本文主要是介绍内涵:目标检测之DarkNet-DarkNet源码解读<一>测试篇,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目标检测-DarkNet源码解读
- DarkNet源码解读
- 1.一些思考
- 1.1 DarkNet的本质
- 1.2 深度学习分为两条线
- 1.3 检测任务的步骤
- 2.代码走读
- 2.1 程序入口
- 2.2 加载网络
- 2.2 加载图片
- 2.3 前向
- 2.4 后处理
- 3.一些细节
- 3.1 双向链表来存储网络
- 3.2 route层来实现多链
- 3.3 回调函数实现类似于caffe中层的多态
- 3.4 TopN并非Top1&&删除并非融合
- Github
- 附录
DarkNet源码解读
本文是目标检测专栏的第二篇文章。在第DarkNet使用中,主要是介绍了两点:
- 调用DarkNet的官方预训练模型,对图片进行前向推理检测;
- 使用DarkNet深度学习框架对VOC数据集,进行模型训练;
上篇文章比较偏应用,主要用途在于对DarkNet有一个直观感觉。重点在于: - 熟悉DarkNet进行前向预测和模型训练的指令;
- DarkNet用于检测任务需要的标签文件和格式;
本篇是对DarkNet源码的解读篇。对于源码的解读,采用大胆假设-小心求证的步骤,期望形成一套自圆其说的理论。对于本篇博客,作为本人的经验总结,若有读者阅读到本篇文章(大神请忽视该文章),期望具有以下基础素质: - 阅读过已有检测类的论文,知道检测是一个大概什么流程(似懂非懂即可);
- c语言基础知识(似懂非懂即可);
- 使用过其他的深度学习框架例如Caffe或者Pytorch(似懂非懂即可);
1.一些思考
之所以没有上来就将源码复制上来,然后按一个一个变量、一句一句步骤添加注释,是因为这样的源码解读已经有比较多的博友写了。所以想按照另一套思维方式来写这篇博客。
1.1 DarkNet的本质
DarkNet的本质是一个C语言工程。首先思考并回答这个问题,是因为这个答案决定了接下来如何去研读DarkNet的代码。
有过c语言基础知识的学生都会应该见过如下这行代码:
`int main(int argc, char* argv[])`
作为常识类知识,任何一个c语言工程都会含有上述或者类似上述代码的一段代码,它是整个c语言工程的入口处以及外部配置参数接收处。面对DarkNet以及其他复杂的代码工程,把握住这个入口,一定程度上可以避免初接触者陷入“老虎吃天,无从下口”的窘境。
1.2 深度学习分为两条线
深度学习分为两条线:测试线和训练线。之所以思考这个问题是因为DarkNet作为比较完善的深度学习框架,其功能必定不是单一的。进入入口函数之后,可以想象到,根据外部的模式配置,代码会分叉为很多条线。而最根本也是最重要的是这两条线。
本篇博客作为DarkNet的第二篇文章,源码解读的第一篇文章会从相对较为简单的测试线下手,后续第三篇文章会对训练线进行解读。
1.3 检测任务的步骤
可以想象到检测任务应该包含如下步骤:
加载网络–>加载图片---->网络前向—>后处理。其实这个步骤也适用于分类。但特殊点在于检测的后处理部分会更加复杂,可能会涉及到坐标,nms操作等。
如果对论文中的这些公式,似懂非懂,阅读源码是一个很好的解答疑惑的方法。
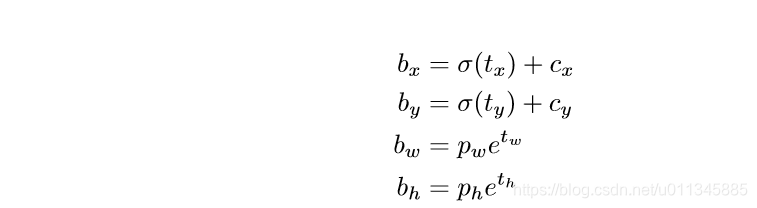
2.代码走读
注意本章的代码走读,仍旧不会陷入细节中。如果说第一章是对代码的一次想象。那么第二章就是对代码骨架的一次整体远观。而第三章则是对代码的一次近距离触摸。一些可能存在疑惑或者值得深究的代码细节会在第三章进行详细分析。而最最详细的全部代码和注释则会以github连接的形式放出来。
2.1 程序入口
通过全局查找关键字 main( 可以快速的定位到程序的入口位于
filename : darknet.cint main(int argc, char **argv)
{...} else if (0 == strcmp(argv[1], "detector")){run_detector(argc, argv);} ...
}
如1.2节所述,我们选择如下所示的前向预测的指令。
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg
在找到程序入口的基础上,再根据指令集中的 detector 以及 test 模式,可以方便的跳转到核心代码:
filename : detector.cvoid test_detector(char *datacfg, char *cfgfile, char *weightfile, char *filename, float thresh, float hier_thresh, char *outfile, int fullscreen)
{list *options = read_data_cfg(datacfg);//这边需要调试一下,大概意思就是将cfg读取到一个List中。char *name_list = option_find_str(options, "names", "data/names.list");//类别list(连起来)char **names = get_labels(name_list);//类别数组(分开)image **alphabet = load_alphabet();//?不知道在干啥network *net = load_network(cfgfile, weightfile, 0);//加载网络和模型,核心代码,这个可以细看下,但现在先不管。set_batch_network(net, 1);srand(2222222);double time;char buff[256];char *input = buff;float nms=.45;while(1){if(filename){strncpy(input, filename, 256);} else {printf("Enter Image Path: ");fflush(stdout);input = fgets(input, 256, stdin);if(!input) return;strtok(input, "\n");}image im = load_image_color(input,0,0);image sized = letterbox_image(im, net->w, net->h);//往中间嵌,然后四周pad(默认值为0.5)//image sized = resize_image(im, net->w, net->h);//image sized2 = resize_max(im, net->w);//image sized = crop_image(sized2, -((net->w - sized2.w)/2), -((net->h - sized2.h)/2), net->w, net->h);//resize_network(net, sized.w, sized.h);layer l = net->layers[net->n-1];//最后一层float *X = sized.data;time=what_time_is_it_now();network_predict(net, X);//核心操作,做前向预测。但其实对于前向操作来讲,yolo层仅仅是对x,y,c0,c1,c2,...cn做了前向预测printf("%s: Predicted in %f seconds.\n", input, what_time_is_it_now()-time);int nboxes = 0;detection *dets = get_network_boxes(net, im.w, im.h, thresh, hier_thresh, 0, 1, &nboxes);//printf("%d\n", nboxes);//if (nms) do_nms_obj(boxes, probs, l.w*l.h*l.n, l.classes, nms);if (nms) do_nms_sort(dets, nboxes, l.classes, nms);draw_detections(im, dets, nboxes, thresh, names, alphabet, l.classes);free_detections(dets, nboxes);if(outfile){save_image(im, outfile);}else{save_image(im, "predictions");
#ifdef OPENCVmake_window("predictions", 512, 512, 0);show_image(im, "predictions", 0);
#endif}free_image(im);free_image(sized);if (filename) break;}
}
先粗略的浏览一下该函数,虽然更多的细节可能还不清楚。但可以发现,这部分已经包含了所有的核心操作:网络加载–》图片加载—>前向—>后处理。
2.2 加载网络
network *net = load_network(cfgfile, weightfile, 0);
关于加载网络这段代码,如果你没忍住,跟进去不断的跳转之后,你可能会有点蒙圈,因为代码在不断的malloc四种结构体kvp, node, section, list,而且这四种结构体会相互之间插来插去。
另外一方面是如果caffe背景的人,会感觉cfg和prototxt很像,但又感觉少了点什么。比如caffe会明确的写明某一层的输入和输出层bottom和top,据此可以直观的知道层之间的连接关系。但cfg貌似却没有告诉我们层与层之间的连接关系。
关于这两点,见3.1和3.2节。在第三章会做加以详细说明。
2.2 加载图片
if(filename){strncpy(input, filename, 256);} else {printf("Enter Image Path: ");fflush(stdout);input = fgets(input, 256, stdin);if(!input) return;strtok(input, "\n");}image im = load_image_color(input,0,0);image sized = letterbox_image(im, net->w, net->h);
这部分没什么好讲的,但有一点就是darknet几乎无依赖项,两个可选项是opencv和cuda。这里的load_image_color函数如果跳转进去,就会发现,它就是通过一个opencv的宏来判断,是使用c原生的读图函数还是opencv的读图函数。
2.3 前向
network_predict(net, X);
这里有一个点值得思考。caffe里面这么多层是通过继承和多态的思想来实现的,这样可以避免代码的重复开发。基类Layer来派生处不同的XXLayer。C是没有相关概念的,那么每个层的forward和backforward是如何实现的呢?详情见第三章3.3
2.4 后处理
detection *dets = get_network_boxes(net, im.w, im.h, thresh, hier_thresh, 0, 1, &nboxes);//printf("%d\n", nboxes);//if (nms) do_nms_obj(boxes, probs, l.w*l.h*l.n, l.classes, nms);if (nms) do_nms_sort(dets, nboxes, l.classes, nms);
后处理是检测所特有的。可能会对论文中的描述不是特别具像,或者对检测所通用操作nms到底是如何实现的不是特别清晰,这部分在第三章中也会详细分析。见3.4
3.一些细节
3.1 双向链表来存储网络
对于cfg文件的解析,主要函数为:
filename : parser.c
...
list *sections = read_cfg(filename);
...
在该解析过程中,作者用了链表来动态解析并存储cfg里面的内容。作者自定义了结构体list和node。但对于node结构体中的val值,并非像我们之前做leetcode题目那样的是一个数值,而是一个抽象出来的void *(关于void *不太熟悉的可以看这篇博文。)之所以抽象出来是因为这里涉及到的链表中的节点较为复杂,是作者自定义的结构体,共两种节点:section和kvp。
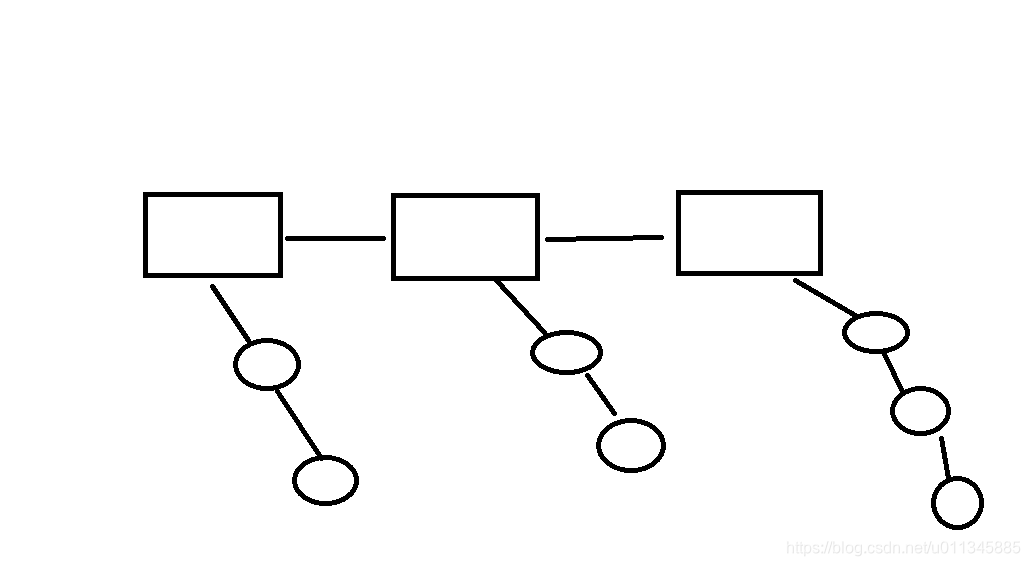
在主干链表上,每个节点是方形的section节点,每一个节点代表一个层。而每个section节点,又会延伸出来一个子链表,该链表中的节点是圆形的kvp节点,每一个节点代表一个层中的配置参数。
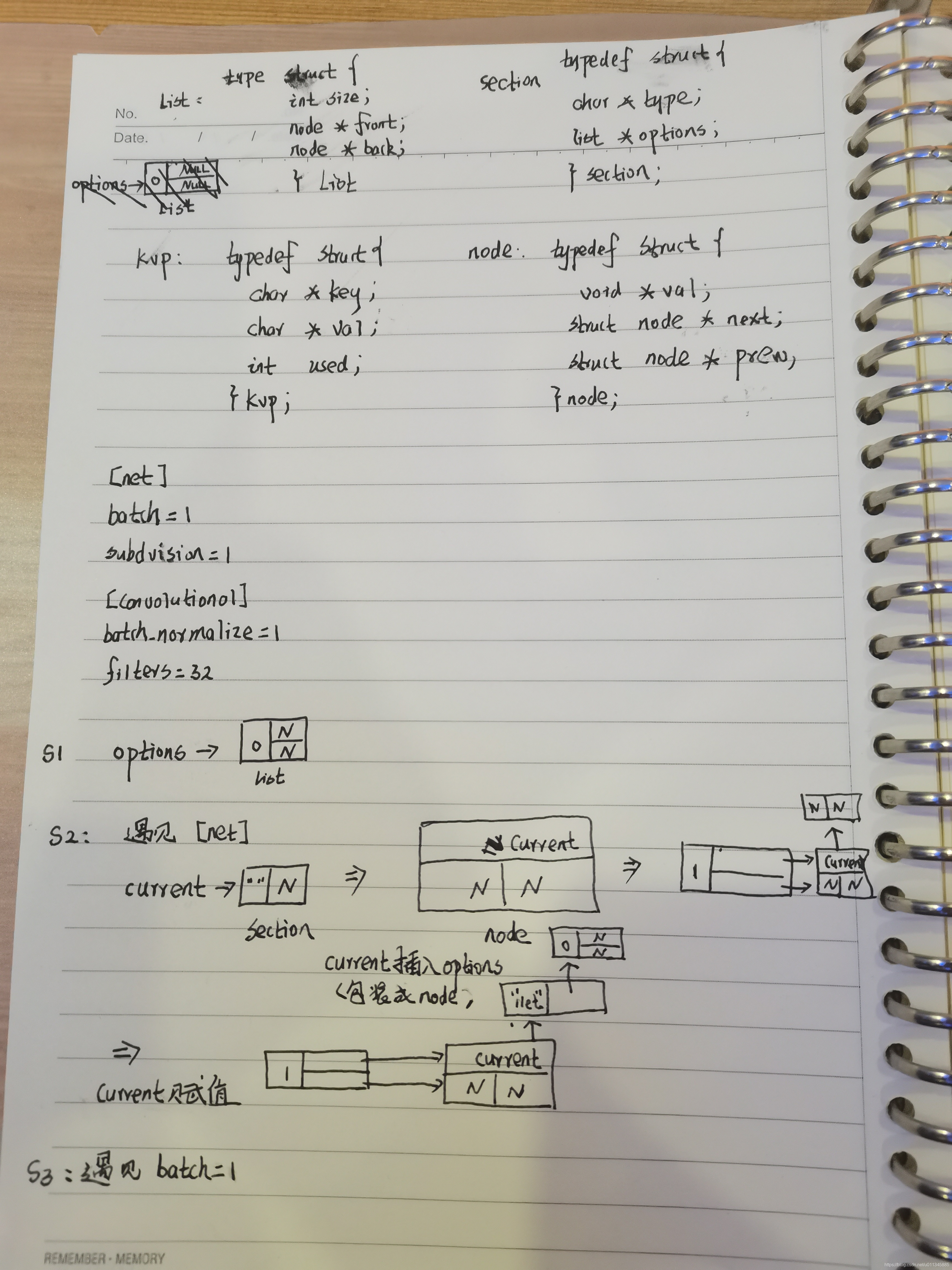
我在附录中用手画了下如下cfg文件的网络动态解析过程,有耐心和兴趣的读者可以见附录中看。
[net]
batch=1
subvision=1
[convolutional]
batch_normalize=1
filters=32
上述手绘的过程可能比较繁琐,但仔细跟着代码,然后自己思考一下,还是能够画出来的。这里想思考的是,为什么作者设计或者说采用了如上所示的一种数据结构来存储?使用数组不可以吗?(不少IT从业者应该都有这样的疑惑,面试就是刷leetcode但工作中又用不太到这些题目,但现在就是一个活生生的数据结构实际应用的例子)。
我自己的思考是这样的。首先整体数据结构用链表不用数组是因为,在解析cfg前,我们是不知道该cfg含有多少个层的,而深度学习,可能从8~1000层不等,所以用链表可以动态的申请内存,追加节点,这种动态性是数组做不到的。而每一层的配置参数同理,所以是两层的链表。
两种节点就对应两种私有的数据结构section和kvp。但对于载体node,由于其val为void*型,所以可以“盛的住”两种两种节点。
另外,注意到list结构体不但有一个front指针,还有一个back指针,这是因为链表的一个缺点是在末尾追加节点,需要o(n)的时间复杂度遍历到尾端。而增加一个指向未节点的指针back,追加新节点时就可以o(1)的复杂度实现。
但仍旧有疑惑,就是作者设计的链表时双向链表,而当前我还没有get到为什么不直接使用单向列表。
3.2 route层来实现多链
layer在net中的存储方式就是普通数组的形式。
net->n = n;//层数
net->layers = calloc(net->n, sizeof(layer));
然后forward的时候就是一个for循环不断的一层一层的做下去。
for(i = 0; i < net.n; ++i){net.index = i;layer l = net.layers[i];//注意这里的l已经是被实例化的层。if(l.delta){fill_cpu(l.outputs * l.batch, 0, l.delta, 1);}l.forward(l, net);//每一层会有一个回调函数,来实例化到具体的层。net.input = l.output;if(l.truth) {net.truth = l.output;}}
思考这样一个问题像上述所讲的那样,for循环按顺序一层一层做下去,那么对于如下所示的多链结构岂不无法实现了?
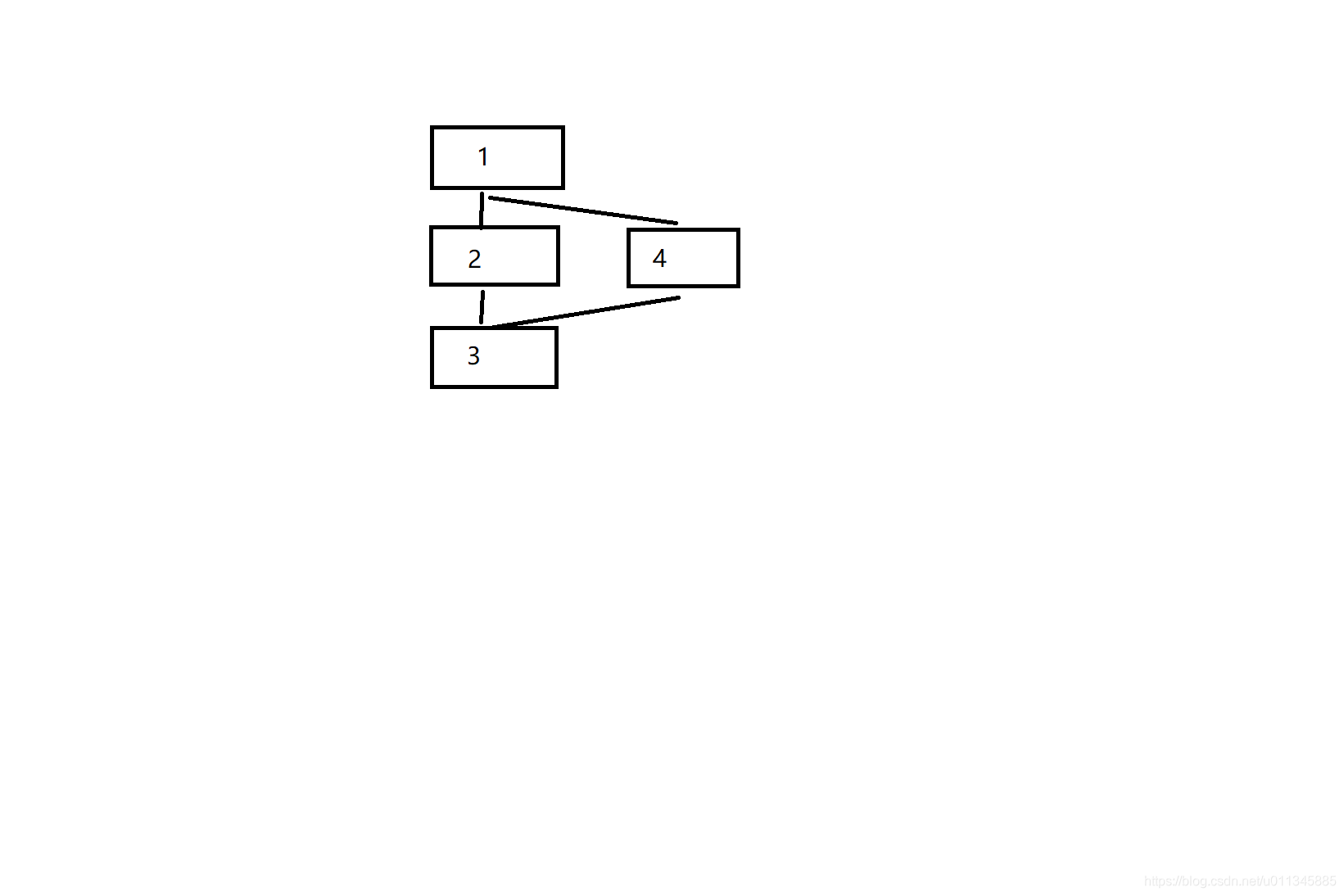
事实上,在darknet中,这可以通过route层来实现:route层会有一个layers的参数:
[route]
layers=2,4
参数layers = 1对于单个序号为1的层的输出直接复制给route层的输出,参数layers=2,4就是将序号为2和4的两个层的输出复制追加给该route层的输出。
这样为了实现上述的多链结构,cfg只需这样设计即可。
[layer1 layer type]
xxx
xxx
[layer2 layer type]
xxx
xxx
[route]
layers=1
[layer4 layer type]
xxxxx
[route]
layers=2,4
[layer3 layer type]
xxxxx3.3 回调函数实现类似于caffe中层的多态
依旧是3.2中的这段代码,有一个值得一提的另外一点就是l.forward(l, net)。
for(i = 0; i < net.n; ++i){net.index = i;layer l = net.layers[i];//注意这里的l已经是被实例化的层。if(l.delta){fill_cpu(l.outputs * l.batch, 0, l.delta, 1);}l.forward(l, net);//每一层会有一个回调函数,来实例化到具体的层。net.input = l.output;if(l.truth) {net.truth = l.output;}}
这里的forward看似是一个普通的函数,事实上它是一个函数指针的存在。
struct layer{LAYER_TYPE type;ACTIVATION activation;COST_TYPE cost_type;void (*forward) (struct layer, struct network);void (*backward) (struct layer, struct network);void (*update) (struct layer, update_args);void (*forward_gpu) (struct layer, struct network);void (*backward_gpu) (struct layer, struct network);void (*update_gpu) (struct layer, update_args);int batch_normalize;int shortcut;int batch;int forced;
在加载网络的时候,实例化每一个layer类型时,会将对应实例层的forward和backward函数赋值给该函数指针。
以yolo层为例:
filename: yolo_layer.clayer make_yolo_layer(int batch, int w, int h, int n, int total, int *mask, int classes)
{
...l.forward = forward_yolo_layer;l.backward = backward_yolo_layer;...}
因此当它在调用l.forward的时候,事实上就是在调用对应层的xxforward函数。
3.4 TopN并非Top1&&删除并非融合
涉及到后处理部分的代码主要是两个函数
detection *dets = get_network_boxes(net, im.w, im.h, thresh, hier_thresh, 0, 1, &nboxes);//printf("%d\n", nboxes);//if (nms) do_nms_obj(boxes, probs, l.w*l.h*l.n, l.classes, nms);if (nms) do_nms_sort(dets, nboxes, l.classes, nms);
由两点需要注意:对于get_network_boxes函数跳转之后
int get_yolo_detections(layer l, int w, int h, int netw, int neth, float thresh, int *map, int relative, detection *dets)
{
...dets[count].prob[j] = (prob > thresh) ? prob : 0;//此处并没有选出一个top1,而是大于threshold的阈值即可...
}
对于do_nms_sort函数
void do_nms_sort(detection *dets, int total, int classes, float thresh)
{
...if (box_iou(a, b) > thresh){dets[j].prob[k] = 0;//这里不是融合而是直接去掉
...
}
Github
后续会将添加注释的完整代码放到github上,尽情期待。
附录

这篇关于内涵:目标检测之DarkNet-DarkNet源码解读<一>测试篇的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







