本文主要是介绍oracle数据库通过impdp导入数据时提示,ORA-31684:对象类型用户xxx已存在,和ORA-39151:表xxx存在的解决办法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前提条件:首先备份原数据库中此用户对应的schemas
比如名为cams_wf的schemas
以便出了问题后还可以恢复原数据。

解决办法一、
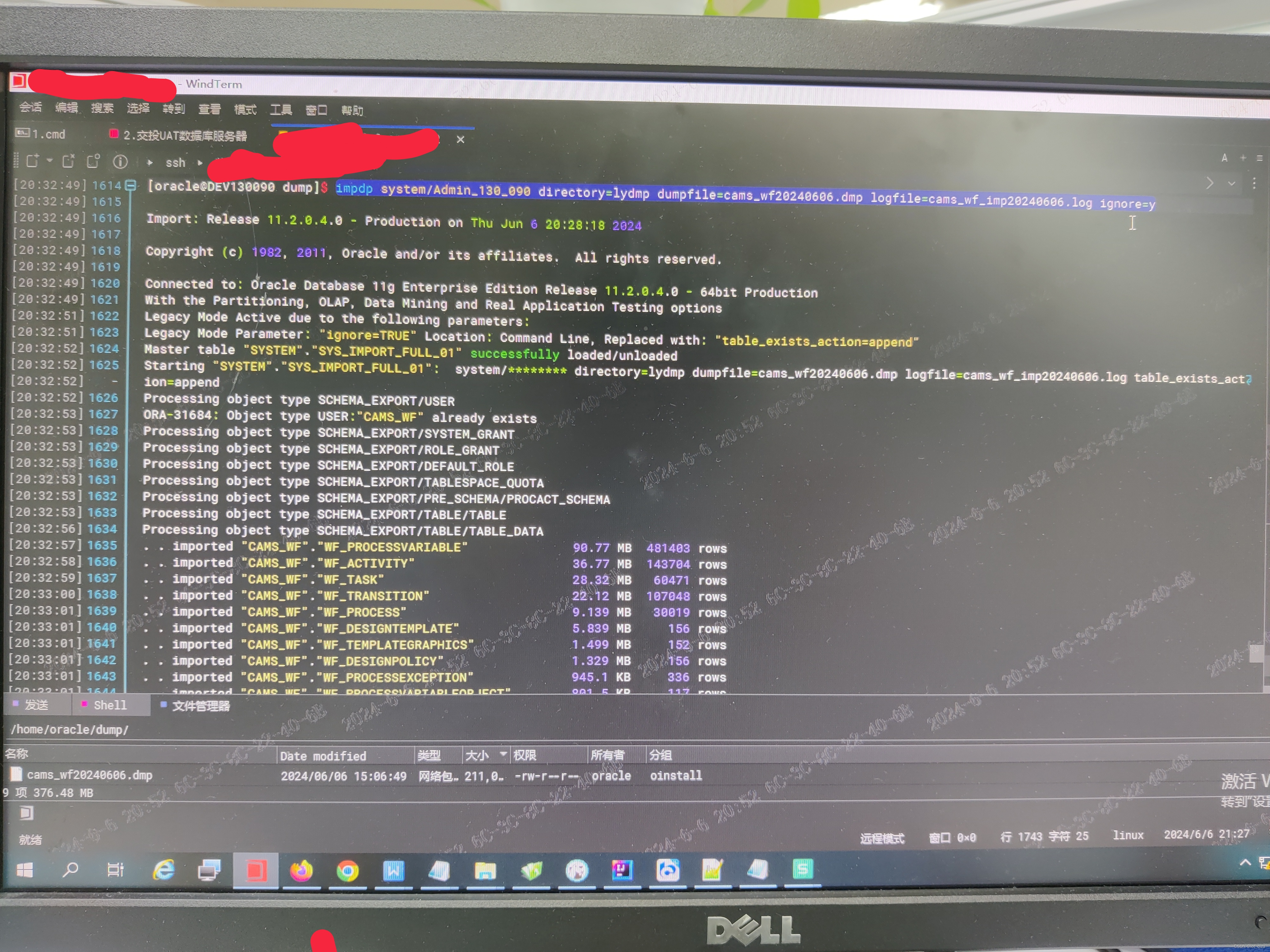
通过命令或者数据库管理工具删除掉此schemas下的所有表,然后在impdp中加入ignore=y
来忽略ORA-31684:对象类型用户xxx已经存在
的报错,继续往后执行完
解决办法二、
删除报错中提示已存在的用户,步骤为
切换到oracle服务器用户:su - oracle
进入oracle数据库: sqlplus / as sysdba
执行 drop user xxx cascade;
来删除xxx数据库用户
成功删除该已存在的用户后,再执行impdp命令导入数据。
解决办法三、
(以下是百度搜索出的)
当使用impdp命令进行数据库导入时,如果遇到提示表已存在的情况,可以通过table_exists_action参数来指定如何处理已存在的表。这个参数有四种处理方式:
skip:默认操作,如果表已经存在,则跳过该表的导入。
replace:先删除(drop)已存在的表,然后创建表并插入数据。
append:在原有数据的基础上增加数据。
truncate:先截断(truncate)已存在的表数据,然后再插入数据。
选择哪种处理方式取决于你的需求。例如,如果你想要保留原有数据并添加新的数据,可以选择append;如果你想要替换原有数据,可以选择replace;如果你想要跳过已存在的表,可以选择skip。需要注意的是,replace和truncate操作都涉及到对表的修改,可能会影响到依赖该表的其他系统或应用,因此在选择这些选项时要谨慎。
此外,在进行导入操作之前,确保你有足够的权限来执行这些操作,并且了解这些操作可能带来的影响。如果表名或数据库对象名与现有对象冲突,可能会导致导入失败或数据损坏。因此,在进行导入之前,最好先备份数据库或相关对象的数据
这篇关于oracle数据库通过impdp导入数据时提示,ORA-31684:对象类型用户xxx已存在,和ORA-39151:表xxx存在的解决办法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





