本文主要是介绍安徽某高校数据挖掘作业6,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 根据附件中year文件,编辑Python程序绘制年销售总额分布条形图和年净利润分布条形图,附Python程序和图像。
2 根据附件中quarter和quarter_b文件,编辑Python程序绘制2018—2020年销售额和净利润折线图,附Python程序和图像。
3 根据附件中month文件,编辑Python程序绘制2020年每月销售额分布和净利润分布条形图,附Python程序和图像。
1.
import pandas as pd
import matplotlib.pyplot as plt
import os# 确保工作目录正确
os.chdir('C:/Users/SaintJerry/PycharmProjects/pythonProject6')# 读取数据
year_data = pd.read_excel('year.xls')# 设置字体以支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用SimHei字体显示中文
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 绘制年销售总额分布条形图
plt.figure(figsize=(10, 5))
plt.bar(year_data['年份'], year_data['销售总额'], color='blue', alpha=0.7)
plt.xlabel('年份')
plt.ylabel('销售总额')
plt.title('按年销售总额分布')
plt.show()# 绘制年净利润分布条形图
plt.figure(figsize=(10, 5))
plt.bar(year_data['年份'], year_data['净利润'], color='green', alpha=0.7)
plt.xlabel('年份')
plt.ylabel('净利润')
plt.title('按年净利润分布')
plt.show()结果:


2.
感谢W同学提供的本题代码:
import matplotlib.pyplot as plt
import pandas as pd
import os# 确保工作目录正确
os.chdir('C:/Users/SaintJerry/PycharmProjects/pythonProject6')# 读取数据
data = pd.read_excel('quarter.xls')
data1 = pd.read_excel('quarter_b.xls')# 设置字体以支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用SimHei字体显示中文
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 转置数据
data = pd.DataFrame(data)
dataT = data.T
dataT.columns = dataT.iloc[0]
dataT = dataT.iloc[1:]data1 = pd.DataFrame(data1)
data1T = data1.T
data1T.columns = data1T.iloc[0]
data1T = data1T.iloc[1:]# 绘制图表
dataT.plot(title='quarter')
data1T.plot(title='quarter_b')
plt.show()结果:


3.
import matplotlib.pyplot as plt
import pandas as pd
import os
import matplotlib
matplotlib.use('TkAgg')# 确保工作目录正确
os.chdir('C:/Users/SaintJerry/PycharmProjects/pythonProject6')# 设置字体以支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用SimHei字体显示中文
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 读取数据
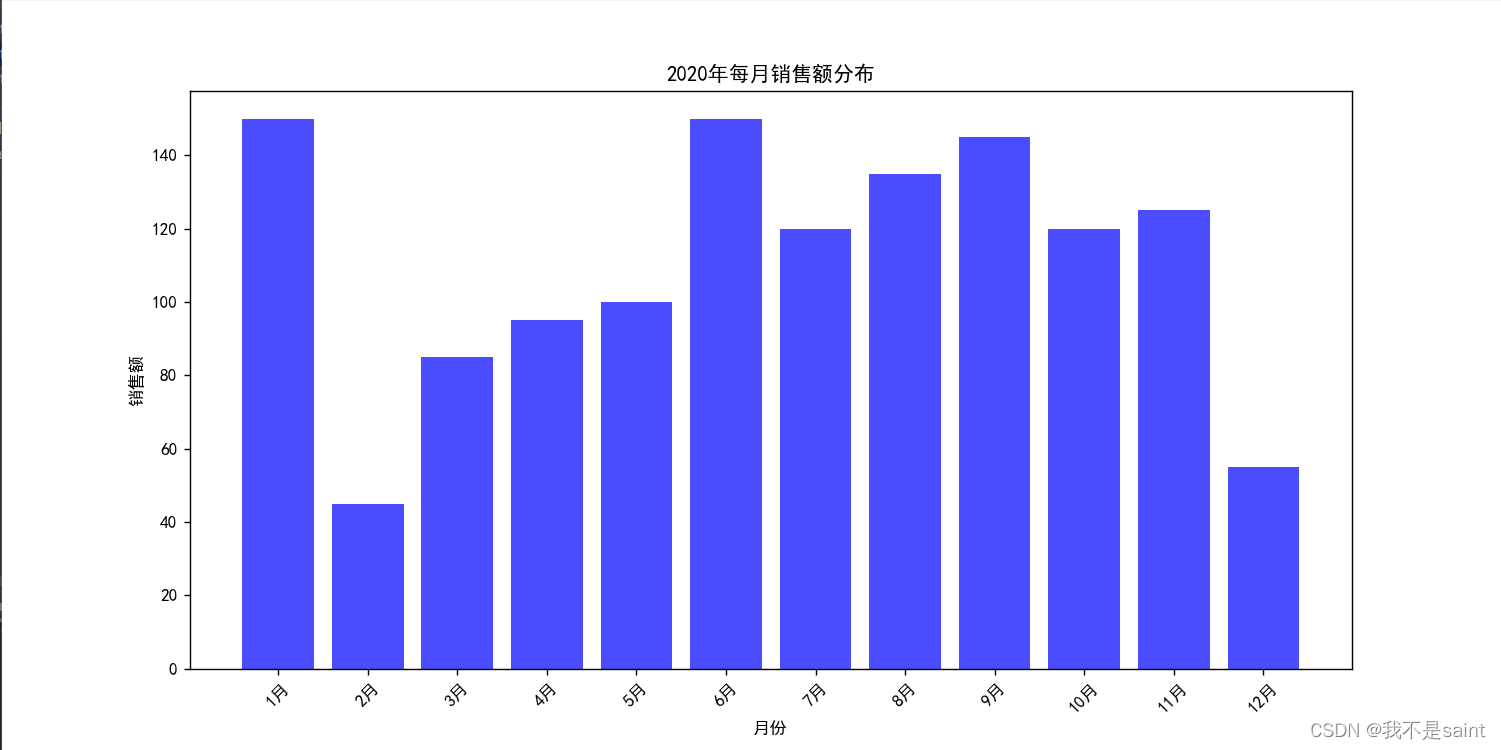
month_data = pd.read_excel('month.xls')# 绘制2020年每月销售额分布条形图
plt.figure(figsize=(12, 6))
plt.bar(month_data['月份'], month_data['销售额'], color='blue', alpha=0.7)
plt.xlabel('月份')
plt.ylabel('销售额')
plt.title('2020年每月销售额分布')
plt.xticks(rotation=45)
plt.show()# 绘制2020年每月净利润分布条形图
plt.figure(figsize=(12, 6))
plt.bar(month_data['月份'], month_data['净利润'], color='green', alpha=0.7)
plt.xlabel('月份')
plt.ylabel('净利润')
plt.title('2020年每月净利润分布')
plt.xticks(rotation=45)
plt.show()结果:

这篇关于安徽某高校数据挖掘作业6的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!