本文主要是介绍基于Dify的QA数据集构建(附代码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大模型相关目录
大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容
从0起步,扬帆起航。
- 大模型应用向开发路径:AI代理工作流
- 大模型应用开发实用开源项目汇总
- 大模型问答项目问答性能评估方法
- 大模型数据侧总结
- 大模型token等基本概念及参数和内存的关系
- 大模型应用开发-华为大模型生态规划
- 从零开始的LLaMA-Factory的指令增量微调
- 基于实体抽取-SMC-语义向量的大模型能力评估通用算法(附代码)
- 基于Langchain-chatchat的向量库构建及检索(附代码)
- 一文教你成为合格的Prompt工程师
- 最简明的大模型agent教程
- 批量使用API调用langchain-chatchat知识库能力
- langchin-chatchat部分开发笔记(持续更新)
- 文心一言、讯飞星火、GPT、通义千问等线上API调用示例
- 大模型RAG性能提升路径
- langchain的基本使用
- 结合基础模型的大模型多源信息应用开发
- COT:大模型的强化利器
- 多角色大模型问答性能提升策略(附代码)
- 大模型接入外部在线信息提升应用性能
- 从零开始的Dify大模型应用开发指南
- 基于dify开发的多模态大模型应用(附代码)
- 基于零一万物多模态大模型通过外接数据方案优化图像文字抽取系统
- 快速接入stable diffusion的文生图能力
- 多模态大模型通过外接数据方案实现电力智能巡检(设计方案)
- 大模型prompt实例:知识库信息质量校验模块
- 基于Dify的LLM-RAG多轮对话需求解决方案(附代码)
- Dify大模型开发技巧:约束大模型回答范围
- 以API形式调用Dify项目应用(附代码)
- 基于Dify的QA数据集构建(附代码)
文章目录
- 大模型相关目录
- 需求介绍
- 实现
- Dify应用开发
- API版代码
需求介绍
QA数据集,即问答数据集,对于测评大模型应用能力、指令微调具备一定的价值。
事实上,没有Dify时,完全可以调用API实现这一过程。但Dify进行实现后,该功能的复用、修改、配置效率都降进一步提升。
本文思路:
Dify应用开发——Dify开发细节介绍——数据情况——配合代码及文件
实现
Dify应用开发
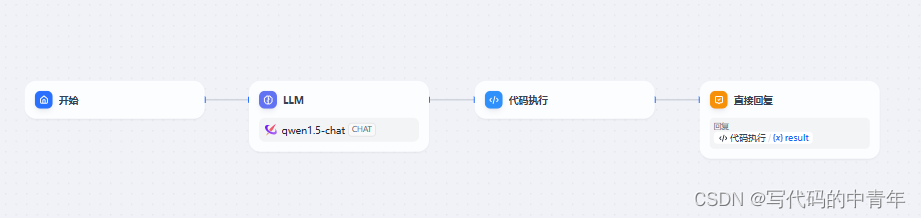
prompt
你是一个问答数据生成专家,可以文本内容生成问答数据。
生成的问题和回答应口语形式描述出来。
每条问题要全面清晰,要求问题和回答的语句完整。
最后强调,以不同的角度生成2条问答数据。### 文本内容:
低[电]压 low voltage,LV用于配电的交流系统中1000V及其以下的电压等级。
[来源:GB/T 2900.50—2008,2.1]### 生成问题:
问题1:低压的英文是什么
回答1:抵押的英文是low voltage
问题2:低压的含义是什么
回答2:低压是用于配电的交流系统中1000V及其以下的电压等级。### 文本内容:
5.3.12.2 工作负责人(监护人):a) 确认工作票所列安全措施正确、完备,符合现场实际条件,必要时予以补充;
b) 正确、安全地组织工作;
c) 工作前,对工作班成员进行工作任务、安全措施交底和危险点告知,并确保每个工作班成员都已签名确认;
d) 组织执行工作票所列由其负责的安全措施;### 生成问题:
问题1:工作负责人是否需要负责安全措施
回答1:工作负责人需要负责安全措施
问题2:工作成员不签名安全措施和危险点可以工作吗
回答2:工作成员不签名安全措施和危险点不可以工作### 文本内容:
{{#sys.query#}}
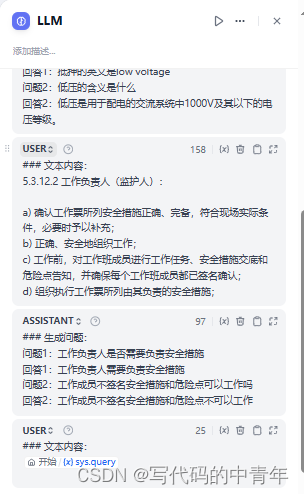
后处理
数据情况
实际代码
import timeimport pandas as pd
from openai import OpenAI
import os
import json
import requestsdef get_files_absolute_paths(folder_path):result = []# 确保给定的路径是存在的if not os.path.exists(folder_path):print(f"The path {folder_path} does not exist.")return []# 列出给定文件夹中的所有文件(不包括子文件夹)for file in os.listdir(folder_path):if os.path.isfile(os.path.join(folder_path, file)):# 构造文件的绝对路径file_path = os.path.abspath(os.path.join(folder_path, file))result.append(file_path)# 输出文件的绝对路径# print(file_path)return resultdef read_txt_file(file_path):with open(file_path, 'r', encoding='utf-8') as file:content = file.read()return contentdef get_llm_response(input_text):url = 'http://172.20.32.127:5001/v1/chat-messages'data = {"inputs": {},"query": input_text,"response_mode": "blocking","conversation_id": "","user": "abc-123",}json_data = json.dumps(data)response = requests.post(url,data=json_data,headers={"Content-Type": "application/json",'Authorization': f'Bearer '})response_text = response.textreturn json.loads(response_text)['answer']def cache(input_result):questions = []anwsers = []for index in range(len(input_result)):if index % 2 == 0:questions.append(input_result[index])else:anwsers.append(input_result[index])pd.DataFrame({'Q': questions, 'A': anwsers}).to_excel('QA_data.xlsx', index=False)folder_path = r'C:\Users\12258\Desktop\聊城电网相关文档\all'
files_path = get_files_absolute_paths(folder_path)result = []
for file_path in files_path:time.sleep(1)file_content = read_txt_file(file_path)llm_response = get_llm_response(file_content)print(type(llm_response),llm_response)for i in llm_response[1:-1].split(','):result.append(i.strip('"'))# print(result)cache(result)API版代码
from llm_ask.ask_Tongyi import *
import os# 获取指定目录下所有文件的绝对路径列表
def get_files_in_directory(directory):result = []# 遍历指定目录下的所有文件和文件夹for root, dirs, files in os.walk(directory):# 只处理文件,不处理文件夹for file in files:# 获取文件的完整路径file_path = os.path.join(root, file)# 打印文件路径或进行其他操作# print(file_path)result.append(file_path)return result# 由json文件绝对路径读取单个json文件获取其文件名称和标题
def read_single_json(json_file_path:str)->str:title = json_file_path.split('\\')[-1][:-5]with open(json_file_path, 'r', encoding='utf-8') as file:data = str(json.load(file))return title,data# 以追加方式向指定的txt文件存入内容
def wirte_txt(txt_file_path,data):with open(txt_file_path,'a',encoding='utf-8') as f:f.write(data)f.write('\n\n')# 对llm返回的结果进行处理
def adjust_result(llm_result):llm_result_text = llm_result['text']return llm_result_textprompt_modules = ['''你是一个问答数据生成专家,可以就上述json数据生成问答数据。本次提问关注json格式中的 {ziduan} 字段,该字段是指{ziduan_describe}。生成的问题和回答应口语形式描述出来。每条问题要全面清晰,注明是对{zhengce}的{ziduan}进行提问。最后强调,以不同的角度生成3条问答数据以上。问题及答案符合口语习惯,采取如下格式:根据{zhengce}请回答问题1:回答1\n\n根据{zhengce}请回答问题2:回答2\\n\\n...]。'''
]ziduans = ['办理结果名称','承办机构','法定办结时限','受理时间、地点','咨询渠道','投诉渠道'
]ziduan_describes = ['所要办理的文件','办理该事项的政府机关部门名称','办理该文件所需的最大时限','办理该文件时,机关部门的工作地点和工作时间段','该事项相关的咨询渠道','该事项相关的投诉渠道'
]ziduan_indexs = range(len(ziduans))# exe
ask_tyqw = TongyiAPI()directory = r'C:\Users\12258\Desktop\zwllm_data_v240320\approval_data_300' # 目录路径
file_paths = get_files_in_directory(directory)
for file_path in file_paths[5:]:title, json_data = read_single_json(file_path)prompt_data = json_datafor index in ziduan_indexs:prompt_module = prompt_modules[0].format(zhengce=title,ziduan=ziduans[index],ziduan_describe=ziduan_describes[index])prompt = prompt_data + '\n' + prompt_modulellm_result = ask_tyqw.get_one_response_by_prompt(prompt)print(llm_result)llm_adjust_result = adjust_result(llm_result)mid = directory.replace('approval_data_300','approval_data_300_ask_txt')+'\\'+title+'.txt'wirte_txt(mid, llm_adjust_result)
import requests
import json
import dashscope
from dashscope import Generation
from http import HTTPStatusclass TongyiAPI:def __init__(self):API_KEY = 'sk-'dashscope.api_key = API_KEYself.gen = Generation()def get_one_response_by_prompt(self, prompt):response = self.gen.call(model=dashscope.Generation.Models.qwen_turbo,prompt=prompt)# The response status_code is HTTPStatus.OK indicate success,# otherwise indicate request is failed, you can get error code# and message from code and message.if response.status_code == HTTPStatus.OK:# print(response.output) # The output textprint(response.usage) # The usage informationreturn response.outputelse:print(response.code) # The error code.print(response.message) # The error message.
这篇关于基于Dify的QA数据集构建(附代码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





