本文主要是介绍【学习】前端模块化——SeaJS和RequireJS,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前面
之前没学过nodeJS,底子不好,对AMD和CMD的实现没法理解,现在nodeJS也算是步入门槛,再回过身好好研究一下这个“模块化加载器”。
SeaJS与RequireJS最大的区别
一言以蔽之:执行模块的机制大不一样
RequireJS 是执行的 AMD 规范, 所有的依赖模块都是先执行,当然 RequireJS 从 2.0 开始,也改成可以延迟执行(根据写法不同,处理方式不同)。这点和常规的nodeJS风格很像,模块编写前把所有用到的依赖模块率先在头部注入进来,然后需要调用的时候就可以直接拿来用。后端语言大多是这个编码思路,比较好接受。而SeaJS对模块的态度是懒执行( As lazy as possible),这样有四个好处:
1、防止对象被提前创建(内存优化,如加载plist文件等耗内存的操作)
2、防止对象重复创建 (永远只加载一次)
3、防止对象使用时,还没被创建
4、可以在懒加载方法里面,进行初始化操作
举个简单的例子:
// CMD
define(function(require, exports, module) { var a = require('./a') a.doSomething() // 此处略去 100 行 var b = require('./b') // 依赖可以就近书写 b.doSomething() // ...
}) // AMD 默认推荐的是
define(['./a', './b'], function(a, b) { // 依赖必须一开始就写好 a.doSomething() // 此处略去 100 行 b.doSomething() ...
}) 注意,上面也提到了requireJS也支持CMD写法,同时还支持将 require 作为依赖项传递,但 RequireJS 的作者默认是最喜欢上面的写法,也是官方文档里默认的模块定义写法。
此外,AMD 的 API 默认是一个当多个用,CMD 的 API 严格区分,推崇职责单一。比如 AMD 里,require 分全局 require 和局部 require,都叫 require。CMD 里,没有全局 require,而是根据模块系统的完备性,提供 seajs.use 来实现模块系统的加载启动。CMD 里,每个 API 都简单纯粹。
豆瓣一个有名的帖子
如下模块分别通过SeaJS/RequireJS来加载:
define(function(require, exports, module) { console.log('require module: main'); var mod1 = require('./mod1'); mod1.hello(); var mod2 = require('./mod2'); mod2.hello(); return { hello: function() { console.log('hello main'); } };
}); SeaJS的执行结果
require module: main
require module: mod1
hello mod1
require module: mod2
hello mod2
hello main RequireJS执行结果
require module: mod1
require module: mod2
require module: main
hello mod1
hello mod2
hello main 小结
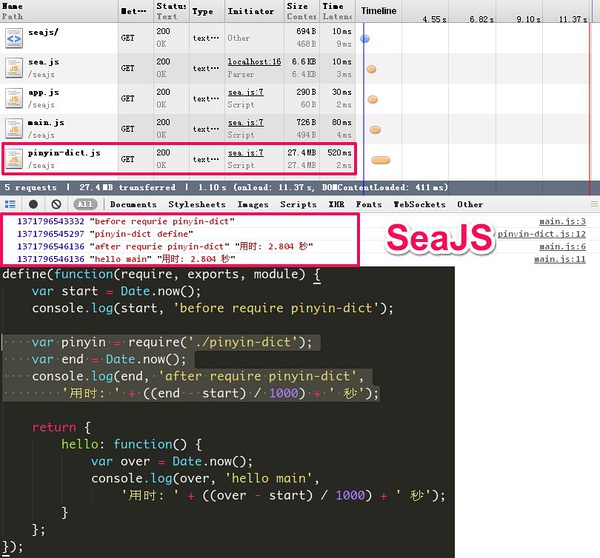
SeaJS只会在真正需要使用(依赖)模块时才执行该模块,SeaJS是异步加载模块的没错, 但执行模块的顺序也是严格按照模块在代码中出现(require)的顺序, 这样也许更符合逻辑。
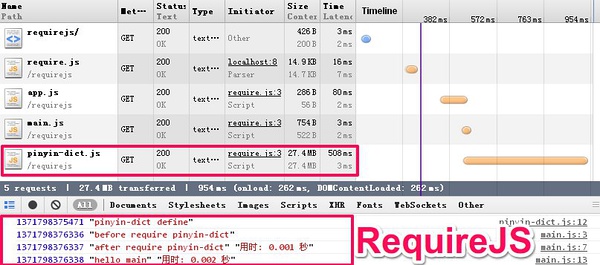
RequireJS会先尽早地执行(依赖)模块, 相当于所有的require都被提前了, 而且模块执行的顺序也不一定100%就是先mod1再mod2 。因此你看到执行顺序和你预想的完全不一样。
注意这里说的是执行(真正运行define中的代码)模块, 而非加载(load文件)模块。模块的加载都是并行的, 没有区别,区别在于执行模块的时机,或者说是解析。
阻塞问题
SeaJS的懒执行
RequireJS的预执行
小结
可以很明显的看出RequireJS的做法是并行加载所有依赖的模块, 并完成解析后, 再开始执行其他代码, 因此执行结果只会”停顿”1次, 完成整个过程是会比SeaJS要快.
而SeaJS一样是并行加载所有依赖的模块, 但不会立即执行模块, 等到真正需要(require)的时候才开始解析, 这里耗费了时间, 因为这个特例中的模块巨大, 因此造成”停顿”2次的现象, 这就是我所说的SeaJS中的”懒执行”.
总结
jockchou 的看法
我个人感觉requirejs更科学,所有依赖的模块要先执行好。如果A模块依赖B。当执行A中的某个操doSomething()后,再去依赖执行B模块require(‘B’);如果B模块出错了,doSomething的操作如何回滚?
很多语言中的import, include, useing都是先将导入的类或者模块执行好。如果被导入的模块都有问题,有错误,执行当前模块有何意义?
总之载入的所有模块,都是当前要使用的,为什么要动态的去执行?这个问题可以总结为模块的载入执行是静态还是动态。如果是动态执行的话,那页面的程序执行过程会受到当前模块执行的影响。而正如楼主所言,动态执行总体时间上是比静态一次执行要慢的。
楼主说requirejs是坑,是因为你还不太理解AMD“异步模块”的定义,被依赖的模块必须先于当前模块执行,而没有依赖关系的模块,可以没有先后。在楼主的例子中,假设mod1和mod2某天发生了依赖的话,比如在某个版本,mod1依赖了mod2(这是完全有可能的),这个时候seajs的懒执行会不会有问题?而requirejs是不会有问题,也不需要修改当前模块。
在javascript这个天生异步的语言中,却把模块懒执行,这让人很不理解。想像一下factory是个模块工厂吧,而依赖dependencies是工厂的原材料,在工厂进行生产的时候,是先把原材料一次性都在它自己的工厂里加工好,还是把原材料的工厂搬到当前的factory来什么时候需要,什么时候加工,哪个整体时间效率更高?显然是requirejs,requirejs是加载即可用的。为了响应用户的某个操作,当前工厂正在进行生产,当发现需要某种原材料的时候,突然要停止生产,去启动原材料加工,这不是让当前工厂非常焦燥吗?
暂且不去理会这个吧,等ECMA规范中加入了模块化的定义后,再看谁更合理吧。
玉伯 的观点
原文链接:https://www.zhihu.com/question/20342350/answer/14828786
RequireJS 和 SeaJS 都是很不错的模块加载器,两者区别如下:
1、两者定位有差异。RequireJS 想成为浏览器端的模块加载器,同时也想成为 Rhino / Node 等环境的模块加载器。SeaJS 则专注于 Web 浏览器端,同时通过 Node 扩展的方式可以很方便跑在 Node 服务器端
2、两者遵循的标准有差异。RequireJS 遵循的是 AMD(异步模块定义)规范,SeaJS 遵循的是 CMD (通用模块定义)规范。规范的不同,导致了两者 API 的不同。SeaJS 更简洁优雅,更贴近 CommonJS Modules/1.1 和 Node Modules 规范。
3、两者社区理念有差异。RequireJS 在尝试让第三方类库修改自身来支持 RequireJS,目前只有少数社区采纳。SeaJS 不强推,而采用自主封装的方式来“海纳百川”,目前已有较成熟的封装策略。
4、两者代码质量有差异。RequireJS 是没有明显的 bug,SeaJS 是明显没有 bug。
5、两者对调试等的支持有差异。SeaJS 通过插件,可以实现 Fiddler 中自动映射的功能,还可以实现自动 combo 等功能,非常方便便捷。RequireJS 无这方面的支持。
6、两者的插件机制有差异。RequireJS 采取的是在源码中预留接口的形式,源码中留有为插件而写的代码。SeaJS 采取的插件机制则与 Node 的方式一致:开放自身,让插件开发者可直接访问或修改,从而非常灵活,可以实现各种类型的插件。还有不少细节差异就不多说了。
总之,SeaJS 从 API 到实现,都比 RequireJS 更简洁优雅。如果说 RequireJS 是 Prototype 类库的话,则 SeaJS 是 jQuery 类库。最后,向 RequireJS 致敬!RequireJS 和 SeaJS 是好兄弟,一起努力推广模块化开发思想,这才是最重要的。
个人之见
AMD速度和效率比CMD快,虽然可能会存在不必要的内存开销,但是对于小项目来说,这些开销是可以忽略不计的,因为现在的硬件设备提升的速度很快,而且如果你早已养成良好的编码习惯,这些差异是肉眼无法捕捉到的,而且AMD思想比较符合常规的编程逻辑,更容易让前端工程师接受,学习成本低。
CMD的好处上面也讲了不少了,而且作为国产大头,我对它的发展还是很看好的,模块的单一职责和延迟加载特性使得代码变得优雅、容易维护。对于复杂的前端项目(如webApp),我还是会倾向于seaJS,它的编程思想更令我喜爱,奔着早日进军阿里的信念,很值得花时间去研读 seaJS的源码,去领悟这门框架的精髓,走近开发这门框架的牛人们的世界。
还是那句话,思想没有好坏之分,只有适不适合你的项目开发。
@参考 《LABjs、RequireJS、SeaJS 哪个最好用?为什么?》
这篇关于【学习】前端模块化——SeaJS和RequireJS的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







