本文主要是介绍Apple HEVC Stereo Video,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 前言
为左眼和右眼携带立体视频视图的能力产生了更丰富的用户体验。 立体视频(有时称为“3D 视频”)向用户的左眼呈现一个图像,向用户的右眼呈现另一幅图像(通常是相关的)以产生立体效果,定义为:大脑接收双眼视觉刺激而产生的深度知觉; 双眼视觉。
如下图,左眼一幅图,右眼一幅图,同时播放在加上apple眼镜的渲染,就形成3D效果。

Apple的立体视频也是以上的模式,这里介绍Apple定义的HEVC在mp4中的3D视觉如何构造格式box和其特点。
主视觉可以是左眼,也可以是右眼。下面为了方便叙述,左眼为主视觉,右眼为子视觉。
1.1 Apple HEVC Nalu
HEVC NALU头:
+---------------+---------------+
|0|1|2|3|4|5|6|7|0|1|2|3|4|5|6|7|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|F| Type | LayerId | TID |
+---------------+---------------+F: forbid,如果使能,该nalu就无效,一般f都为0;
type: nalu类型
layerId: 空间层,常规都是0,但是在apple hevc stereo中,主视觉layerId=0, 子视觉layerId=1
tid: 时间层
两个连续nalu的例子:
video data dts:50, pts:133, len: 2280, hevc header:{"forbid":0,"nalu_type":1,"layer_id":0,"tid":1}
video data dts:50, pts:133, len: 1981, hevc header:{"forbid":0,"nalu_type":1,"layer_id":1,"tid":1}
如上:
主视觉,dts=50,layer_id=0
子视觉,dts=50,layer_id=1
两个nalu的dts和pts一样,通过layer_id的不一样,来标识主视觉和子视觉。
注意: 通过layer_id的不同来标识主视觉和子视觉,这样能实现播放器的前后兼容。
新播放器(支持apple hevc stereo, vision pro),能通过layerId=0和1,来识别主视觉和子视觉;
旧播放器(不支持apple hevc stereo),只能识别layerId=0,只能识别主视觉,也就是当作普通的视频来播放,从而实现前后兼容。
2. mp4中的hevc stereo
2.1 stsd box中的hvc1
stsd box主要用于存放音频/视频的sequenc header信息,如果是H264编码,其中就是存放的avc1格式的sps+pps;如果是H265编码,这里就是存放的是hvc1,其包含vps+sps+pps;

如上stsd box中,包含hvc1 box,hvc1 box自身的关键信息有:
//字段顺序如下,字段大小也如下
typedef struct
{uint32_t reserved1_ = 0;uint16_t reserved2_ = 0;uint16_t data_reference_index_ = 0;uint16_t codec_stream_version_ = 0;//Reserveduint16_t codec_stream_reversion_ = 0;//Reserveduint32_t reserved3_[3];uint16_t width_ = 0;uint16_t height_ = 0;uint32_t horizontal_resolution_ = 0;uint32_t vertical_resolution_ = 0;uint32_t data_size_ = 0;//Reserveduint16_t frame_count_ = 0;//frame cout == 1char compressorname_[32];//0 for defaultuint16_t alpha_ = 0x18;uint16_t reserved4_ = 0xffff;
} HVC1_INFO;hvc1 box中包含的子box比较多,其中比较中要的有:
- hvcC box:主视觉的vps+sps+pps,比如:左眼视觉
- lhvC box(新增): 子视觉的sps+pps,比如:右眼视觉
- vexu box(新增): apple hevc stereo独有的box,后面单独介绍
重要信息:lhvC box和vexu box都是apple新增的box,主要用于hevc stereo(3D视觉),这里支持对旧版本播放器的兼容,因为旧版本播放器(不支持3d)并不认识lhvC和vexu这两个box,所以仅仅只解析hvcC box,也就是主视觉的vps+sps+pps,这样旧的播放器一样能播放该视频文件(当作2d的视频来播放,也就是只播放左眼视觉的图片)
总结: 这种格式是能对2d和3d都兼容播放
- 新播放器(支持apple hevc stereo, vision pro):同时解析hvcC(左眼)和lhvC(右眼),最后播放的是3D效果;
- 旧播放器(不支持apple hevc stereo):仅仅解析hvcC,把视频当作是2d普通视频来播放,一样能看。
2.1.1 hvcC box
该box包含的关键信息:
//具体的vps或sps或pps数据信息
typedef struct HEVC_NALU_DATA_S {std::vector<uint8_t> nalu_data;
} HEVC_NALU_DATA;typedef struct HEVC_NALUnit_S {uint8_t array_completeness;
// nal type一般为: vps(32), sps(33), pps(34)uint8_t nal_unit_type;
//vps或sps或pps的个数uint16_t num_nalus; std::vector<HEVC_NALU_DATA> nal_data_vec;
} HEVC_NALUnit;typedef struct HEVC_DEC_CONF_RECORD_S {uint8_t configuration_version;uint8_t general_profile_space;uint8_t general_tier_flag;uint8_t general_profile_idc;uint32_t general_profile_compatibility_flags;uint64_t general_constraint_indicator_flags;uint8_t general_level_idc;uint16_t min_spatial_segmentation_idc;uint8_t parallelism_type;uint8_t chroma_format;uint8_t bitdepth_lumaminus8;uint8_t bitdepth_chromaminus8;uint16_t avg_framerate;uint8_t constant_frameRate;uint8_t num_temporallayers;uint8_t temporalid_nested;//mdat box中前面多少字节为长度,一般是4字节(lengthsize_minusone+1)uint8_t lengthsize_minusone;std::vector<HEVC_NALUnit> nalu_vec;
} HEVC_DEC_CONF_RECORD;为了支持左右立体眼睛视图,SPS和PPS,它们几乎相同,仅在立体眼睛分配和绑定到 nuh_layer_id 值方面有所不同。
两个SPS(主视觉与子视觉):
- 两个sps的 sps_video_parameter_set_id 均应等于 0。
- 两个sps应指示两个立体眼睛视图的相同特征,例如width, height, bitDepth, chromaFormat 和 conformanceWindow。 这可以在第二层中通过使用 update_rep_format=1 或通过为相应的 seq_parameter_set_rbsp 字段显式设置相同的值来完成
- 基础层SPS 可以具有指示video_full_range_flag = 0 或video_full_range_flag = 1 的vui_parameters。两个层应具有相同的标志
- 两个序列参数集应指示相同的亮度和色度位深度,但可以是 8 位或 10 位
两个PPS(主视觉与子视觉):
- 一个用于主视觉,nuh_layer_id 等于0,pps_seq_parameter_set_id 等于0,pps_pic_parameter_set_id 等于0。这对应于主眼视觉。
- 一个用于子视觉,其中 nuh_layer_id 等于副眼 nuh_layer_id,一般为1,并且 pps_seq_parameter_set_id 等于副眼层 SPS ID,并且 pps_pic_parameter_set_id 等于非零数字,此处称为副眼层 PPS ID。
- 所有参考帧必须与引用它们的图片具有相同的 CTB 大小
VPS(仅仅在hvcC中有,lvcC中没有):
主要用传输视频分级信息,有利于兼容可分级视频以及3D视频,如视频包含最大的层级,也可包含profile,level等信息。一个给定的视频序列,无论它的SPS是否相同,都参考相同的VPS.
一个视频参数集 (VPS),nuh_layer_id 等于 0,vps_video_parameter_set_id 等于 0,并且包含 vps_extension.
- vps_max_layers_minus1 应至少为 1,表示两层,一层用于左眼,一层用于右眼。 仅支持纹理层。
- 基础层应出现在 MV-HEVC 比特流中,VPS 中的 vps_base_layer_internal_flag 和 vps_base_layer_available_flag 应具有值 1。
- vps_extension具有左眼和右眼的viewID,指示出layer_id_in_nuh[]、scalability_mask_flag[]、dimension_id [][]、view_id_val[]和direct_dependency_flag[][]语法元素的值,以将纹理层与左眼和右眼相关联,并映射到在 三维_reference_displays_info SEI 消息。 有关如何根据 nuh_layer_ids 建立 left_view_id[0] 和 right_view_id[0] 的描述,具体在后面的附录中给出。
2.1.2 lhvC box
lhvC中
SPS:
- nuh_layer_id 应等于副眼 nuh_layer_id(一般为1),并且 sps_seq_parameter_set_id 等于非零数字,此处称为副眼 SPS ID(一般为1)
- 推荐SPSID为1标识右眼
- 接受副眼层 SPS ID 的非零值,并识别副眼 PPS 的 pps_seq_parameter_set_id 字段中的值
PPS:
- nuh_layer_id 应等于子视觉 nuh_layer_id(一般为1),并且pps_seq_parameter_set_id 等于子视觉SPS ID,并且 pps_pic_parameter_set_id 等于非零数字,此处称为子视觉PPS ID;
- 推荐子视觉PPS ID为1;
- 接受副眼 PPS ID 的非零值,并在视频切片 slice_pic_parameter_set_id 字段中识别视频帧的副眼部分中的值
2.1.3 小结

如上,
主视觉,nah_layer_id = 0; 子视觉nah_layer_id = 1;
hvcC box中含vps, sps, pps, 和3d sei。
其中VPS中vps_video_para_set_id = 0; SPS中sps_seq_para_set_id = 0; PPS中pps_pic_param_set_id = 0;
lhvC(子视觉), SPS中sps_seq_para_set_id = 1; PPS中pps_pic_param_set_id = 1;
在mdat box中的具体数据,
主视觉帧: dts:50, pts:133, len: 2280, hevc header:{"forbid":0,"nalu_type":1,"layer_id":0,"tid":1}
子视觉帧: dts:50, pts:133, len: 1981, hevc header:{"forbid":0,"nalu_type":1,"layer_id":1,"tid":1}
也就是通过nalu header中的layer_id的不同来标识该帧是主视觉,还是子视觉;
2.2 Video Extended Usage (‘vexu’) box
vexu box仅仅在stereo的3d播放时有用,其余的时候可以忽略。
vexu box内部包含的子box:
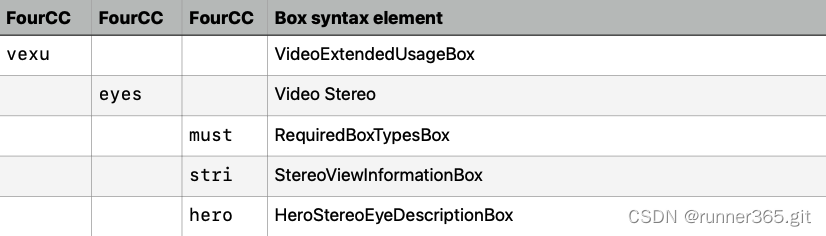
2.2.1 must box
aligned(8) class RequiredBoxTypesBox extends FullBox(‘must’, 0, 0 ) {unsigned int(32) required_box_types[];
}这个box不是必须的;
2.2.2 stri box
必须有。
aligned(8) class StereoViewInformationBox extends FullBox(‘stri’, 0, 0) {unsigned int(4) reserved; // reserved, set to 0unsigned int(1) eye_views_reversed;unsigned int(1) has_additional_views;unsigned int(1) has_right_eye_view;//video contains a right-eye viewunsigned int(1) has_left_eye_view;//video contains a left-eye view
}has_left_eye_view:表示立体左眼出现在视频帧中 has_right_eye_view:表示立体右眼出现在视频帧中
has_additional_views:表示除了立体左眼和立体右眼之外,可能还存在一个或多个其他视图(例如,“中心线”视图)
eye_views_reversed:表示立体左眼和立体右眼的顺序与默认的左眼第一右眼第二顺序相反
2.2.3 hero box
这个box不是必须
aligned(8) class HeroStereoEyeDescriptionBox extends FullBox(‘hero’, 0, 0)
{unsigned int(8) hero_eye_indicator; // 0 = none, 1 = left, 2 = right, >=
3 reserved
}
hero_eye_indicator:用于 HeroStereoEyeDescriptionBox,用于指示指定了哪个英雄眼(如果有)。
这篇关于Apple HEVC Stereo Video的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







