本文主要是介绍十三年沉淀之路,百度智能云 Redis 服务背后的故事,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
十三年沉淀之路
近日,Redis Labs 宣布将其开源协议从 BSD 3-Clause 修改为 SSPLv1 和 RSALv2 的双重许可。并于 Redis 7.4 版本后关闭开源 BSD 软件分发协议。同时,Redis Inc. 已于 2020 年 7 月买断Redis社区后停止了以Core Member为核心的社区管理方式 ,后续开发由 Redis Inc. 全权管理。
在 Redis Inc. 修改协议之后,社区成员快速做出反应,由原来 Redis 社区的多名核心开发者全新组建了 Valkey 社区,并捐献给 Linux 开源基金会进行运营。在 4 月 16 日召开的 Linux 基金会北美开源峰会上发布全新版本 Valkey 7.2.5。
Redis 作为一款高性能内存数据库,诞生于开源,今天能广泛流行,开源是重要原因,但是也离不开社区,云厂商,用户的共同推动。百度作为互联网厂商,内存数据库的使用场景和使用量一直很大,因此对 Redis 有深度的使用。同时百度有很多场景,Redis 开源版本并不能满足,百度智能云 Redis 产品一直是「自研+开源」来提供服务。
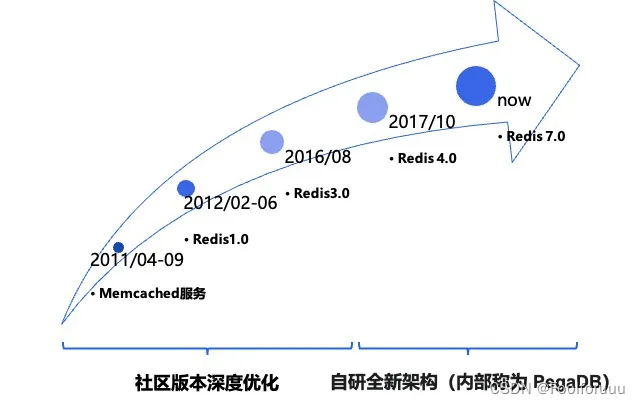
在过去的十几年时间内,百度内存数据库,一直在结合内外部场景进行演进,主要分为两个阶段
-
从 Redis 1.0~3.0 基于开源深度优化阶段,。
-
从 Redis 4.0 为了解决 Redis 能支持持久存储的能力,在跟进开源 Redis 的基础上,开始全新架构自研阶段,内部称为 PegaDB,接下来我们简单来梳理下百度内存数据库的十三年沉淀和演进之路。
同时,百度智能云云数据库特惠专场开始!热销规格新用户免费使用,欢迎参与!
社区版本深度优化:Redis 1.0 ~ Redis 3.0
早在 2011 年,百度数据库团队就已经使用 Memcache 服务处理其缓存需求,当时缓存雪崩问题是其中比较关键的一个技术挑战,Memcache 在遭遇宕机时往往会导致缓存雪崩问题,即请求直接穿过缓存层,落到数据库层,对数据库造成巨大压力。这不仅降低了应用的性能,也增加了系统的不稳定性。
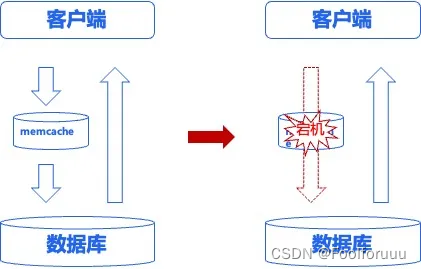
为了解决这一问题,百度数据库团队认识到,需要一个具备更高可用性和更丰富特性的缓存解决方案。Redis 以其高性能、支持数据持久化、以及丰富的数据结构被视为理想的替代品。最重要的是,Redis 的复制 (replication) 和持久化特性可以有效减少因宕机导致的缓存雪崩问题。
2012 年,百度数据库团队开始在内网大规模使用 Redis 2.6 版本,并基于 Redis 进行了优化,Baidu Redis 1.0(内部称为 BDRP)。当时,虽然 Redis 已经被广泛应用于各种场景,但社区版的 Redis 由于其单分片限制,已经无法满足日益增长的数据处理需求,而支持多分片就需要考虑负载均衡和读写分离的场景,因此通过自研的 proxy 以及支持 nshead 协议的实现,他们不仅实现了读写分离和负载均衡,还通过 Redis 的持久化机制,有效地缓解了缓存雪崩问题。即使在宕机的情况下,Redis 的快照 (RDB) 和 AOF(append-only file) 机制也能保证数据的恢复,大大减少了直接请求数据库的情况。
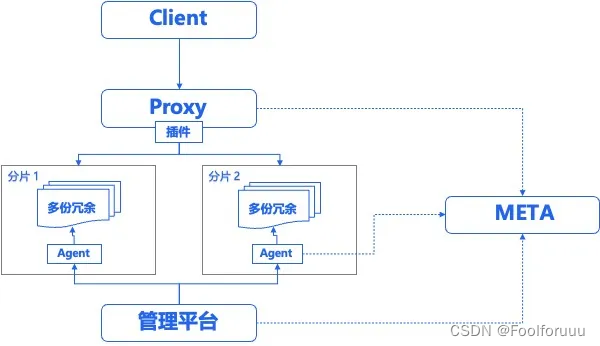
此外,百度数据库团队对 Redis 的使用策略进行了深度优化,这涵盖了持久化策略的合理配置、内存管理的优化以及定制化功能的开发。其中,为了满足特定业务需求的实现了如下功能,例如同源增量数据同步(已在 4.0 版本社区中支持)、弹性扩缩容(支持槽粒度迁移,这一特性在3.0版本的社区中已实现 slot 扩缩容),以及多地域就近访问等,这些功能可以显著提升了系统的稳定性和性能。
此外,他们还将部分关键特性,如 rdb-only 复制、共享复制缓冲区以及减少 COW 内存等,合入到Redis的社区版。据统计,已累计向社区提交了超过60个 PR(Pull Request)。通过在开源社区版本上深度改进,Redis 从 1.0 一直演进到 3.0。
自研全新架构:Redis 4.0~ Redis 7.0
虽然基于 Redis 开源版本研发解决了部分问题,但随着数据量的爆炸式增长,存储成本和管理复杂度成为了新的挑战。
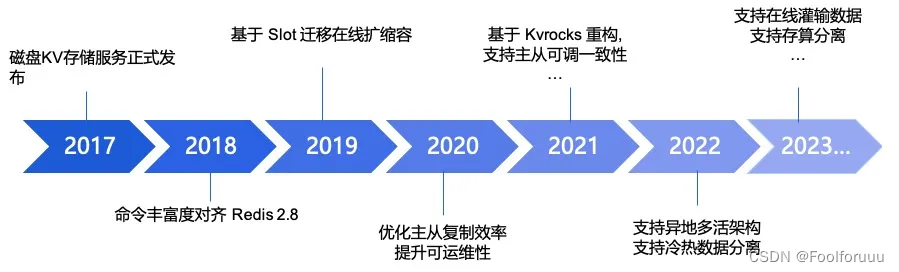
特别是对于度秘业务,当时由于 DuerOS 后端的大量数据都存储在 Redis 中,如会话记录和用户信息,仅 2018 年 1 月设备数已经超过 5000w,月活跃设备超过 1000 万,迅猛增长的数据量导致线上多次出现容量不足的问题,而传统的内存数据库解决方案成本过高,无法满足长期需求。此外,对于度秘的某些业务场景来说,其 QPS 需求并不高(1kB value 下单盘<1W QPS),且对时延的要求相对宽松(99.5%小于 10ms)。这意味着,如果能开发一套兼容 Redis 协议,完全自研架构的磁盘缓存解决方案,不仅能满足业务需求,还能显著降低成本。而怎么降低成本也是 Redis 客户的核心需求。为了更好地服务客户,百度数据库团队亟需研发基于磁盘的缓存产品。在 2017 年启动了基于 RocksDB 的创新型数据库产品——PegaDB 的研发。这款产品的核心理念是与 Redis 实现高度兼容,同时主打基于磁盘的存储方式,从而颠覆传统内存数据库的存储模式。
PegaDB 不仅成功实现了与 Redis 的无缝对接,更在存储成本上取得了显著突破,相较于传统内存数据库,成本节约了超过 90%。这一创新成果不仅为百度度秘业务提供了强大的数据支持,更为百度及其他业务部门获得了高效且经济的数据存储解决方案。
从 2017 年 PegaDB 初步推出磁盘 KV 存储服务以来,随着版本的迭代,PegaDB 增加了命令的丰富度,加强了系统的可扩展性和弹性,提升了主从复制的效率,进一步保障了数据的安全性。到了最新版本 PegaDB,已经能够支持在线数据灌输和存算分离。下图是过去主要的一些能力演进:
在经历了从 Redis 增强能力,以及自主研发全新架构 PegaDB 以应对成本和扩展性挑战后,百度的数据处理能力和规模已经非常大的规模。截至目前, 百度智能云 Redis 的节点规模预估已经超过 几十 w 个,每日请求达到万亿的规模,数据量也达到 PB 级别,这样的数据处理量在业界也算是 top 级别的规模。
值得一提的是,Redis 服务 经过多年的发展,还拥有传统内存数据库所不具备的几大特性:
-
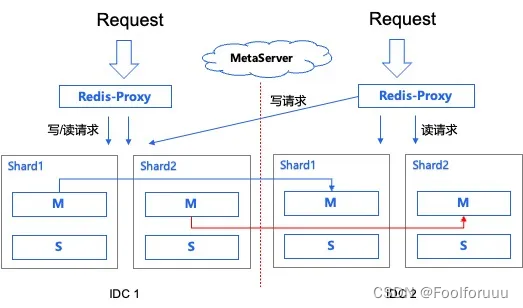
首先是异地多活功能,确保数据在多个地理位置的节点上都能保持实时同步和高度可用;
-
其次是半同步复制技术,能够在确保数据一致性的同时,最大限度地减少延迟;
-
最后,其全量同步过程无需进行传统的 fork 操作,从而简化了数据迁移和备份的复杂性。
展望:云边一体,高效智能
随着市场对数据处理和存储技术的需求激增,特别是在数据爆炸和 AI 技术不断发展的今天,云计算的中心化处理能力将与边缘计算的分布式、低延时特性相结合,形成一个统一、协同的云边一体计算网络,这种架构将会对服务提出更高的要求,百度数据库团队既面临挑战也看到机遇。通过技术创新和自研,成功从开源 Redis 演变到自研 PegaDB 。未来,希望持续提升 Redis 产品的数据处理效率,融合 AI 技术,并支持云和边缘计算,为用户提供更优质稳定,高效智能的服务,保持行业领先地位。
这篇关于十三年沉淀之路,百度智能云 Redis 服务背后的故事的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



