。'response, history = model.chat(tokenizer, prompt, history=cls_history, top_p=0.7, temperature=1.0)
通过这种方案,最终大模型提取关键词的表现更稳定,下面的团队给出的对比情况:


关键词泛化
因为原始问题中的关键词与实际文档中的关键词不是完全一致的,此时就无法正确匹配到文档中内容,因此需要执行必要的泛化,从而提升匹配的概率。
项目是通过 fuzzywuzzy 实现的,此项目目前已经迁移至 thefuzz 了,思路是通过 Levenshtein_distance 实现模糊的字符串匹配,其实就是基于编辑距离确定字符串的相似度。
项目中的关键词泛化的实现如下所示:
from fuzzywuzzy import processdef find_best_match_new(question, mapping_list, threshold=40):# 与系统中关键词列表通过编辑距离进行匹配matches = process.extract(question, mapping_list)# 使用阈值进行过滤,并按照相似度进行排序best_matches = [match for match in matches if match[1] >= threshold]best_matches = sorted(best_matches, key=lambda x: (-x[1], -len(x[0])))# 返回最匹配的内容和得分match_score = 0total_q = ""if len(best_matches) > 0:total_q = best_matches[0][0]match_score = best_matches[0][1]return total_q, match_score
数据库与文档内容的检索与回答
表格数据检索与回答
表格数据是在预处理阶段提取出来,保存在 excel 文件中,初始化时转换为 pandas 对象进行检索。
通过前面的关键词提取与泛化后,得到的关键词与文档中的关键词就保持一致了,此时通过关键词就可以准确地匹配所需的内容。这部分就可以看到精确匹配的优势所在,处理得当的情况下结果相对准确。
除了简单直接匹配表格数据的情况,实际问题中还存在需要通过公式计算最终结果的情况,是否能直接提供原始数据给 chatGLM-6B 进行计算呢,这个就有点强 GPT 所难了,实际测试往往容易出错。
目前是通过外部提取所需的原始后直接调用 Python 进行计算,具体的实现如下所示:
financial_formulas = {"研发经费与利润比值": (["研发费用", "净利润"], "研发费用 / 净利润"),"企业研发经费占费用": (["销售费用", "财务费用", "管理费用", "研发费用"], "研发费用 / (研发费用+管理费用+财务费用+销售费用)"),"研发人员占职工": (["研发人员", "职工人数"], "研发人员 / 职工人数"),"硕士及以上学历人员占职工": (["研发人员", "职工人数"], "研发人员 / 职工人数"),"流动比率": (["流动资产合计", "流动负债合计"], "流动资产合计 / 流动负债合计"),"速动比率": (["流动资产合计", "存货", "流动负债合计"], "(流动资产合计 - 存货) / 流动负债合计"),"硕士及以上人员占职工": (["硕士以上人数", "职工人数"], "硕士以上人数 / 职工人数"),"研发经费与营业收入比值": (["研发费用", "营业收入"], "研发费用 / 营业收入"),...
}# 根据关键词获得所需的公式项formula_data = financial_formulas[index_name]
data_values = {}# 获取计算所需的原始数据finance_data = dq.get_financial_data(year_, stock_name)# 将原始数据与公式所需的元素组合为键值对for field in formula_data[0]:value = finance_data.get(field)data_values[field] = value# 获取对应的公式计算字符串formula_str = formula_data[1]
calculation_str = formula_str.replace(" ", "")
for key, value in data_values.items():calculation_str = calculation_str.replace(key, str(value))# 调用 Python 执行计算result_value = eval(calculation_str)
文本数据检索与回答
对于文本检索,大量的信息会存在文本的各级标题中,而常规的文件分片中除了与标题直接相连的分片,其他分片中标题的信息是缺失的,效果类似如下所似:

为了解决这个问题,项目会通过正则表达式识别标题行,之后通过堆栈记录标题层级结构,在各个分片中增加标题信息,实现流程如下所示:

通过上面的修复,最终各个分片中都会包含各级标题的信息,检索更容易命中。修复后分片效果如下所示:

分片的数据是保存在 ES 中的,这样就可以比较方便的实现关键词检索,实际检索时关键词命中标题或文本内容都能被正确召回。效果如下所示:

实际的文本召回实现就相对简单了,只是 ES 客户端的简单调用:
def get_context(company, final_year, query, size=3, es_index="tianchi", keyword="", recall_titles={}, title_keyword=""):force_search_body = {"size": size,"_source": ["texts"],"query": {"bool": {"filter": [{"term": {"companys": company}},{"terms": {"year": final_year}},]}},}# 构造 query 检索force_search_body["query"]["bool"]["should"] = [{"match": {"texts": {"query": query}}}]# 额外的关键词检索增强if len(keyword) > 0:force_search_body["query"]["bool"]["should"].append({"match_phrase": {"texts": {"query": keyword}}})force_search_body["query"]["bool"]["filter"].append({"terms": {"titles_cut.keyword": recall_titles[keyword]}})if len(title_keyword) > 0:force_search_body["query"]["bool"]["should"].append({"match": {"titles_cut": {"query": title_keyword}}})# ES 检索调用search_result = es.search(index=es_index, body=force_search_body)hits = search_result["hits"]["hits"]recall_texts = [hit["_source"]["texts"] for hit in hits]return recall_texts
总结
本文对 “ChatGLM反卷总局” 在 FinGLM 比赛的项目进行了详细解读。比赛中获奖的项目往往会采取各种奇技淫巧的,毫无疑问大部分手段在当前项目都是有效的(要不然就无法获奖了),但是往往过于定制化,无法应用在常规的生产环境中,这个在 FinGLM 的很多获奖项目中都有看到。
在实际了解 “ChatGLM反卷总局” 项目过程中,有两个亮点可能对 RAG 的生产环境有不错的借鉴意义:
- 特殊的 Few Shot 设计,将 Few Shot 内容构造至聊天历史中,相对直接放入 prompt 中存在明显提升;
- 层次化的文件解析,将各级文件标题拼接至文件分片中,可以大幅提升文档召回率;
这篇关于来自工业界的知识库 RAG 服务(三),FinGLM 竞赛获奖项目详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






