本文主要是介绍【云原生进阶之数据库技术】第二章-Oracle-原理-4.3.4-数据区(Extent)结构剖析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

1 数据区(Extent)
1.1 数据区概述
数据区表示一系列连续的数据块集合。当一个表、回滚段或临时段创建或需要附加空间时,系统总是为之分配一个新的数据区。一个数据区不能跨越多个文件,因为它包含连续的数据块。使用区的目的是用来保存特定数据类型的数据,也是表中数据增长的基本单位。一个Oracle对象包含至少一个数据区。设置一个表或索引的存储参数包含设置它的数据区大小。
在进行存储数据信息的时候,Oracle将分配数据块进行存储,但是不能保证所有分配的数据块都是连续的结构。
举个例子来说,当我们创建一个表时,首先ORACLE会分配一区的空间给这个表,随着数据不断地增长,原来的这个区容不下插入的数据时,ORACLE是以区为单位进行扩展的,也就是说再分配多少个区给这个表,而不是多少个块。
视图dba_extents(或者all_extents、user_extents)是我们研究分区结构和存储构成的重要手段。
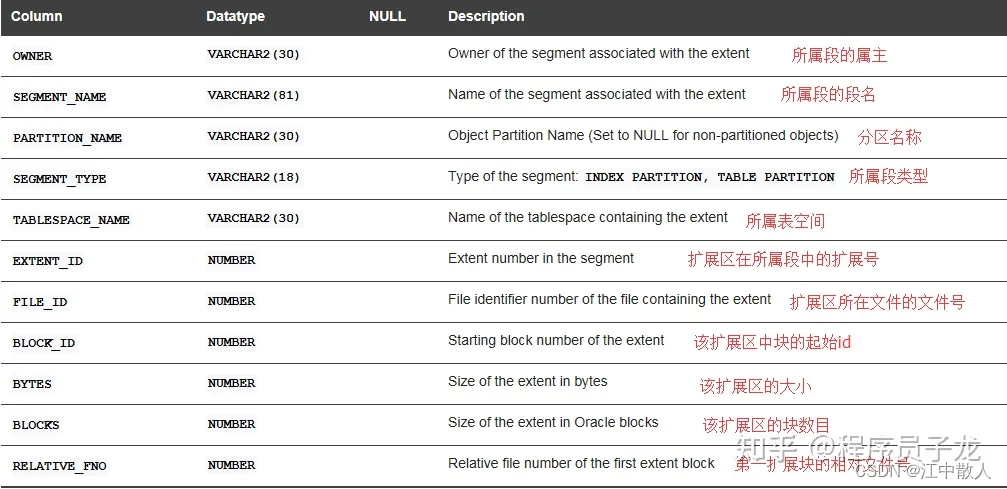
1.2 区的分配
默认地,在创建段时,数据库会为每个被创建的数据段(data segment)分配一个初始的区(initial extent)。一个区始终存储在一个数据
这篇关于【云原生进阶之数据库技术】第二章-Oracle-原理-4.3.4-数据区(Extent)结构剖析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





