本文主要是介绍中国250米全钾(tk)含量数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
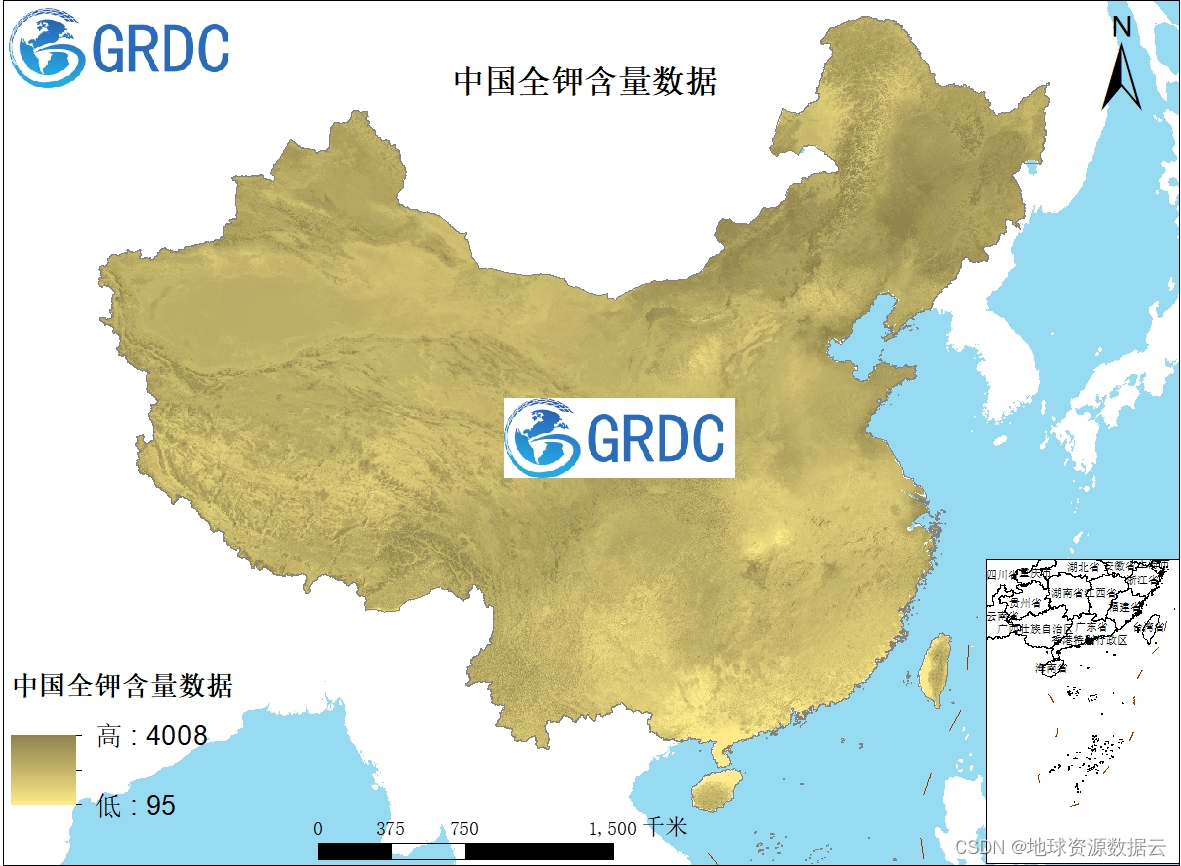
全钾是指土壤中含有的全部钾。是水溶性钾、交换性钾、非交换性钾和结构态钾的总和。土壤全钾含量为0.3%〜3.6%,一般为1%〜2%。全钾仅反映了土壤钾素的总储量.其中90%〜98%在相当长时间内是无效的,因此全钾值不能用以指导施肥。
土壤中的钾包括3种形态:①矿物钾。主要存在于土壤粗粒部分,约占全钾的90%左右,植物极难吸收。②缓效性钾。约占全钾的2%~8%,是土壤速放钾的给源。③速效性钾。指吸附于土壤胶体表面的代换性钾和土壤溶液中的钾离子。植物主要是吸收土壤溶液中的钾离子。当季植物的钾营养水平主要决定于土壤速效钾的含量。一般速效性钾含量仅占全钾的0.1%~2%,其含量除受耕作、施肥等影响外,还受土壤缓放性钾贮量和转化速率的控制。一般来说,土壤全钾含量在1500mg/kg以下被认为是低钾土壤,1500-2000mg/kg算作中等钾土壤,2000mg/kg以上算作高钾土壤。如果土壤中的全钾含量过高,将会对作物的生长产生不利影响,甚至有可能导致植物死亡。
土壤全钾含量栅格数据在以下领域具有广泛的应用:
农业生产:评估土壤钾肥需求,指导科学施肥,优化种植方案,提高作物产量和质量。
土壤科学研究:分析土壤钾含量的空间分布和变化规律,为研究土壤肥力提供基础数据。
生态环境保护:评估土壤钾元素的生态效应,制定生态保护和环境治理措施。
土地管理:支持土地规划与利用,进行土壤改良和肥力评价。
土壤全钾数据来源于中国高分辨率国家土壤信息格网基本属性数据集(2010-2018),数据为250米分辨率,包括0-200cm六个土层数据。坐标系为Albers_Conic_Equal_Area,数据放大了100倍,使用时应*0.01,数据单位g/kg。

欢迎大家关注、收藏和留言,如果您想要什么数据,可以在搜索网址地球资源数据云,我会分享更多的好的数据给大家~~~~~
以上是关于中国250米全钾(tk)含量数据详情,欢迎小伙伴们一起学习和分享。
这篇关于中国250米全钾(tk)含量数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







