本文主要是介绍python数据文件处理库-pandas,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
内容目录
- 一、pandas介绍
- 二、数据加载和写出
- 三、数据清洗
- 四、数据转换
- 五、数据查询和筛选
- 六、数据统计
- 七、数据可视化
pandas 是一个 Python提供的快速、灵活的数据结构处理包,让“关系型”或“标记型”数据的交互既简单又直观。
官网地址: https://pandas.pydata.org/
一、pandas介绍
pandas 有两个主要数据结构,Series(一维)和 DataFrame(二维), 可以处理多种类型的数据.
主要功能:
- 处理缺失数据(以 NaN 表示),无论是浮点数还是非浮点数数据 大小可变性:可以向 DataFrame 和更高维度的对象插入和删除列
- 自动和显式数据对齐:对象可以显式地对齐到一组标签,或者用户可以简单地忽略标签,让 Series、DataFrame
- 等自动在计算中对齐数据 按组操作功能: 用于对数据集执行分割-应用-合并操作,既可用于聚合数据,也可用于转换数据 多源数据转换: 将其他
- Python 和 NumPy 数据结构中的不规则、不同索引的数据转换为 DataFrame 对象
- 智能的基于标签的切片、花式索引和大数据集的子集划分 直观的数据集合并和连接 灵活的数据集重塑和旋转
- 轴的分层标记(每个刻度可以有多个标签) 强大的 IO 工具,用于从(CSV 和分隔符)加载数据,从 Excel
- 文件、数据库加载数据,以及保存/加载超快速 HDF5 格式的数据 时间序列的功能:日期范围生成和频率转换,移动窗口统计,日期偏移和滞后。
Pandas结构:
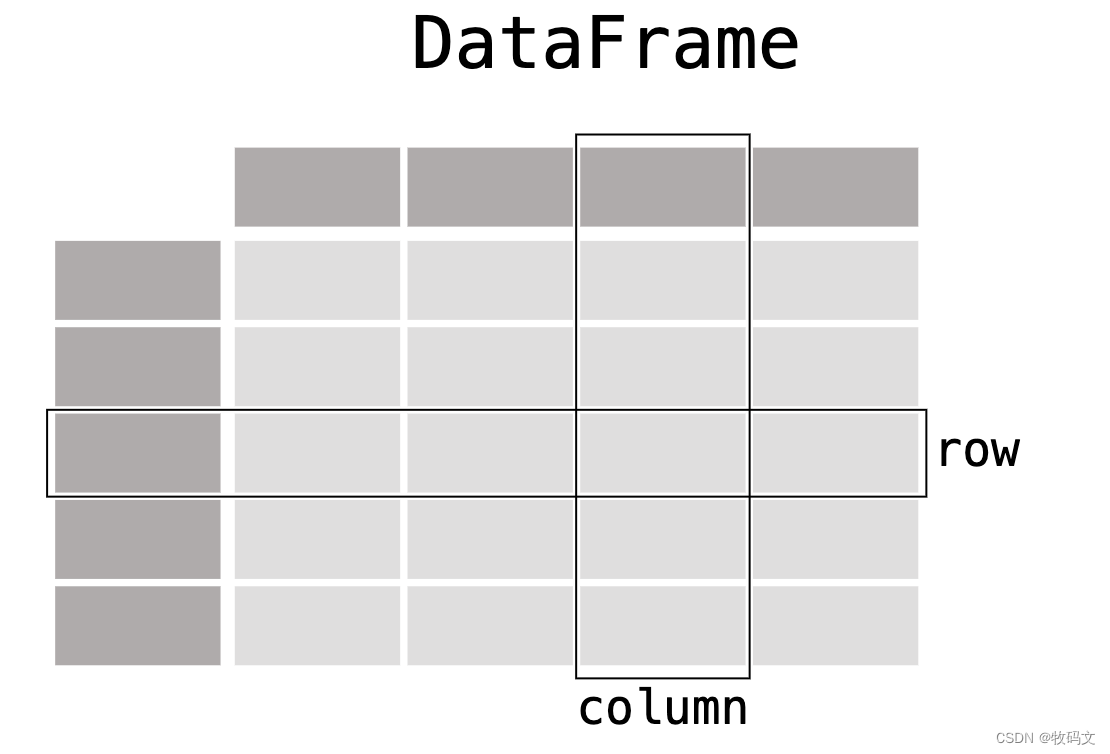
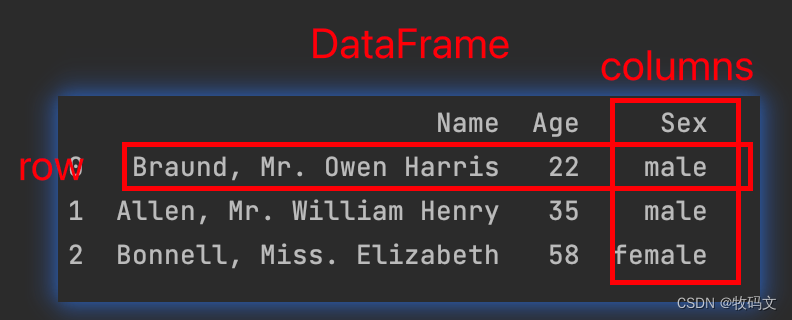
import pandas as pddf = pd.DataFrame({"Name": ["Braund, Mr. Owen Harris","Allen, Mr. William Henry","Bonnell, Miss. Elizabeth",],"Age": [22, 35, 58],"Sex": ["male", "male", "female"],}
)print(df)# Name Age Sex
# 0 Braund, Mr. Owen Harris 22 male
# 1 Allen, Mr. William Henry 35 male
# 2 Bonnell, Miss. Elizabeth 58 female
其中DataFrame的每一列都是Series对象

print(type(df['Name']))
# <class 'pandas.core.series.Series'>
二、数据加载和写出
pandas支持多种形式的数据格式, 不仅可以在代码中显示的加载列表、数组等, 还可以引入外部文件, 支持的外部文件格式也较多

加载时调用对应的方法==read_xxx()==
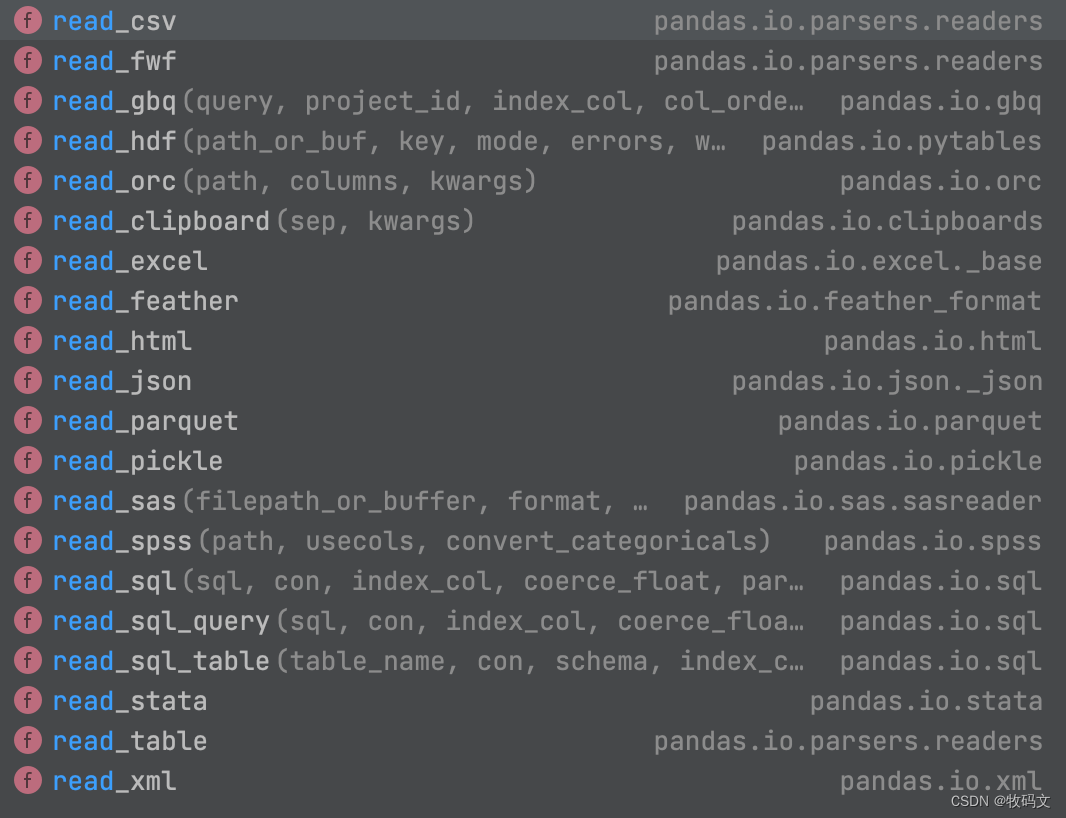
# 数据加载
df = pd.read_excel('./static/pd_file.xlsx')
写出时调用对应的方法to_xxx()
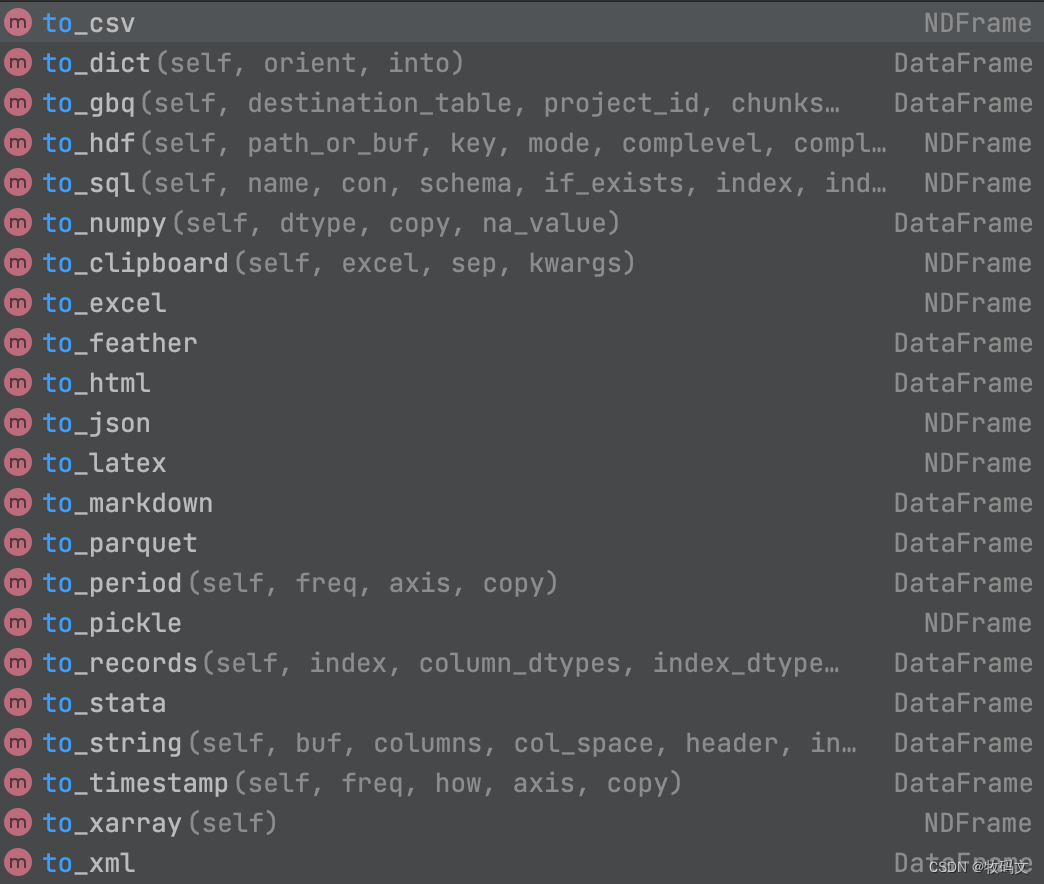
df = pd.to_excel('./static/pd_file_new.xlsx')
三、数据清洗
- dropna(axis=0, how=‘any’): 删除含有缺失值的行或列。
data = {'A': [1, 2, np.nan], 'B': [5, np.nan, np.nan], 'C': [1, 2, 3]}
df = pd.DataFrame(data)# 删除含有缺失值的行
df_cleaned = df.dropna(axis=0, how='any')
print(df_cleaned)
- fillna(value=None, method=‘ffill’, …): 用指定值或方法填充缺失值。
# 使用前一个有效值填充缺失值
df_filled = df.fillna(method='ffill')
print(df_filled)
drop(labels, axis=0): 删除指定行或列。
# 删除第一行
df_dropped_row = df.drop(0, axis=0)
print(df_dropped_row)# 删除某列,例如 'B' 列
df_dropped_col = df.drop('B', axis=1)
print(df_dropped_col)
- replace(to_replace=value, value=None): 替换指定值。
# 将缺失值替换为0
df_replaced = df.replace(np.nan, 0)
print(df_replaced)
- rename(columns={old_name: new_name}, index={…}): 重命名列名或索引。
df_renamed = df.rename(columns={'A': 'NewA', 'B': 'NewB', 'C': 'NewC'})
print(df_renamed)
四、数据转换
- 生成列
# 对a列按照'|'分割, 取1、9、10列作为新列
df[['city','poi_1', 'poi_2']] = df['a'].str.split('|', expand=True)[[0,8,9]]
- 删除列
# 删除a列
df = df.drop(columns=['a'])
- 转换列格式
# 修改dt类型为datetime格式
df['dt'] = pd.to_datetime(df['dt'])
# 处理日期为day、month、year
df['dt_day'] = df['dt'].dt.strftime('%Y-%m-%d')
df['dt_month'] = df['dt'].dt.strftime('%Y-%m')
df['dt_year'] = df['dt'].dt.year
- pivot(index, columns, values): 数据透视表操作。
# 示例数据
data = {'Category': ['Fruit', 'Fruit', 'Vegetable', 'Fruit', 'Vegetable'],'Product': ['Apple', 'Banana', 'Carrot', 'Orange', 'Potato'],'Sales': [100, 200, 150, 300, 250]
}df = pd.DataFrame(data)# 使用pivot创建数据透视表,以'Category'为行,'Product'为列,'Sales'为值
pivot_table = df.pivot(index='Category', columns='Product', values='Sales')
print(pivot_table)
- pivot_table(index, values, aggfunc=np.mean, …): 创建带有聚合函数的数据透视表。
data = {'City': ['New York', 'New York', 'San Francisco', 'San Francisco', 'Chicago', 'Chicago'],'Month': ['Jan', 'Feb', 'Jan', 'Feb', 'Jan', 'Feb'],'Temperature': [5, 8, 12, 14, 3, 6]
}df = pd.DataFrame(data)# 使用pivot_table计算每个月各城市的平均温度
pivot_table = df.pivot_table(index='Month', columns='City', values='Temperature', aggfunc=np.mean)
print(pivot_table)
- apply(func, axis=0): 应用函数到DataFrame的行或列上。
# 示例DataFrame
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]})# 定义一个计算平方的函数
def square(x):return x**2# 对DataFrame的每一列应用square函数
squared_df = df.apply(square, axis=0)
print(squared_df)
- groupby(by=None): 根据某一列或多列进行分组。
data = {'Category': ['Fruit', 'Fruit', 'Vegetable', 'Fruit', 'Vegetable'],'Sales': [100, 200, 150, 300, 250]
}df = pd.DataFrame(data)# 按'Category'列进行分组,并计算'Sales'的总和
grouped_sales = df.groupby('Category')['Sales'].sum()
print(grouped_sales)
五、数据查询和筛选
- loc()方法
DataFrame和Series对象的一种索引器,允许基于行和列的标签来选择数据。
语法: df.loc[row_selection, column_selection],其中row_selection和column_selection可以是单个标签、列表、切片或布尔数组,- 特性:
- 支持“前闭后闭”的区间选择,意味着如果用切片指定范围,两端 的标签都会被包含在内。
- 可以用来选取单行、单列、多行、多列或行与列的组合。
- 不仅可以用于选择数据,还可以用于修改现有数据或插入新数据。
- 特性:
import pandas as pddata = {'Country': ['China', 'United States', 'India'],'Population': [1404200000, 332639102, 1393409038],'Area (sq km)': [9600000, 9372610, 3287263]
}
df = pd.DataFrame(data)
df.set_index('Country', inplace=True)
选取单列
population = df.loc[:, 'Population']
选取多列
subset = df.loc[:, ['Population', 'Area (sq km)']]
选取特定行
china_data = df.loc['China']
选取行范围
us_to_india = df.loc['United States':'India']
布尔索引
large_countries = df.loc[df['Population'] > 1000000000]
修改数据
df.loc['China', 'Population'] = 1444200000 # 更新中国人口数据
插入新数据
df.loc['Brazil'] = ['Brazil', 213993437, 8511965] # 新增巴西数据
- iloc()方法
DataFrame和Series对象的另一个重要索引器,它提供了基于整数位置的数据选择和修改功能。与loc基于标签索引不同,iloc完全依赖于数据在结构中的物理位置
语法:df.iloc[row_selection, column_selection],其中row_selection和column_selection可以是整数、整数列表、切片或布尔数组,来指定数据的位置- 特性:
- 支持整数索引的“左闭右开”区间选择,意味着切片操作的结束位置是不包含在内的。
- 适合于快速按位置访问或修改数据,尤其是在处理没有明确标签或者标签不如位置重要时。
- 不能直接使用列名或行标签进行索引,只能使用整数位置。
- 特性:
选取单个元素
element = df.iloc[1, 2] # 选取第二行第三列的元素
选取整行或整列
second_row = df.iloc[1, :] # 选取第二行
third_column = df.iloc[:, 2] # 选取第三列
选取多行多列
subset = df.iloc[0:2, 1:3] # 选取前两行的第二列至第三列
切片选择
last_two_rows = df.iloc[-2:] # 选取最后两行的所有列
布尔索引(结合.iloc需先转换为位置)
bool_index = df['A'] > 1
position_based_bool_index = df.index[bool_index]
rows_with_A_gt_1 = df.iloc[position_based_bool_index]
-
loc()和iloc()的区别
- loc是通过标签来访问数据,而iloc是通过整数位置来访问数据
- 在使用loc时,选择的行和列都是闭区间,即包括开始和结束位置;而在使用iloc时,选择的行和列都是左闭右开区间,即包括开始位置但不包括结束位置。
- loc可以使用布尔数组进行筛选,而iloc不支持。
- loc可以使用标签名和标签列表作为索引,而iloc只能使用整数作为索引。
- loc和iloc都支持使用冒号(:)来选择所有行或列,但是在使用loc时,冒号前后必须加上标签名或标签列表;而在使用iloc时,冒号前后可以省略,表示选择所有行或列。
-
使用案例
# 数据查询
# 查询某列
city = df['city']# 按索引
# 查询第二列的所有行, 其中第一个为行, 第二个为列
name = df.iloc[:,1]# 获取某些列
c1 = df[['city','poi_1']]
c2 = df.iloc[:,1:3]
查询切片
# 按索引
# 查询第二列的所有行, 其中第一个为行, 第二个为列
name = df.iloc[:,1]
查询指定列
数据查询
# 数据查询
city = df['city']
# 按索引
name = df.iloc[:,1]
# 获取某些列
c1 = df[['city','poi_1']]
c2 = df.iloc[:,1:3]
print(name.head(5))
print(c2.head(5))
数据筛选
# 索引筛选
# 筛选前二十行数据
print(df.iloc[0:21, :])
# 或者
print(df.head(20))# 按条件筛选
# 获取广州的记录
df.set_index('city', inplace=True)
print(df.loc['广州'])# 获取第二列='广州市正骨医院'的记录
print(df.loc[df['poi_1'] == '广州市正骨医院', :])
六、数据统计
- sum(), mean(), median(), min(), max(): 计算总和、均值、中位数、最小值、最大值。
# 示例数据
data = {'A': [1, 2, 3, 4, 5],'B': [5, 15, 10, 20, np.nan],'C': [7, 8, 9, 10, 11]}df = pd.DataFrame(data)# 计算'B'列的总和、均值、中位数、最小值、最大值
total_B = df['B'].sum()
mean_B = df['B'].mean()
median_B = df['B'].median()
min_B = df['B'].min()
max_B = df['B'].max()print(f"Sum of B: {total_B}")
print(f"Mean of B: {mean_B}")
print(f"Median of B: {median_B}")
print(f"Min of B: {min_B}")
print(f"Max of B: {max_B}")
- count(): 非NA值的数量。
# 计算每列的非空值数量
non_na_counts = df.count()
print(non_na_counts)
- corr(): 计算相关系数矩阵。
# 计算相关系数矩阵
correlation_matrix = df.corr()
print(correlation_matrix)
- cov(): 计算协方差矩阵。
# 计算协方差矩阵
covariance_matrix = df.cov()
print(covariance_matrix)
- sort_values(by, ascending=True): 根据一列或多列的值排序。
# 按'A'列升序排序
sorted_df = df.sort_values(by='A', ascending=True)
print(sorted_df)
- rank(method=‘average’): 计算每行或每列的排名。
# 计算'B'列的排名
ranked_df = df['B'].rank(method='average')
print(ranked_df)
七、数据可视化
使用Matplotlib的基本绘图
首先确保已经安装了matplotlib库,如果没有安装可以通过pip安装:pip install matplotlib。
import pandas as pd
import matplotlib.pyplot as plt# 示例数据
data = {'Year': [2000, 2001, 2002, 2003, 2004],'Sales': [10, 15, 20, 25, 30]}
df = pd.DataFrame(data)# 绘制折线图
plt.figure(figsize=(10, 5))
df.plot(kind='line', x='Year', y='Sales', color='blue')
plt.title('Sales Over Years')
plt.xlabel('Year')
plt.ylabel('Sales')
plt.show()
总之, pandas的功能十分丰富且强大, 这里只是列举了冰山一角, 更多内容可以查看官网.
这篇关于python数据文件处理库-pandas的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





