本文主要是介绍⌈ 传知代码 ⌋ AI驱动食物图像识别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
💛前情提要💛
本文是传知代码平台中的相关前沿知识与技术的分享~
接下来我们即将进入一个全新的空间,对技术有一个全新的视角~
本文所涉及所有资源均在传知代码平台可获取
以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦!!!
以下内容干货满满,跟上步伐吧~
📌导航小助手📌
- 💡本章重点
- 🍞一. 概述
- 🍞二. 创新点
- 🍞三. 整体流程
- 🍞四. 核心逻辑
- 🍞五. 核心逻辑
- 🫓总结
💡本章重点
- AI驱动食物图像识别
🍞一. 概述
本文档详细介绍了一项基于深度学习技术的食物图像分类研究项目。该项目旨在通过构建和训练深度学习模型,实现对食物图像的高效、准确分类。研究使用了卷积神经网络(CNN),特别是VGG16作为预训练模型,并通过自定义层进行微调以适应食物图像分类任务。项目通过Food-101数据集进行训练和测试,采用了数据增强技术以提高模型的泛化能力,并在实验中探讨了模型的性能和实用性。
算法预测结果如下所示:
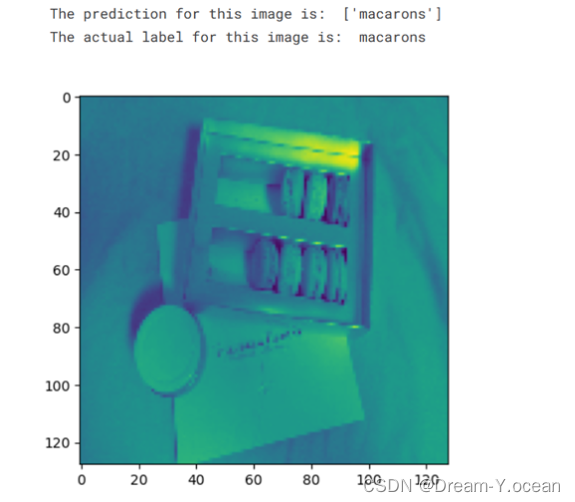
该图食物名称为通心粉
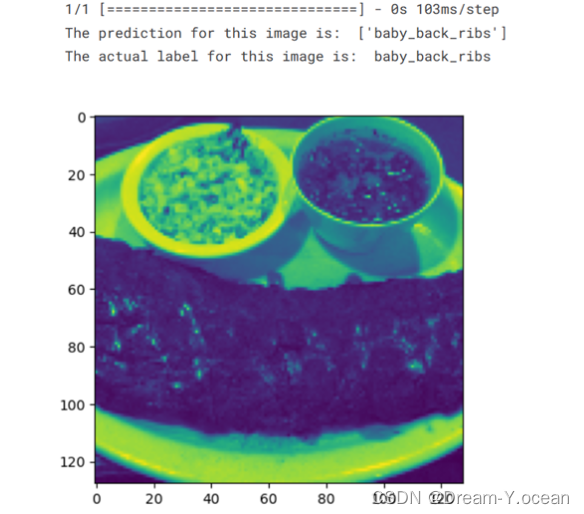
该图食物名称为baby_ribs,婴儿辅食。可以看到该算法对于各类食物识别的准确度。在训练集的acc达到了99%左右。
🍞二. 创新点
深度学习模型的改进与应用:
本项目采用了VGG16作为预训练模型,并通过自定义的特征提取层和分类层进行微调,以适应食物图像的复杂性和多样性。
通过迁移学习技术,利用在大规模数据集上预训练的模型,减少了对大量标注数据的依赖,同时提高了模型在新任务上的学习效率和性能。
数据预处理与增强技术:
实施了包括图像尺寸统一、颜色空间转换、旋转、翻转、缩放和裁剪等数据增强手段,有效提升了模型的泛化能力和对不同食物图像视角及细节的识别能力。
采用自动化和标准化的数据处理流程,提高了数据预处理的效率和一致性。
多类别分类的策略:
针对Food-101数据集中的101个不同食物类别,项目采用了适合多类别分类的损失函数和评估指标,如交叉熵损失和准确率,确保了分类任务的有效性。
模型性能的全面评估:
除了传统的准确率评估外,项目还使用了混淆矩阵、召回率、精确度以及ROC和AUC值等综合评估手段,全面分析了模型在各个类别上的表现和泛化能力。
🍞三. 整体流程
数据收集与预处理
-
数据集选择:选择Food-101数据集,该数据集包含101个不同食物类别的高分辨率图像。
-
图像预处理:对图像进行格式统一、尺寸调整、颜色空间转换和标准化处理。
-
数据增强:实施数据增强技术,如旋转、翻转、缩放和裁剪,以增加数据多样性并提高模型泛化能力。
模型设计与构建

-
预训练模型选择:选择VGG16作为预训练的基础模型,利用其在大规模数据集上学习到的特征。
-
自定义层添加:在VGG16的基础上,添加自定义的卷积层、全连接层等,构建完整的分类模型。
-
激活函数选择:选用ReLU等激活函数,引入非线性,增强模型的表达能力。
模型编译与训练
-
优化器选择:使用Adam优化器,设置初始学习率,利用其自适应学习率的特性进行模型训练。
-
损失函数定义:选用交叉熵损失函数,适用于多类别分类任务。
-
评价指标设置:以准确率作为主要的评价指标,监控模型训练过程中的性能。
-
训练执行:进行多次迭代训练,利用训练集和验证集对模型进行评估,并采用早停法防止过拟合。
模型评估与测试
-
性能评估:在独立的测试集上评估模型的性能,包括准确率、损失、召回率、精确度等。
-
混淆矩阵分析:使用混淆矩阵分析模型在各个类别上的表现,识别模型的优势和不足。
-
泛化能力测试:通过测试集评估模型对未见数据的处理能力,确保模型具有良好的泛化性。
🍞四. 核心逻辑
以下是构建食物图像分类模型的核心代码逻辑,展示了数据预处理、模型构建、编译、训练和评估的主要步骤:
# 数据预处理
# 读取图像并进行尺寸调整、颜色空间转换和标准化处理
img = tf.image.decode_image(img, channels=3)
img = tf.image.resize(img, (224, 224))
img = tf.reverse(img, axis=[-1])
img = tf.image.per_image_standardization(img)
🍞五. 核心逻辑
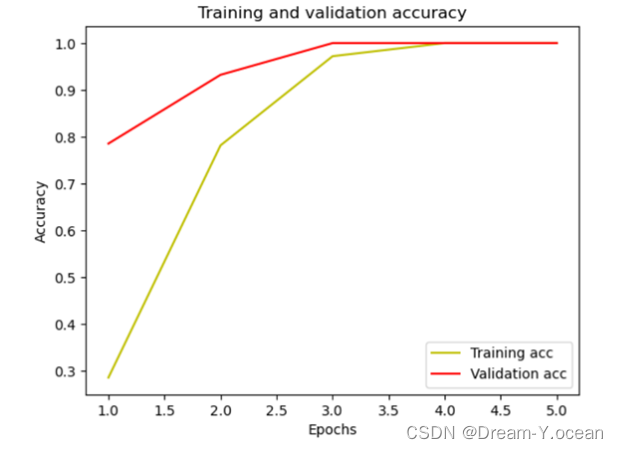
loss曲线如下:
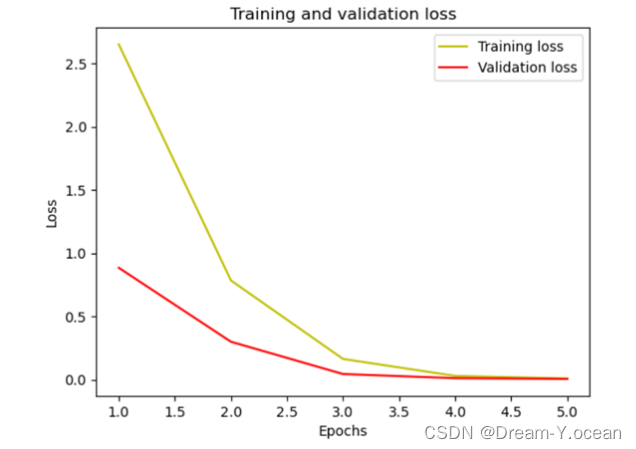
acc曲线如下:
混淆曲线如下:
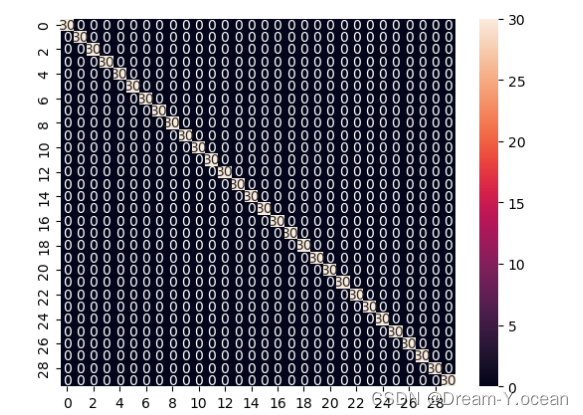
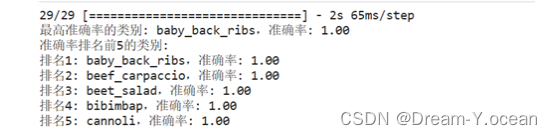
测试集前五排名如下:
🫓总结
综上,我们基本了解了“一项全新的技术啦” 🍭 ~~
恭喜你的内功又双叒叕得到了提高!!!
感谢你们的阅读😆
后续还会继续更新💓,欢迎持续关注📌哟~
💫如果有错误❌,欢迎指正呀💫
✨如果觉得收获满满,可以点点赞👍支持一下哟~✨
【传知科技 – 了解更多新知识】
这篇关于⌈ 传知代码 ⌋ AI驱动食物图像识别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







