本文主要是介绍RK3288 android7.1 实现ota升级时清除用户数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
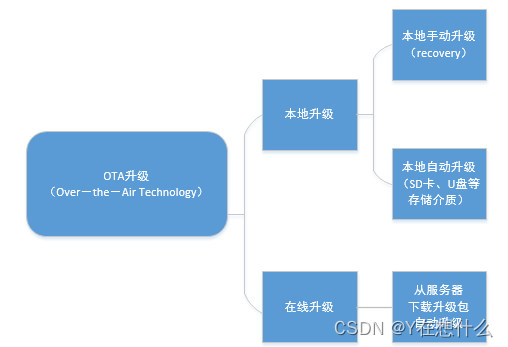
一,OTA简介(整包,差分包)
OTA全称为Over-The-Air technology(空中下载技术),通过移动通信的接口实现对软件进行远程管理。
1. 用途:
OTA两种类型最大的区别莫过于他们的”出发点“(我们对两种不同升级包的创建,并使用它进行OTA升级)。我们创建整包时不需要old包,可以直接使用base包进行升级,因此整包一般用来升级整个固件【∞ -> B】,而差分包一般用于两个特定的点【A->B】。
2. 大小:
通常情况下,整包的大小比较接近于整个固件的镜像。而差分包并没有特定的限制,可以和整包差不多大,也可以只有几KB,不过通常情况下,差分包要比整包小得多。
3. 内容:
OTA整包从大小和内容上都比较接近完整的固件镜像。而差分包更像是一个patch,我们可以认为是A和B差异的部分。
二,问题现象
ota整包升级后(ota升级相当于优化上一个系统,内部原本的数据是不会清除掉),上个系统里的残留数据导致升级后出现问题(比如:apk内部无法联网)。
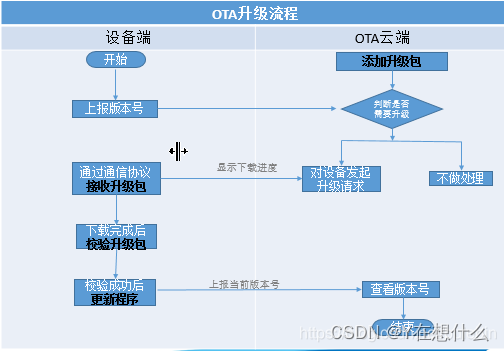
三,修改步骤
1. 设置OPTIONS.wipe_user_data
把OPTIONS.wipe_user_data设为True,再编译生成ota升级包(ota升级后可格式化data分区)。
源码:build/tools/releasetools/ota_from_target_filesdiff --git a/build/tools/releasetools/ota_from_target_files.py b/build/tools/releasetools/ota_from_target_files.py
index e88fa7d832..710c6797c8 100755
--- a/build/tools/releasetools/ota_from_target_files.py
+++ b/build/tools/releasetools/ota_from_target_files.py
@@ -150,7 +150,7 @@ OPTIONS.verify = FalseOPTIONS.require_verbatim = set()OPTIONS.prohibit_verbatim = set(("system/build.prop",))OPTIONS.patch_threshold = 0.95
-OPTIONS.wipe_user_data = False
+OPTIONS.wipe_user_data = TrueOPTIONS.omit_prereq = FalseOPTIONS.downgrade = FalseOPTIONS.extra_script = None
2. 进入系统时需要输入Android密码问题
OPTIONS.wipe_user_data设为True后可能会出现进入系统时需要输入Android密码, 是因为data分区数据有问题(并不是因为加密)。
系统默认data分区格式是f2fs,但是可能会有出入,导致data分区被识别为ext4,导致如上问题(输入Android密码)
3. 解决需要输入Android密码问题
打上如下补丁:
diff --git a/bootable/recovery/updater/install.cpp b/bootable/recovery/updater/install.cpp
index 2651ac6874..43887dac4d 100644
--- a/bootable/recovery/updater/install.cpp
+++ b/bootable/recovery/updater/install.cpp
@@ -343,6 +343,7 @@ Value* FormatFn(const char* name, State* state, int argc, Expr* argv[]) {goto done;}device = getDevicePath(location);
+ printf("[fy][start]: fs_type=%s\n",fs_type); //加打印看fs_type的值,如果为f2fs则没问题if (strcmp(partition_type, "MTD") == 0) {mtd_scan_partitions();const MtdPartition* mtd = mtd_find_partition_by_name(device);
@@ -388,15 +389,16 @@ Value* FormatFn(const char* name, State* state, int argc, Expr* argv[]) {goto done;}const char *f2fs_path = "/sbin/mkfs.f2fs";
- const char* const f2fs_argv[] = {"mkfs.f2fs", "-t", "-d1", location, num_sectors, NULL};
+ const char* const f2fs_argv[] = {"mkfs.f2fs", "-t", "-d1", device, num_sectors, NULL};int status = exec_cmd(f2fs_path, (char* const*)f2fs_argv);free(num_sectors);if (status != 0) {printf("%s: mkfs.f2fs failed (%d) on %s",
- name, status, location);
+ name, status, device);result = strdup("");goto done;}
+ printf("[fy][end]: fs_type is f2fs!\n");result = location;#endif} else {
如果打印看fs_type的值为ext4,则需要去 device目录下搜所有的 recovery*fstab 文件,看看是不是有fstab中的data分区是被定义成ext4格式,如果有的话把它改成f2fs格式。
这篇关于RK3288 android7.1 实现ota升级时清除用户数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






