本文主要是介绍争当大模型时代基础设施,大厂打响大模型价格战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大模型的价格正在进入一个比低更低的时代。只是,让价格成为竞争主导因素,是否会有些操之过急?本文作者分享了他的观点和分析,一起来看。

似乎,每一家厂商都有一个成为大模型时代基础设施的梦想,为此,一场大模型玩家间的价格战已然打响。
继5月15日字节跳动宣布豆包大模型降价之后,阿里和百度又进一步将大模型价格战升级—— 21日,阿里云官方宣布对通义千问9款商业化和开源模型的价格进行大幅降价;同日,百度宣布文心大模型的两款主力模型ENIRE Speed、ENIRE Lite全面免费。
一、大模型价格进入比低更低时代
随着字节、阿里和百度等大型玩家入局,并且在价格上一降再降,大模型的价格也正在进入一个比低更低的时代。
如我们所见:
距字节跳动公司宣布其下调后的豆包大模型价格已经击穿了大模型行业的最底价仅仅过去一周,阿里云就将通义千问对标GPT-4的主力模型Qwen-Long输入价格降至0.0005元/千tokens(文本处理的最小单元),降幅达97%,这一价格比此前豆包大模型降价后的0.0008 元/千 Tokens的价格便宜0.0003元;
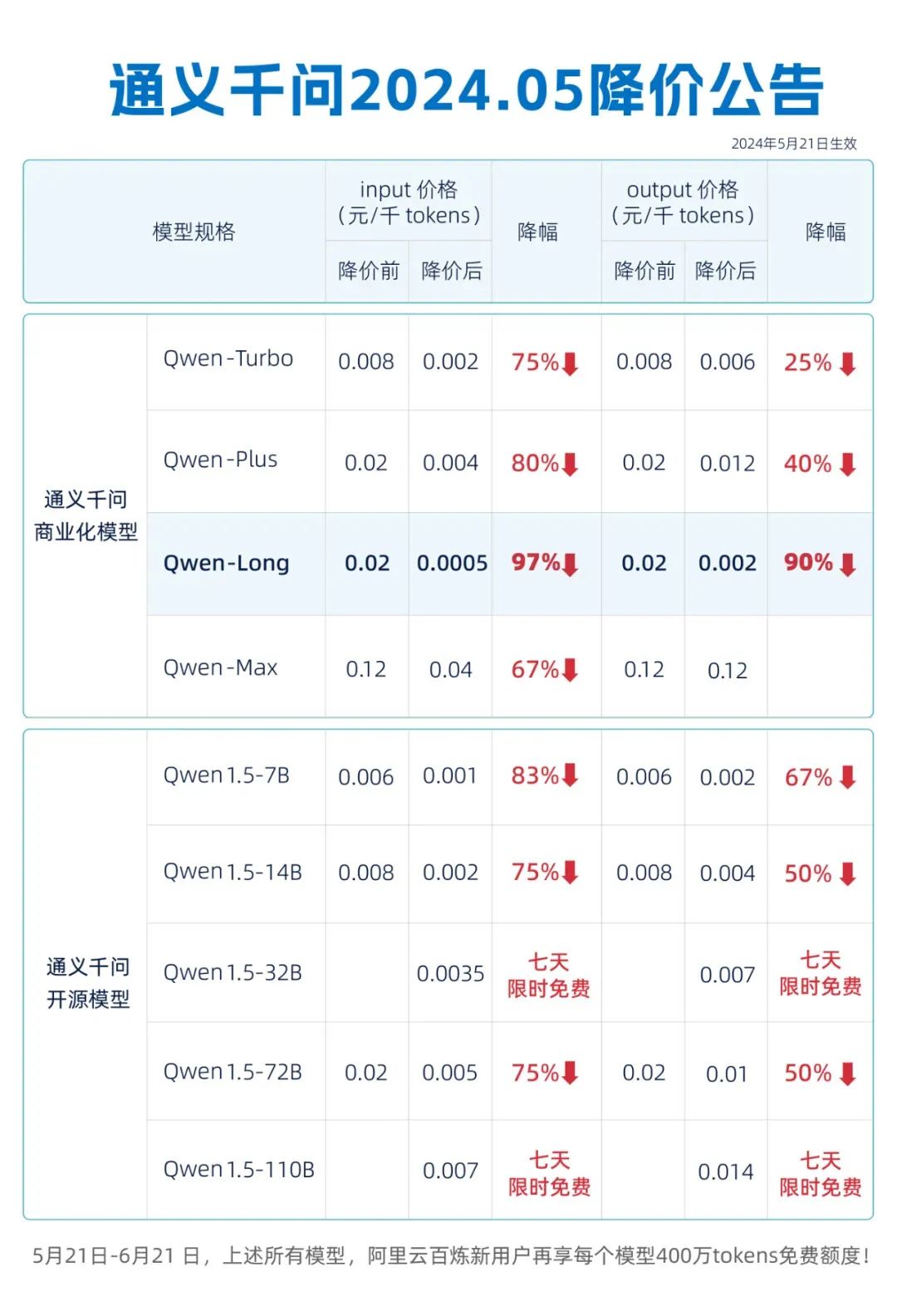
更为直观的对比是:降价后,用户花一元钱可以买到豆包主力模型的125万Tokens;同样花一元在通义千问上,则最多可以买到200万tokens。
 做了8年产品经理后,我是这么看产品经理的我个人是从非常初级的产品经理做起,再到负责一个大产品的项目管理,现在有幸跳出了日常基础的工作更多的去看产品的PMF,product strategy…查看详情 >
做了8年产品经理后,我是这么看产品经理的我个人是从非常初级的产品经理做起,再到负责一个大产品的项目管理,现在有幸跳出了日常基础的工作更多的去看产品的PMF,product strategy…查看详情 >
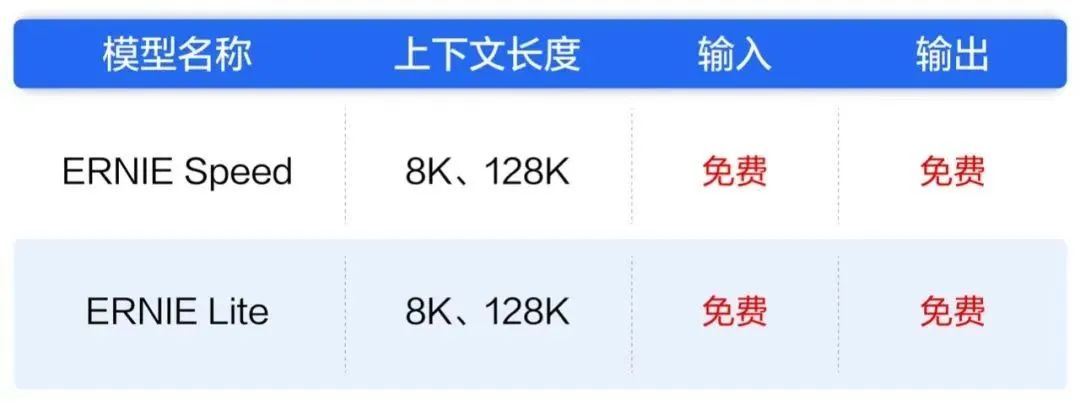
而百度则更进一步,直接宣布将其目前调用量最大的两款主力模型ENIRE Speed和ENIRE Lite全面免费,宣称其开启了大模型API(应用程序编程接口)调用的“免费时代”。
随着字节跳动、阿里和百度打响大模型价格战,也可预见的是,其他尚未做出反应的大模型厂商,在接下来的时间里,也或都将被迫卷入这场大模型价格战中。
一大基本现实是:当前,国内头部大模型玩家们在整体能力差异上,可能并不存在绝对领先的情况,大家都是处于趋同的存在,有的只是在能力上的各有特点与侧重。而这些差异化等能力若一旦被市场认可,大家也会迅速跟进实现差距抹平乃至反超先行者。
长文本处理能力,就是显著一例:
此前,月之暗面公司的Kimi Chat因可处理高达200万字的长文本推理能力而火爆出圈。对此,阿里、百度、360等公司也迅速做出反应,宣称将推出比Kimi能力更强的长文本处理能力,其长文本处理能力也从Kimi Chat的200一路攀升至阿里通义千问的1000万字长文本。
如此现实:其他大模型厂商们若不跟进阿里、百度、字节的这一波价格战,除非其能拥有绝对领先的技术能力,否则,就可能只有被市场淘汰的份儿。毕竟在当前现实下,想要维持原本价格本已是一件难事儿,更何况当前这几大大模型厂商已经开始让用户尝到了更便宜乃至免费的滋味了。
而这对于诸多自身造血能力不足,极度需要融资输血的玩家而言,则显然不是一个好消息。
二、争当大模型基础设施供应商
大模型推理成本的大规模下降,是字节、阿里和百度在这轮降价力度上一家比一家狠的底气所在——百度在2月份财报电话会议上上,李彦宏就曾表示:自文心大模型发布以来,百度不断降低其推理成本,目前已降至去年3月版本的1%。
但从现实来说,推理成本下降可能并非是此轮厂商们调低价格的动力所在,厂商们降价的核心逻辑其实与过去互联网上演的多轮价格战是如出一辙。
在用更低价格吸引更多开发者和用户使用大模型进行AI应用开发、训练,激活市场对大模型的调用需求,在实现放水养鱼、做大蛋糕的同时实现跑马圈地,进而成为大模型时代的基础设施供应商。
这种价格打法,过去多年在许多行业已然奏效——从外卖到打车再到云计算,无不如此。
以云计算为例,事实上时至今日,价格依旧是影响云计算厂商竞争的重要因素,是扩充份额的有效手段。
诸如阿里云,其在今年2月末在国内市场就进行了一场所谓史上最大力度降价,100多款产品、500多个产品规格的官网价格平均降低20%,最高降幅55%;随后在4月份阿里云又面向海外市场宣布全球13个地域节点全线下调产品价格、平均降幅23%、最高降幅59%,覆盖五大类产品、500+产品规格。
大降价也带来了颇为显著的效果——据阿里巴巴集团发布的2024财年Q4及全年业绩报告数据显示:2024年一季度,阿里云季度营收同比增长3%至255.95亿元,核心公共云产品收入实现两位数增长,AI相关收入实现三位数增长,阿里云经调整EBITA同比增长45%至14.32亿元。
当然,这种打法也并非无往不利,其也有相应的弊端乃至会造成最终的一地鸡毛,过去的共享单车价格战就是惨痛教训。
在此,也希望大模型的价格战不要步入这样的后尘。
写在最后
在ChatGPT爆火以来,国内市场在短短两年时间里,就完成了从人人入局大模型的百模大战到大厂降价开启价格战进行市场跑马圈地的跃升,无疑,这展现了国内市场在大模型技术成本方面的长足进步,亦是国内市场竞争活力的体现。此轮降价,业内也多认为这将进一步激活市场对大模型需求,做大大模型整体市场蛋糕。
只不过,在当前大模型技术仍旧还处于发展探索期,其相关成本虽有下降但依旧高昂(特别是算力成本)的整体现实下,大厂商们就已急着跑马圈地,有意让价格成为竞争主导因素,是否会有些操之过急?
所以,这轮大模型价格战,究竟是会进一步激活厂商们通过技术优化降低成本的能力,还是会将厂商拖入价格战泥潭而无暇顾及技术长期主义,最终闹得一地鸡毛,唯有时间能给出答案。
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词
- L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节
- L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景
- L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例
- L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓
这篇关于争当大模型时代基础设施,大厂打响大模型价格战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









