本文主要是介绍PostgreSQL 17 Beta1 发布,酷克数据再次贡献核心力量,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
得益于全球的开发者贡献,PostgreSQL已成长为一款拥有众多全球用户和贡献者、成熟稳定的开源数据库。2024年5月23日,PostgreSQL全球开发组宣布,PostgreSQL 17的首个 Beta 版本现已开放下载。本次新版本带来了众多惊喜。值得一提的是,本次发布中,酷克数据HashData研发团队参与了多出核心代码贡献,为PostgreSQL项目与社区提供了有力支持。
PostgreSQL 17功能亮点
查询和写入性能优化
PostgreSQL 17(以下称“PG17”)致力于优化和提升整体的系统性能。负责回收存储空间Vacuum进程采用了新数据结构,使得垃圾回收过程的内存使用减少,最高可以减少 20 倍,并缩短执行时间。 Vacuum 进程不再受1GB内存限制,由 maintenance_work_mem 来控制。引入流式I/O接口,提升了顺序扫描和运行 ANALYZE 的性能。新增配置参数,可控制事务、子事务和multixact缓冲区大小。PG17利用Planner统计信息和CTE(即 WITH 查询)结果中的排序顺序,进一步优化查询速度。对于包含IN子句和B-tree索引的查询,执行时间得到显著缩短。对于带有NOT NULL约束的列,PostgreSQL能够自动优化冗余的IS NOT NULL语句,同样,对于IS NULL的查询也进行了优化。此外,支持并行构建BRIN索引。在高并发写入场景下,PG17通过改进预写日志(WAL)锁管理,实现了高达两倍的性能提升。最后,新版本还引入了更多显式的SIMD指令,如AVX-512,为bit_count等函数提供了硬件加速支持。
分区和分布式工作负载增强
PG17的分区管理更为灵活,支持拆分与合并分区,并允许分区表使用身份列(Identity Column) 和排它约束(Exclude Constraints)。同时,postgres_fdw支持将EXISTS和IN子查询下推至远端服务器提升性能。PG17为逻辑复制添加了新功能,简化了高可用架构和升级流程。PG17使用 pg_upgrade升级到更高版本时,无需删除复制槽。支持Failover控制,为高可用性架构中管理 PostgreSQL 提供了更好的可控制性。PG17还允许逻辑复制的订阅者使用 hash 索引进行查找,并引入了 pg_createsubscriber 命令行工具,用于在使用物理复制的副本从库上创建逻辑复制。
开发者体验
PG17深化了 SQL/JSON 支持,新增了 JSON_TABLE 功能,支持将JSON 转换为标准 PostgreSQL 表,以及 SQL/JSON 构造函数(JSON、JSON_SCALAR、JSON_SERIALIZE)和查询函数(JSON_EXISTS、JSON_QUERY、JSON_VALUE)。此外,PG17为 jsonpath 的实现增添了更多功能,包括将 JSON 值转换为各种不同特定数据类型。MERGE 命令现支持 RETURNING 子句,便于处理修改后的行。merge_action 函数可识别 MERGE 命令的修改部分。PG17还允许使用 MERGE 命令更新视图,并新增 WHEN NOT MATCHED BY SOURCE 子句,以指定当源行无匹配时提供操作。COPY用于从PostgreSQL高效批量加载和导出数据,在PG17中,导出大行时的性能最多有两倍的提升。当源与目标编码匹配时,COPY性能亦有所提升。COPY新增 ON_ERROR 选项,允许在插入错误时继续执行。PG17还支持使用 libpq API 使用异步和更为安全的查询取消方法。PG17引入内置的排序规则提供程序,该提供程序提供与 C 排序规则类似的排序语义,但编码为 UTF-8 而非 SQL_ASCII,提供不变性保证,确保排序结果跨系统一致。
安全功能
PG17引入了新连接参数 sslnegotiation,允许 PostgreSQL 在使用 ALPN时直接进行 TLS 握手,减少一次网络往返。同时在 ALPN 注册为 postgresql。此版本还添加了用户认证时触发的新 EventTrigger,以及在 libpq 中新增 PQchangePassword API,实现客户端自动对密码取哈希,提升安全性。另外,新增了预定义角色 pg_maintain,赋予用户执行多种维护权限,并确保 search_path 在执行维护操作时的安全性。最后,支持使用 ALTER SYSTEM 设置系统无法识别的未定义的配置参数。
备份与导出管理
PG17可以使用 pg_basebackup进行增量备份,并增加了一个新的实用工具 pg_combinebackup,用于备份恢复过程中将备份合并。该版本为 pg_dump新增了一个参数项 --filter,允许指定一个文件来进一步指定在 dump 过程中要包含或排除哪些对象。
监控
EXPLAIN命令现增加SERIALIZE和MEMORY选项,分别展示数据序列化耗时和优化器内存使用情况。同时,EXPLAIN还能显示I/O读写耗时。PostgreSQL 17统一了pg_stat_statements中CALL的参数,减少了频繁调用的存储过程记录数。此外,VACUUM进度报告现在会显示索引垃圾回收的进度。PG17还引入了一个新视图,pg_wait_events,提供关于等待事件的描述,可以与 pg_stat_activity 共同使用,以便深入了解活动会话出现等待的原因。此外,pg_stat_bgwriter视图中的一些信息,现在被拆分到新的 pg_stat_checkpointer视图中了。
HashData研发团队贡献核心力量
HashData研发团队一直活跃于PostgreSQL社区。在PostgreSQL 15、16等多个版本中,都能看到HashData研发团队以代码编写、审核、检测等方式参与了数十项开源贡献,为PostgreSQL性能改进和提升提供了有力支持。在最新发布的PG17版本中,HashData研发团队也参与了几项重要贡献:示例一:极具实用性的全新feature,极大地提升了批量导入数据的便捷性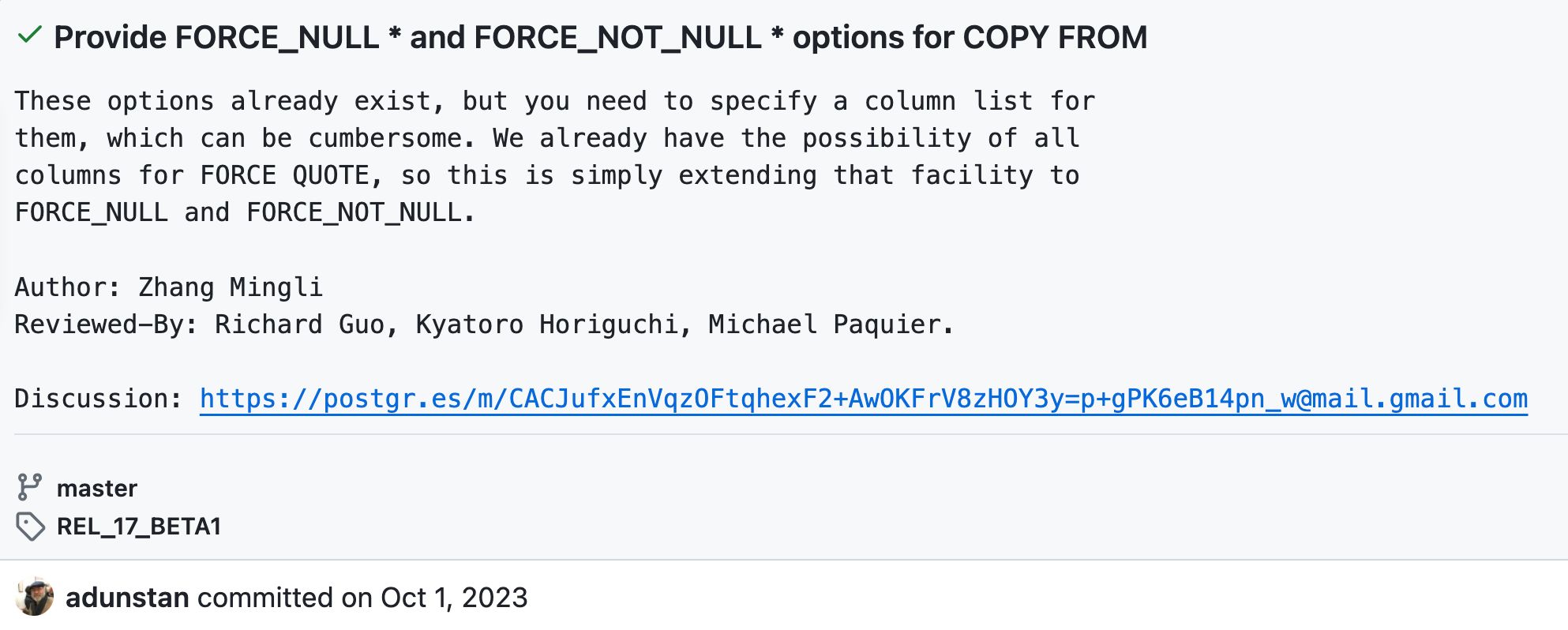 HashData研发团队贡献信息值得一提的是,这是Hashdata第一次有feature进入社区代码,意味着我们的技术能力得到了更广泛的认可与关注。COPY FROM命令是PostgreSQL中用于批量导入数据的强大工具。在数据处理过程中,根据数据和用户定义情况,某些列可为空值。用户可以为这些列设置默认选项,强制为空或者不为空。以往,用户需要逐一设置每一列的空值设置,这在处理大量列(例如,PostgreSQL默认支持的上限是1600列)时变得极为繁琐。全新的feature 为COPY FROM 命令增加FORCE_NULL *和FORCE_NOT_NULL *选项,允许用户轻松的为数据的所有列设置强制为空,或不为空,极大地提高了数据导入的效率。
HashData研发团队贡献信息值得一提的是,这是Hashdata第一次有feature进入社区代码,意味着我们的技术能力得到了更广泛的认可与关注。COPY FROM命令是PostgreSQL中用于批量导入数据的强大工具。在数据处理过程中,根据数据和用户定义情况,某些列可为空值。用户可以为这些列设置默认选项,强制为空或者不为空。以往,用户需要逐一设置每一列的空值设置,这在处理大量列(例如,PostgreSQL默认支持的上限是1600列)时变得极为繁琐。全新的feature 为COPY FROM 命令增加FORCE_NULL *和FORCE_NOT_NULL *选项,允许用户轻松的为数据的所有列设置强制为空,或不为空,极大地提高了数据导入的效率。
- 示例二:代码重构,提升了代码的简洁性和执行的高效性
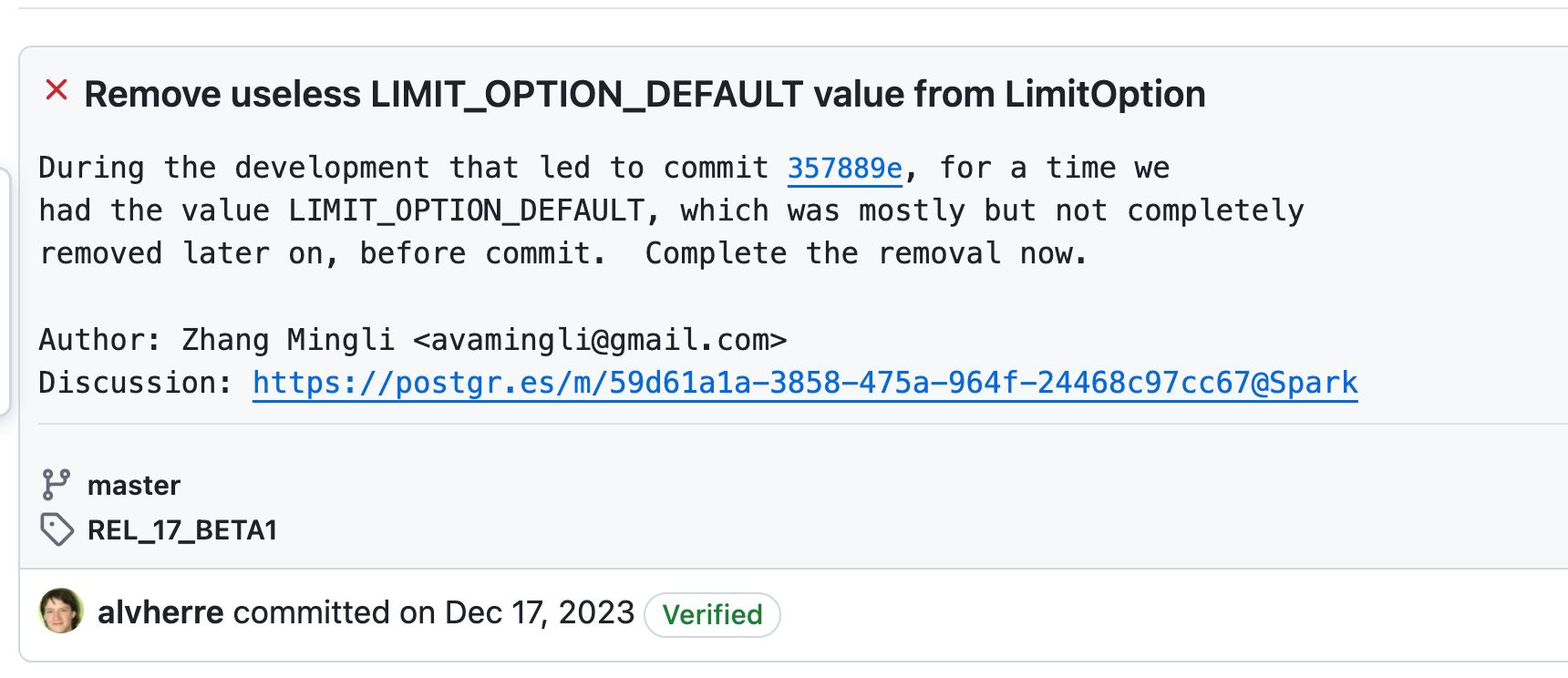 HashData研发团队贡献信息PostgreSQL支持LIMIT、FETCH等语句,这些语句在内部通过不同的枚举选项来实现。然而,HashData团队在深入阅读和理解代码后,发现LIMIT_OPTION_DEFAULT这一选项实际上是多余的,PostgreSQL的解析树已经能够充分表达相应的逻辑。经过严格的验证测试,清理了这部分不必要的代码,提升了PostgreSQL代码的简洁性和执行的高效性。此外,HashData的研发团队还积极参与了代码的Review工作,凭借严谨的态度和专业的技能,为PostgreSQL新版本的稳定性和性能提供了有力保障。
HashData研发团队贡献信息PostgreSQL支持LIMIT、FETCH等语句,这些语句在内部通过不同的枚举选项来实现。然而,HashData团队在深入阅读和理解代码后,发现LIMIT_OPTION_DEFAULT这一选项实际上是多余的,PostgreSQL的解析树已经能够充分表达相应的逻辑。经过严格的验证测试,清理了这部分不必要的代码,提升了PostgreSQL代码的简洁性和执行的高效性。此外,HashData的研发团队还积极参与了代码的Review工作,凭借严谨的态度和专业的技能,为PostgreSQL新版本的稳定性和性能提供了有力保障。
结语
在全球开源社区的共同努力下,PostgreSQL已经发展成为一款功能强大、稳定可靠的开源数据库,广泛应用于各行各业。随着本次beta版本的发布,我们看到了PostgreSQL 17在性能优化、功能增强和安全提升等方面的显著进步。酷克数据HashData研发团队饮水思源,通过代码贡献、PG技术讲解等方式,不断以开源精神和技术实力回馈社区。 凭借团队对技术创新的不懈追求,酷克数据打造了一款面向分析和AI场景的下一代统一型开源数据库产品CloudberryDB,搭载了PostgreSQL 14.4 内核。CloudberryDB既能满足单机本地快捷部署,也能通过插件自由扩展为云原生架构,具备高弹性、高并发、湖仓一体化、扩缩容灵活等优势。同时,CloudberryDB支持丰富的数据类型和数仓/AI混合负载,可开展SQL分析、机器学习、全文检索、HTAP等任务,通过数据存储加密、联合⾝份验证等技术手段,帮助企业更方便地自建高效稳定的数据底座。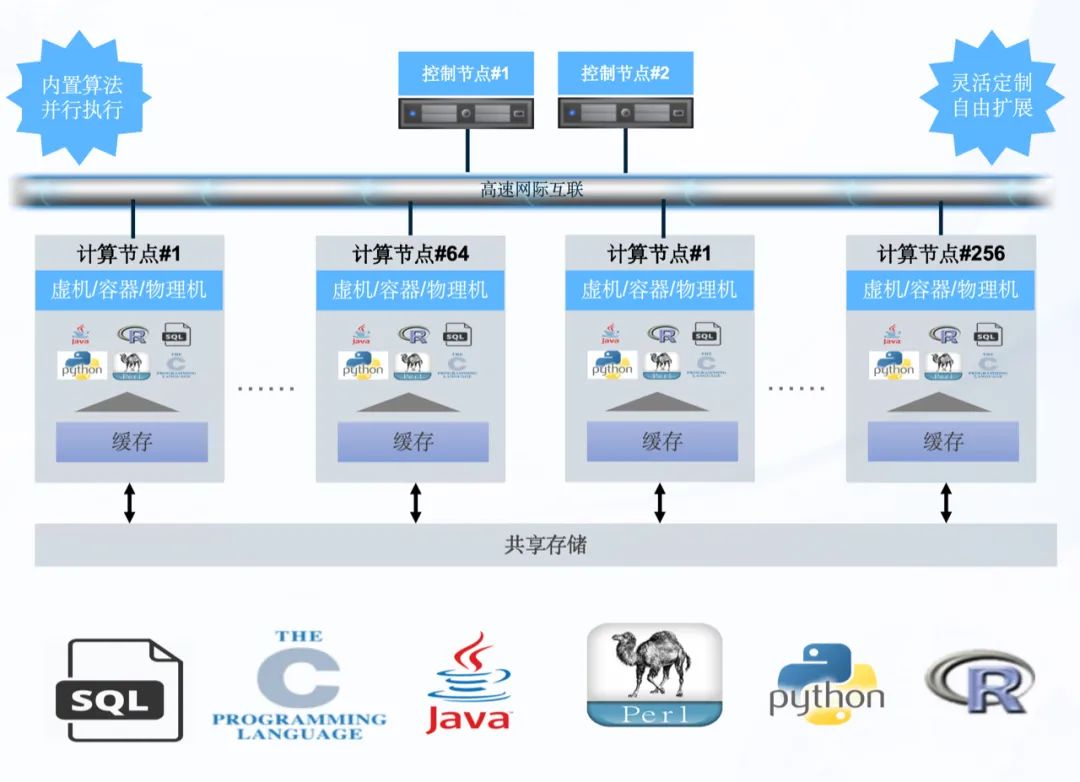 CloudberryDB灵活部署形态
CloudberryDB灵活部署形态 CloudberryDB产品兼容生态
CloudberryDB产品兼容生态
CloudberryDB正在以国际标准、高点定位、全球眼光的运营理念,构建开放、友好、中立的开源社区。我们也期待有更多的开源爱好者加入我们,为开源世界贡献我们的一份力量。CloudberryDB GitHub 地址:https://github.com/cloudberrydb/cloudberrydb,欢迎大家访问体验。
参考链接:1、PG 17 Beta1版发布官方新闻:https://www.postgresql.org/about/news/postgresql-17-beta-1-released-2865/2、PG 17 Beta1版发布说明:https://www.postgresql.org/docs/17/release-17.html3、PG 17 Beta1版下载地址:https://www.postgresql.org/download/
这篇关于PostgreSQL 17 Beta1 发布,酷克数据再次贡献核心力量的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






