本文主要是介绍在k8s中部署Logstash多节点示例(超详细讲解),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

🐇明明跟你说过:个人主页
🏅个人专栏:《洞察之眼:ELK监控与可视化》🏅
🔖行路有良友,便是天堂🔖
目录
一、引言
1、Logstash简介
2、在K8s中部署Logstash多节点实例的优势
二、Logstash概述
1、Logstash的主要组件
2、Logstash的配置文件结构和语法
三、准备部署环境
1、准备k8s集群
2、准备Logstash镜像
3、准备StorageClass
四、部署Logstash
1、编写YAML文件
2、部署Logstash多节点实例
一、引言
1、Logstash简介
Logstash 是一个开源的数据收集引擎,可以从多个来源实时收集、解析和传输日志数据到多个输出目标。它是由 Elastic 开发和维护的,通常与 Elasticsearch 和 Kibana 一起使用,形成称为 "ELK Stack" 或 "Elastic Stack" 的强大日志管理和分析系统。
Logstash 的主要功能
1. 数据收集(Inputs)
- Logstash 可以从多种数据源收集数据,包括日志文件、消息队列、数据库等。支持的输入插件种类繁多,如文件、syslog、TCP/UDP、HTTP、Kafka、JDBC 等。
2. 数据解析和过滤(Filters)
- 收集到的数据可以通过过滤器插件进行解析和转换。Logstash 提供了丰富的过滤器插件,例如:
- grok:用于解析和结构化文本数据。
- date:用于解析时间戳。
- mutate:用于重命名、移除和修改字段。
- geoip:根据 IP 地址添加地理位置数据。
3. 数据输出(Outputs)
- 处理后的数据可以发送到多个目的地,包括 Elasticsearch、文件、数据库、消息队列等。常用的输出插件包括 Elasticsearch、Kafka、HTTP、File、Email、STDOUT 等。
4. 实时处理
- Logstash 具备实时处理能力,可以在数据生成的同时进行收集、解析和传输,确保数据的及时性。
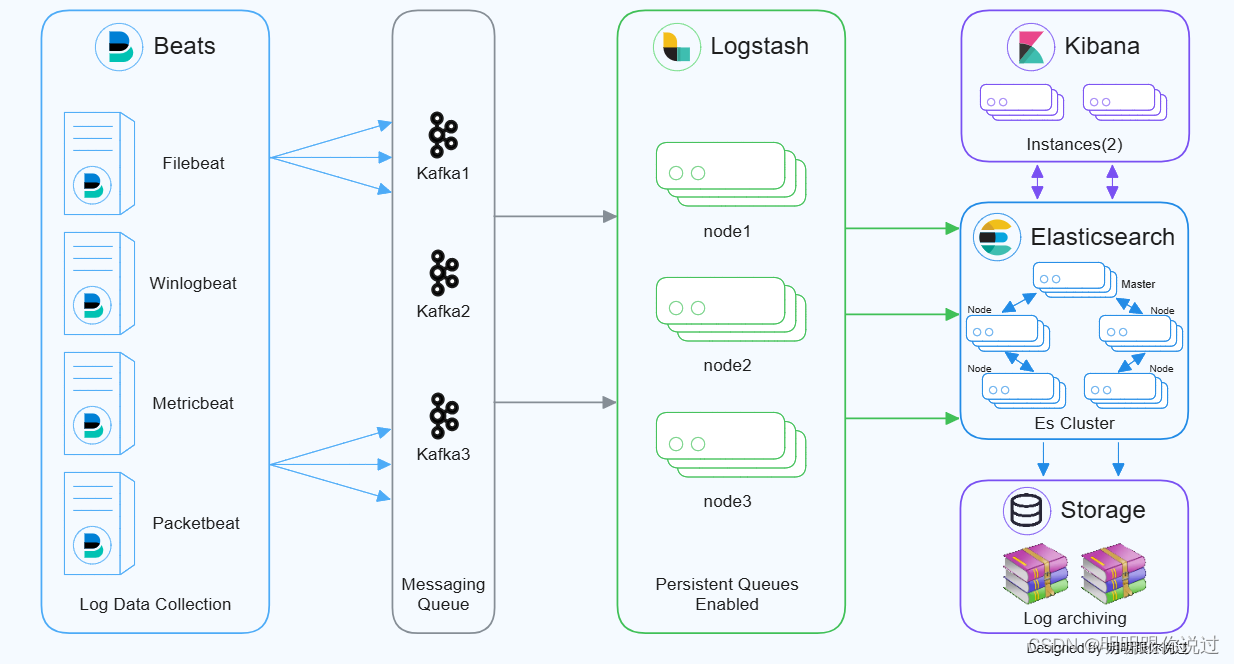
2、在K8s中部署Logstash多节点实例的优势
1. 高可用性和容错性
- 容器编排和自动恢复:Kubernetes 提供了容器编排和自动恢复功能。如果某个 Logstash 实例出现故障,Kubernetes 可以自动重新调度和重启容器,确保日志处理服务的持续可用性。
- 多副本部署:通过部署多个 Logstash 实例(副本),即使某些节点或容器出现故障,其他副本仍然可以继续处理日志,提供高可用性和容错能力。
2. 弹性伸缩
- 自动扩展:Kubernetes 的 Horizontal Pod Autoscaler 可以根据 CPU 使用率或自定义的指标(如日志处理延迟、队列长度)自动扩展或缩减 Logstash 实例的数量,确保在流量高峰期能够及时处理日志,同时在流量低谷期节省资源。
- 资源管理:Kubernetes 通过资源配额和限制(如 CPU 和内存的请求和限制)来高效管理资源,确保 Logstash 实例得到合理的资源分配。
3. 集中管理和监控
- 统一管理:在 Kubernetes 中,可以使用 Kubernetes 的控制面板(如 Kubernetes Dashboard 或其他监控工具)集中管理和监控所有 Logstash 实例,简化了运维管理。
- 日志和指标收集:Kubernetes 可以通过内置的日志和指标收集工具(如 Fluentd、Prometheus 等)集中收集和分析 Logstash 的运行状态和性能指标,及时发现和处理异常情况。
4. 灵活部署和滚动升级
- 滚动更新和回滚:Kubernetes 支持滚动更新和回滚功能,可以在不影响服务可用性的情况下更新 Logstash 实例的配置或版本,并在发生问题时快速回滚到上一版本。
- 灵活部署:可以通过 Kubernetes 配置文件(YAML 或 JSON)灵活定义 Logstash 的部署配置(如副本数量、环境变量、持久化存储、网络配置等),实现快速和一致的部署。
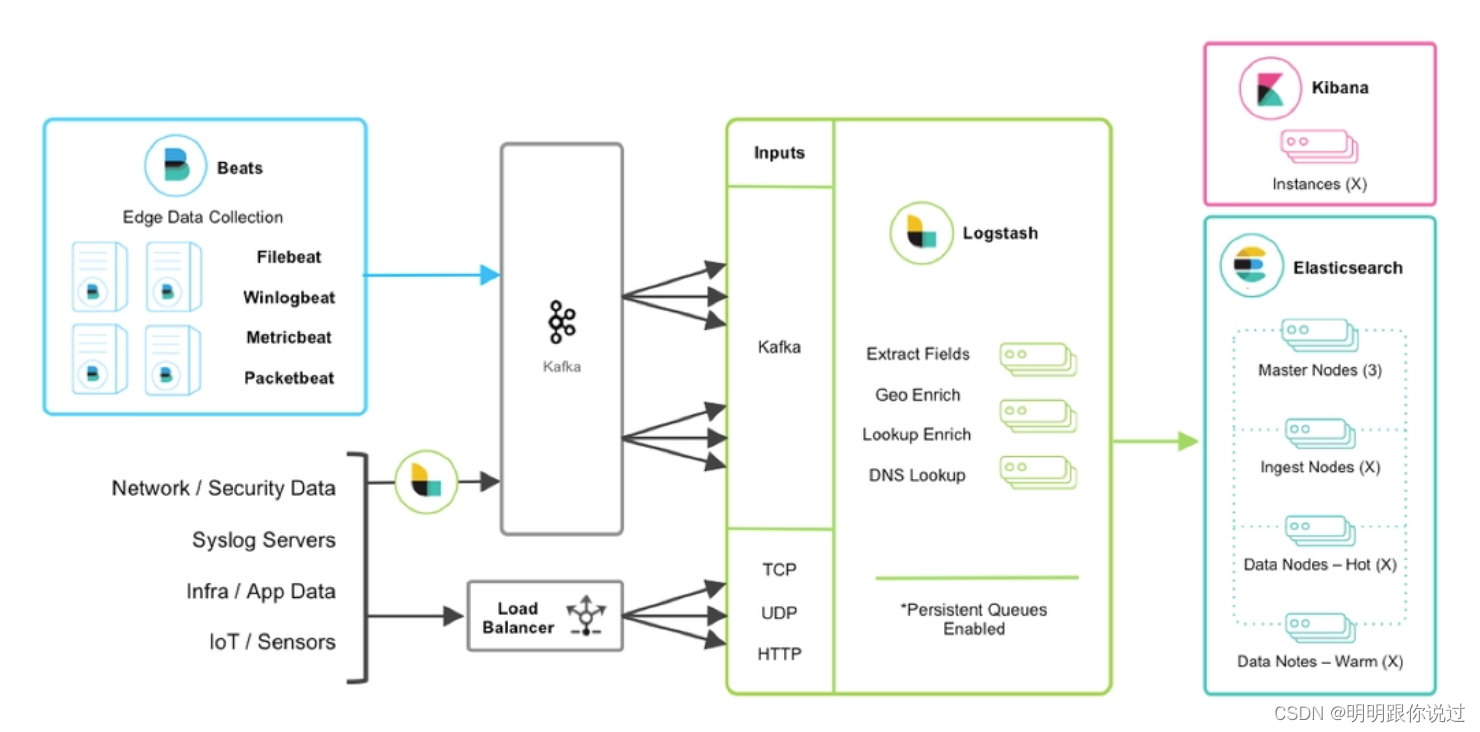
二、Logstash概述
1、Logstash的主要组件
Logstash 是一个功能强大的数据处理引擎,它的主要功能由三大核心组件组成:输入(Inputs)、过滤器(Filters)和输出(Outputs)。这些组件共同作用,使 Logstash 能够从多种来源收集数据,对数据进行处理和转换,并将处理后的数据传输到多个目标位置。
1. 输入(Inputs)
- 输入插件用于定义数据的来源。Logstash 可以从各种来源收集数据,包括文件、消息队列、数据库、网络协议等。
2. 过滤器(Filters)
- 过滤器插件用于对输入的数据进行处理和转换。可以使用过滤器插件来解析、增强、清洗和格式化数据。
3. 输出(Outputs)
- 输出插件定义数据的目的地。Logstash 可以将处理后的数据发送到多个目标位置,包括搜索引擎、数据库、文件、消息队列等。
工作流程
Logstash 的工作流程可以简要描述为:数据从输入端进入,通过过滤器进行处理和转换,最后通过输出端发送到目标位置。
- 输入阶段:Logstash 从配置的输入源收集数据。
- 过滤阶段:收集到的数据通过配置的过滤器进行解析、转换和增强。
- 输出阶段:处理后的数据被发送到配置的输出目标。
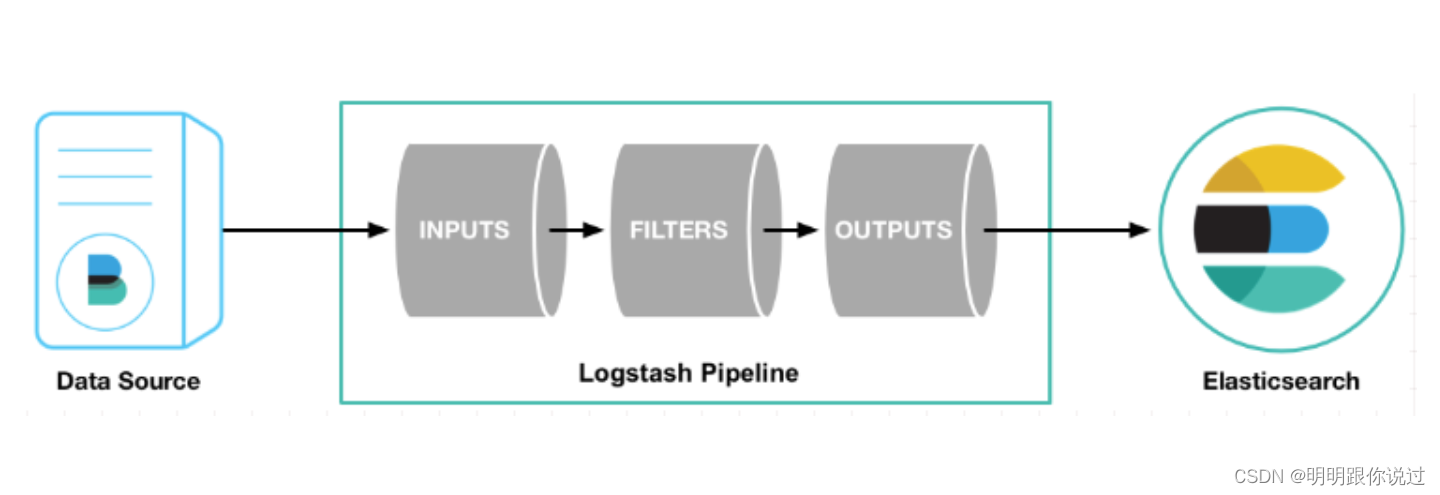
2、Logstash的配置文件结构和语法
Logstash 的配置文件使用 .conf 格式,定义了数据处理管道的三大主要组件:输入(Inputs)、过滤器(Filters)和输出(Outputs)。每个配置文件包含多个阶段,通过管道(pipeline)配置来组织这些组件。
配置文件结构
一个典型的 Logstash 配置文件结构如下:
input {# 输入插件配置
}filter {# 过滤器插件配置
}output {# 输出插件配置
}
配置语法
Logstash 配置文件的语法主要由插件、插件参数和条件表达式组成。以下是详细的说明:
1. 输入(Inputs)
输入插件定义数据的来源。每个输入插件都有自己的参数,用于指定数据源的详细信息。
input {file {path => "/var/log/syslog"start_position => "beginning"}beats {port => 5044}
}
2. 过滤器(Filters)
过滤器插件用于解析、转换和增强数据。过滤器插件可以有多个,每个过滤器都有其特定的参数。过滤器之间可以用条件表达式进行控制。
filter {grok {match => { "message" => "%{SYSLOGTIMESTAMP:timestamp} %{SYSLOGHOST:hostname} %{DATA:process}: %{GREEDYDATA:message}" }}date {match => [ "timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]}mutate {remove_field => [ "timestamp" ]}
}
3. 输出(Outputs)
输出插件定义数据的目的地。每个输出插件都有自己的参数,用于指定目标位置的详细信息。
output {elasticsearch {hosts => ["http://localhost:9200"]index => "syslog-%{+YYYY.MM.dd}"}stdout {codec => rubydebug}
}
三、准备部署环境
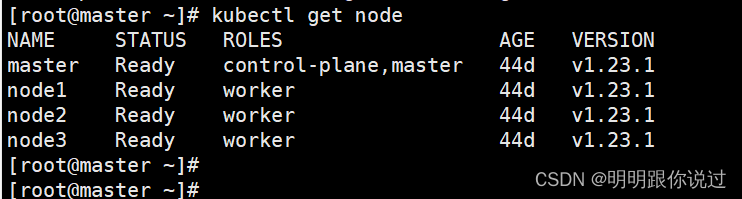
1、准备k8s集群
这里示范的k8s集群版本为1.23,也可以是其他版本,如果还未搭建k8s集群,请参考《在Centos中搭建 K8s 1.23 集群超详细讲解》这篇文章
2、准备Logstash镜像
拉取部署Logstash所需的Docker镜像,镜像我已经上传到资源列表了,大家直接下载后导入到k8s node节点即可
3、准备StorageClass
因为我们要对Logstash中的数据进行持久化,避免Pod漂移后数据丢失,保证数据的完整性与可用性
如果还未创建存储类,请参考《k8s 存储类(StorageClass)创建与动态生成PV解析,(附带镜像)》这篇文件。

四、部署Logstash
1、编写YAML文件
编写部署Logstash所需的YAML文件,这里我们设置节点的数量为3个,并设置Logstash从Kafka集群消费日志,然后将日志发送到es集群中
[root@master ~]# vim logstash.yaml
# 输入如下内容
apiVersion: v1
kind: Namespace
metadata:name: logstash
#创建Service
---
apiVersion: v1
kind: Service
metadata:name: logstash-cluster #无头服务的名称,需要通过这个获取ip,与主机的对应关系namespace: logstashlabels:app: logstash
spec:ports:- port: 5044name: logstashclusterIP: Noneselector:app: logstash
---
apiVersion: v1
kind: ConfigMap
metadata:name: logstash-confignamespace: logstashlabels:app: logstash
data: #具体挂载的配置文件test.conf: |+input{kafka {bootstrap_servers => "192.168.40.181:30092,192.168.40.181:30093,192.168.40.181:30094"topics => ["test"]group_id => "logstashGroup"}}output {elasticsearch {hosts => ["192.168.40.181:30000","192.168.40.181:30001","192.168.40.181:30002","192.168.40.181:30003","192.168.40.181:30004"]index => "test3" }}
---
apiVersion: apps/v1
kind: StatefulSet
metadata:name: logstashnamespace: logstash
spec:serviceName: "logstash-cluster" #填写无头服务的名称replicas: 3selector:matchLabels:app: logstashtemplate:metadata:labels:app: logstashspec:containers:- name: logstashimage: lm-logstash:7.17.18imagePullPolicy: Neverresources:requests:memory: "500Mi"cpu: "500m"limits:memory: "1000Mi"cpu: "1000m"command:- sh- -c- "exec /app/logstash-7.17.18/bin/logstash -f /app/logstash-7.17.18/config/test.conf"ports:- containerPort: 5044name: logstashenv:- name: node.namevalueFrom:fieldRef:fieldPath: metadata.name- name: ES_JAVA_OPTSvalue: "-Xms1g -Xmx1g"volumeMounts:- name: data #挂载数据mountPath: /data- name: logstash-configmountPath: /app/logstash-7.17.18/config/test.confsubPath: test.confvolumes:- name: logstash-configconfigMap: #configMap挂载name: logstash-config volumeClaimTemplates: #这步自动创建pvc,并挂载动态pv- metadata:name: dataspec:accessModes: ["ReadWriteMany"]storageClassName: nfsresources:requests:storage: 10Gi这个 StatefulSet 定义了一个名为 logstash 的应用,部署了三个副本。关键配置如下:
- serviceName 指定使用无头服务 logstash-cluster。
- 每个 Pod 都使用 lm-logstash:7.17.18 镜像,并从 ConfigMap 中挂载 test.conf 配置文件。
- 使用环境变量 node.name 和 ES_JAVA_OPTS 进行配置。
- 挂载了两个卷:一个用于数据存储,一个用于配置文件。
- volumeClaimTemplates 自动创建一个 data 的 PVC,每个 Pod 使用独立的 PV。
部署优势
- 高可用性:通过多副本 StatefulSet,确保 Logstash 的高可用性。
- 服务发现:使用无头服务和 StatefulSet,Kubernetes 自动管理 Pod 的 DNS 解析,使集群内其他服务能够轻松找到 Logstash 实例。
- 集中配置管理:通过 ConfigMap 管理配置文件,方便配置更新和版本控制。
- 持久存储:使用动态创建的 PV 和 PVC,确保数据持久化,避免因 Pod 重启或迁移导致的数据丢失。
2、部署Logstash多节点实例
执行下面的命令
[root@master ~]# kubectl apply -f logstash.yaml

查看Pod状态
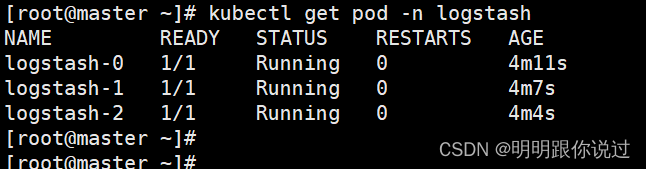
至此,Logstash多节点实例部署完成, 如果你有其他的建议和想法,欢迎在评论区留言
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些关于ELK的文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!
这篇关于在k8s中部署Logstash多节点示例(超详细讲解)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




