本文主要是介绍微服务学习Day11-缓存问题学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 多级缓存引入
- JVM进程缓存
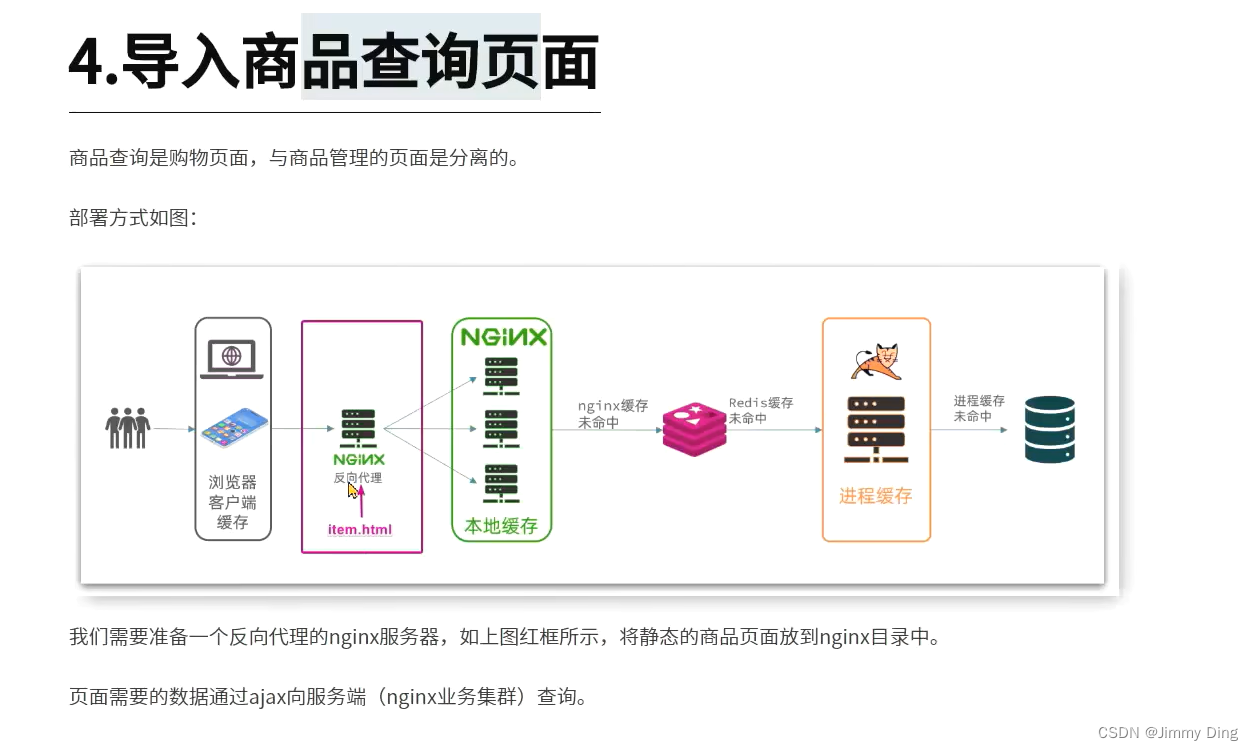
- 导入商品案例
- Caffeine学习
- 实现进程缓存
- Lua语法入门
- 认识Lua
- 变量和循环
- 条件控制、函数
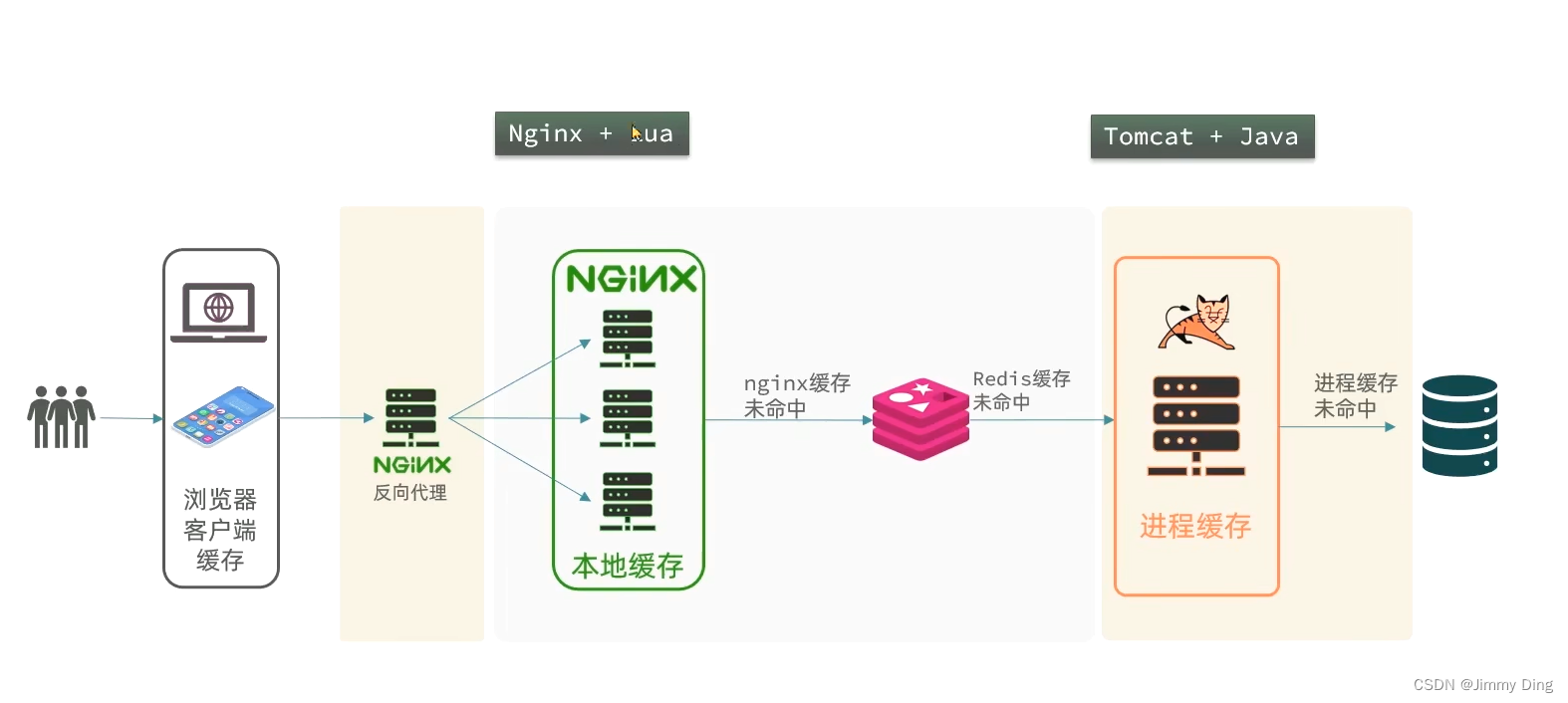
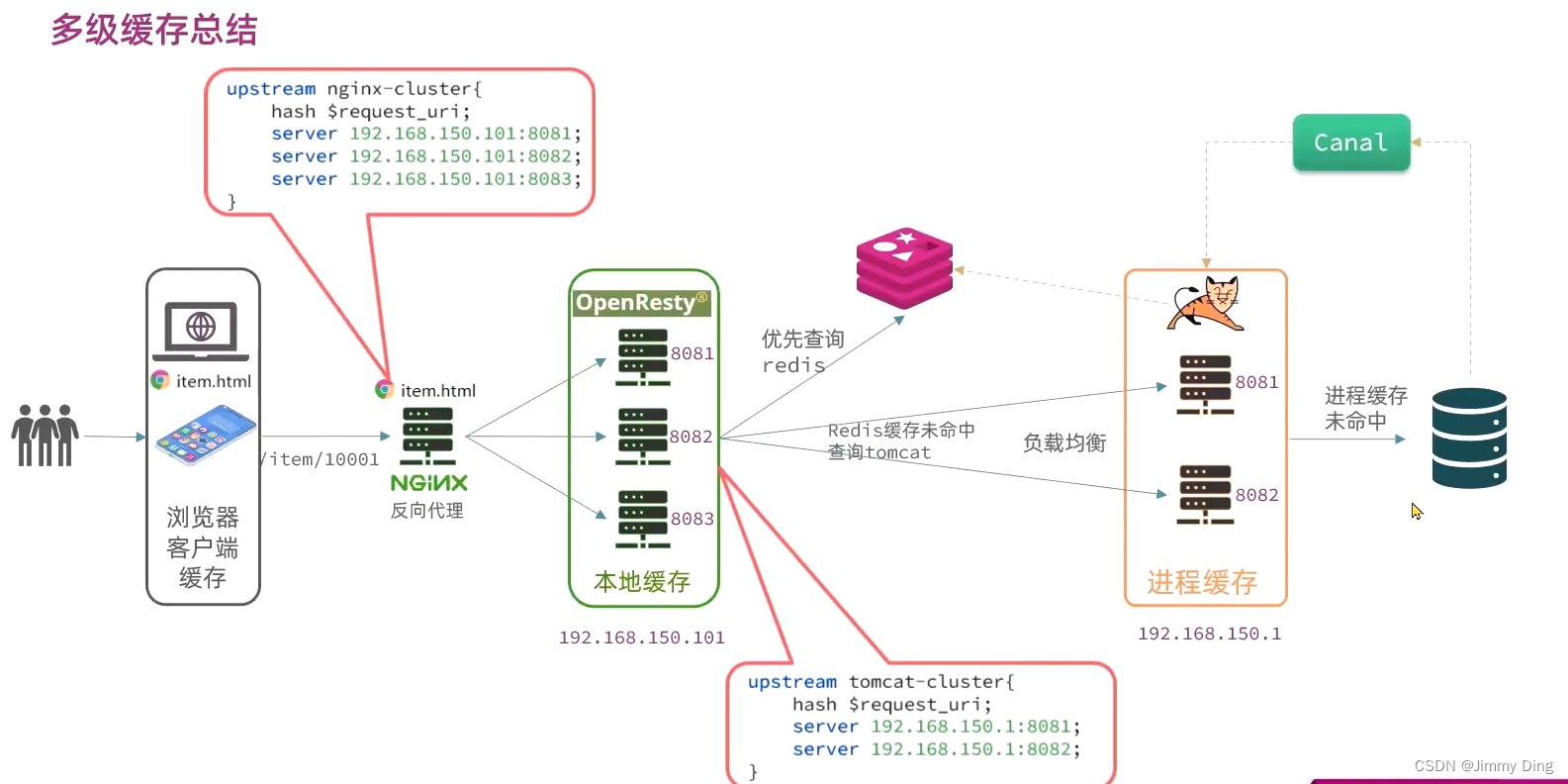
- 多级缓存
- 安装OpenResty
- OpenResty入门
- 请求参数处理
- 查询Tomcat
- Redis缓存预热
- 查询Redis缓存
- Nginx本地缓存
- 缓存同步策略
- 策略
- 安装Canal
- 监听Canal
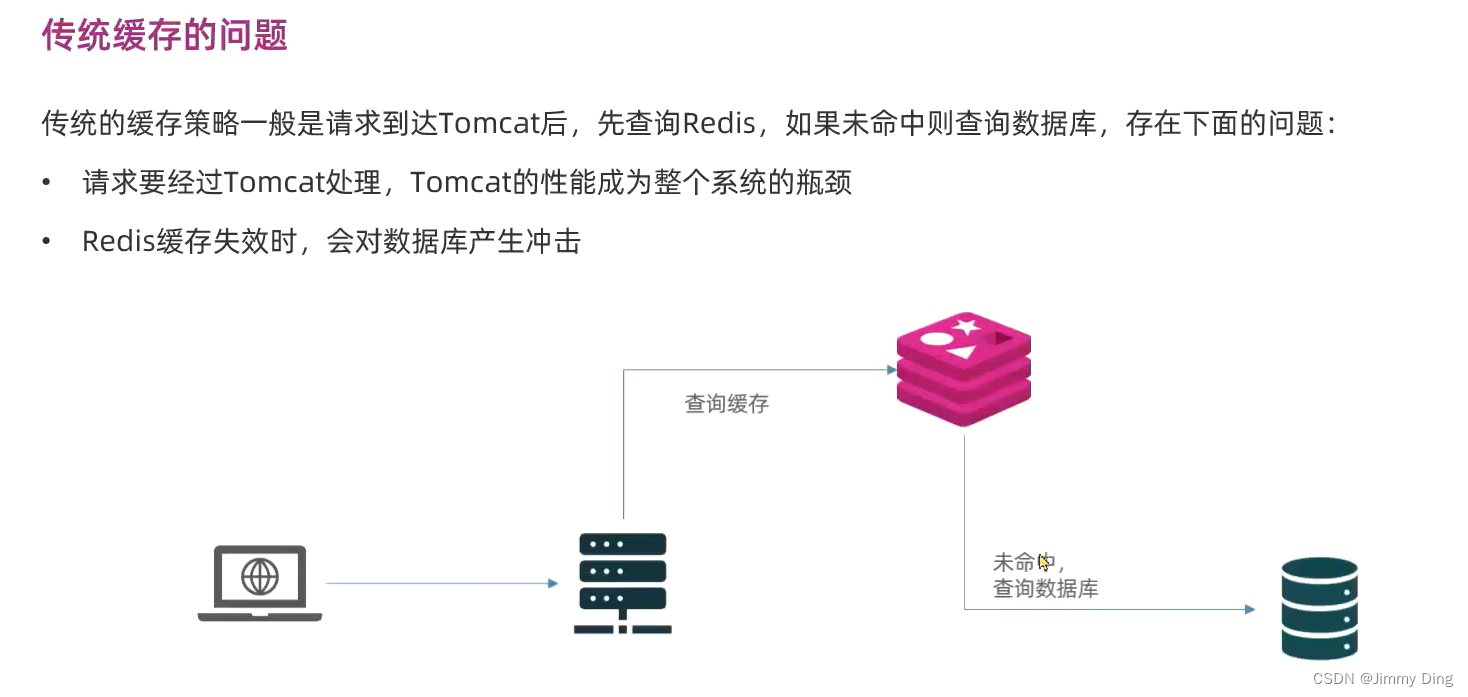
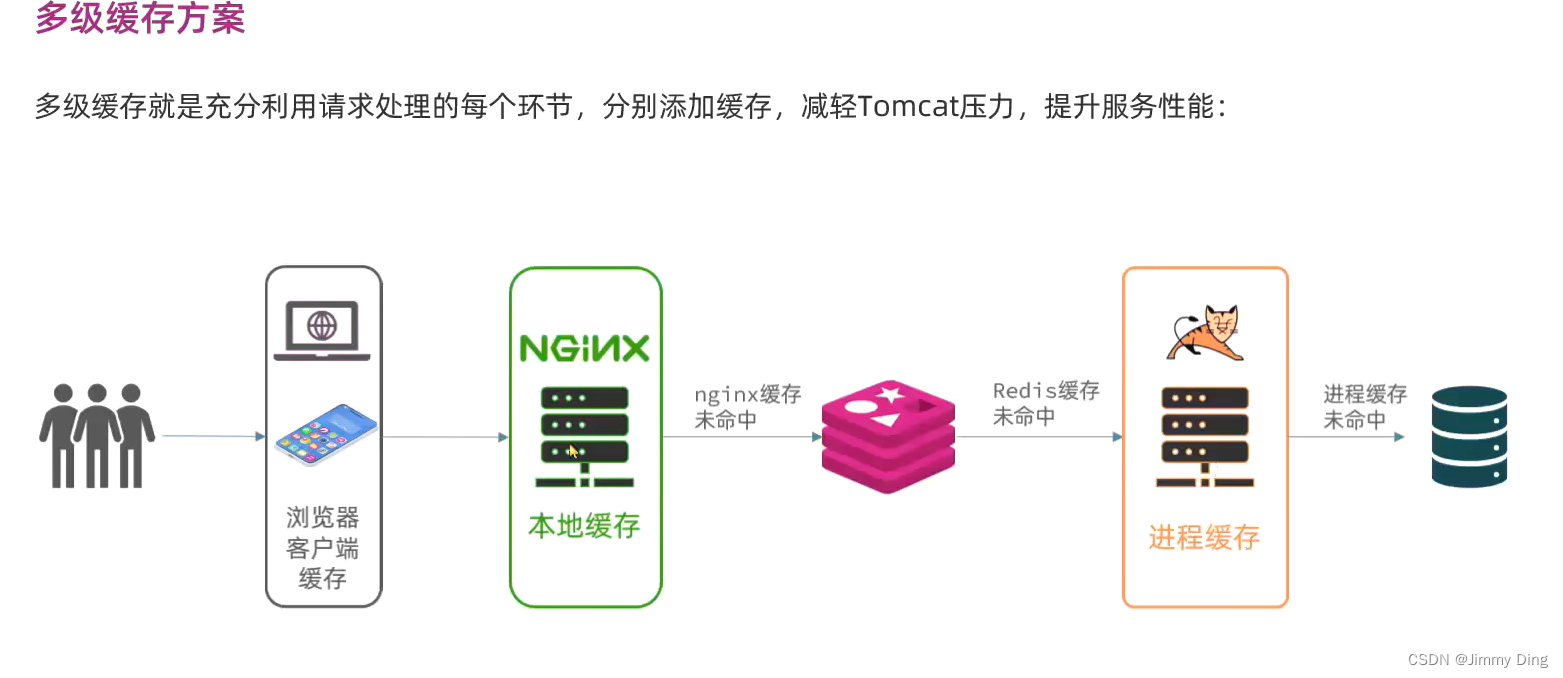
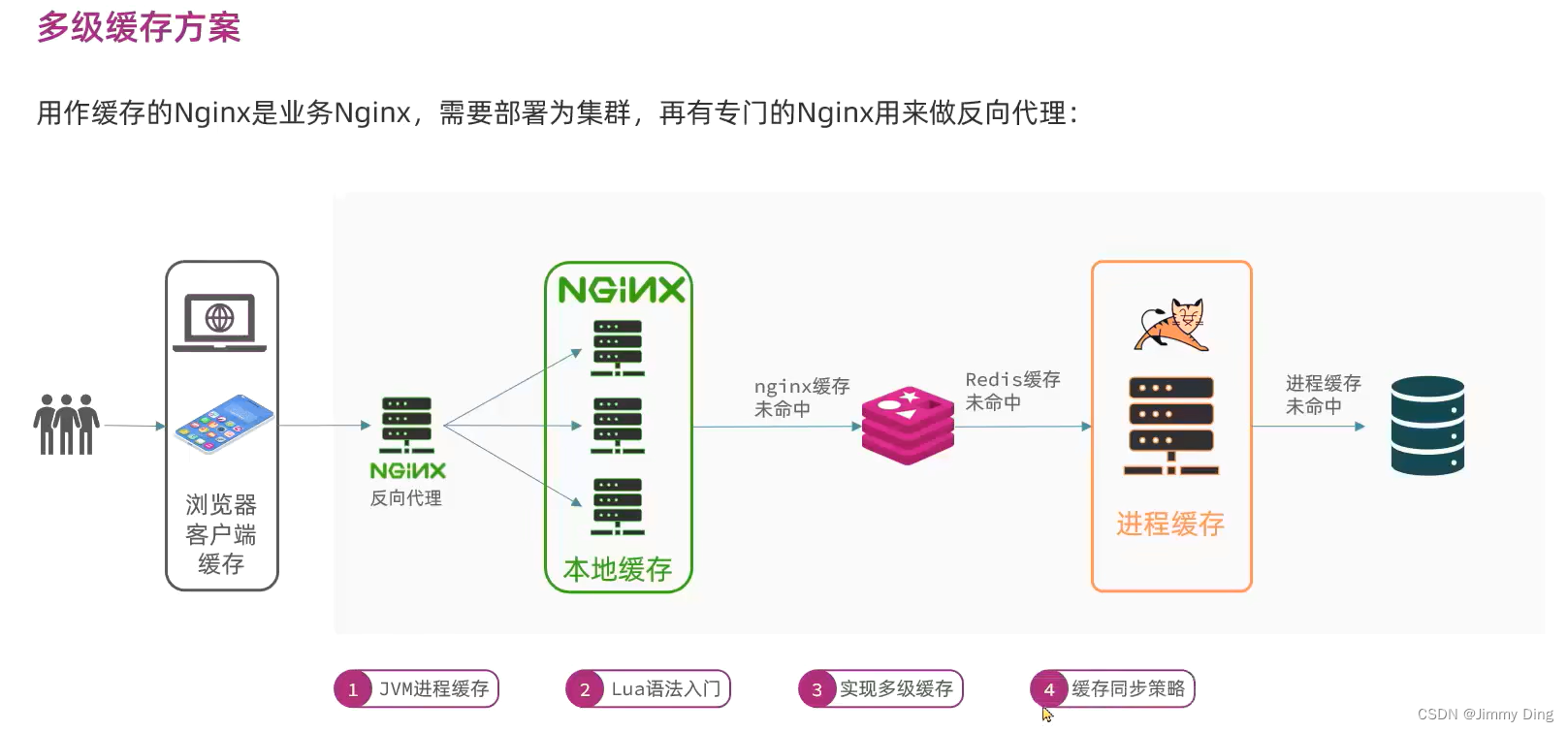
多级缓存引入
JVM进程缓存
导入商品案例
为了方便后期配置MySQL,我们先准备两个目录,用于挂载容器的数据和配置文件目录:
# 进入/tmp目录
cd /tmp
# 创建文件夹
mkdir mysql
# 进入mysql目录
cd mysql
进入mysql目录后,执行下面的Docker命令:
docker run \-p 3306:3306 \--name mysql \-v $PWD/conf:/etc/mysql/conf.d \-v $PWD/logs:/logs \-v $PWD/data:/var/lib/mysql \-e MYSQL_ROOT_PASSWORD=123 \--privileged \-d \mysql:5.7.25
在/tmp/mysql/conf目录添加一个my.cnf文件,作为mysql的配置文件:
# 创建文件
touch /tmp/mysql/conf/my.cnf
文件的内容如下:
[mysqld]
skip-name-resolve
character_set_server=utf8
datadir=/var/lib/mysql
server-id=1000
配置修改后,必须重启容器:
docker restart mysql
接下来,利用Navicat客户端连接MySQL,然后导入课前资料提供的sql文件:
其中包含两张表:
- tb_item:商品表,包含商品的基本信息
- tb_item_stock:商品库存表,包含商品的库存信息
之所以将库存分离出来,是因为库存是更新比较频繁的信息,写操作较多。而其他信息修改的频率非常低。
下面导入课前资料提供的工程:
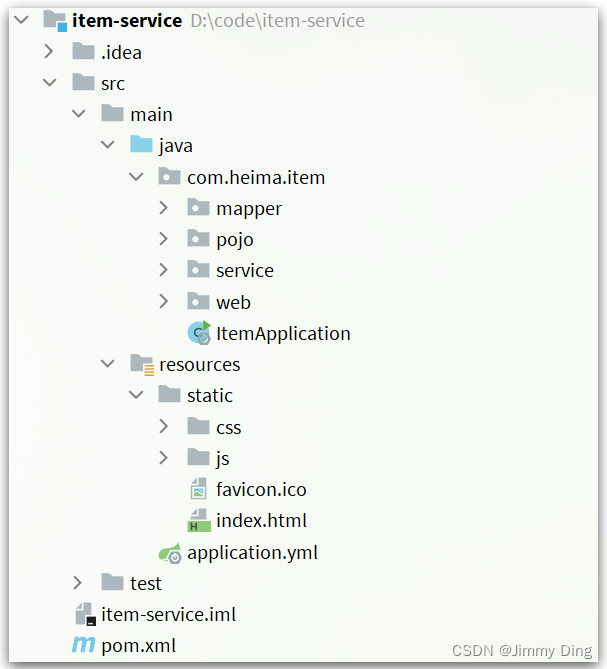
项目结构如图所示:
- 分页查询商品
- 新增商品
- 修改商品
- 修改库存
- 删除商品
- 根据id查询商品
- 根据id查询库存
业务全部使用mybatis-plus来实现。
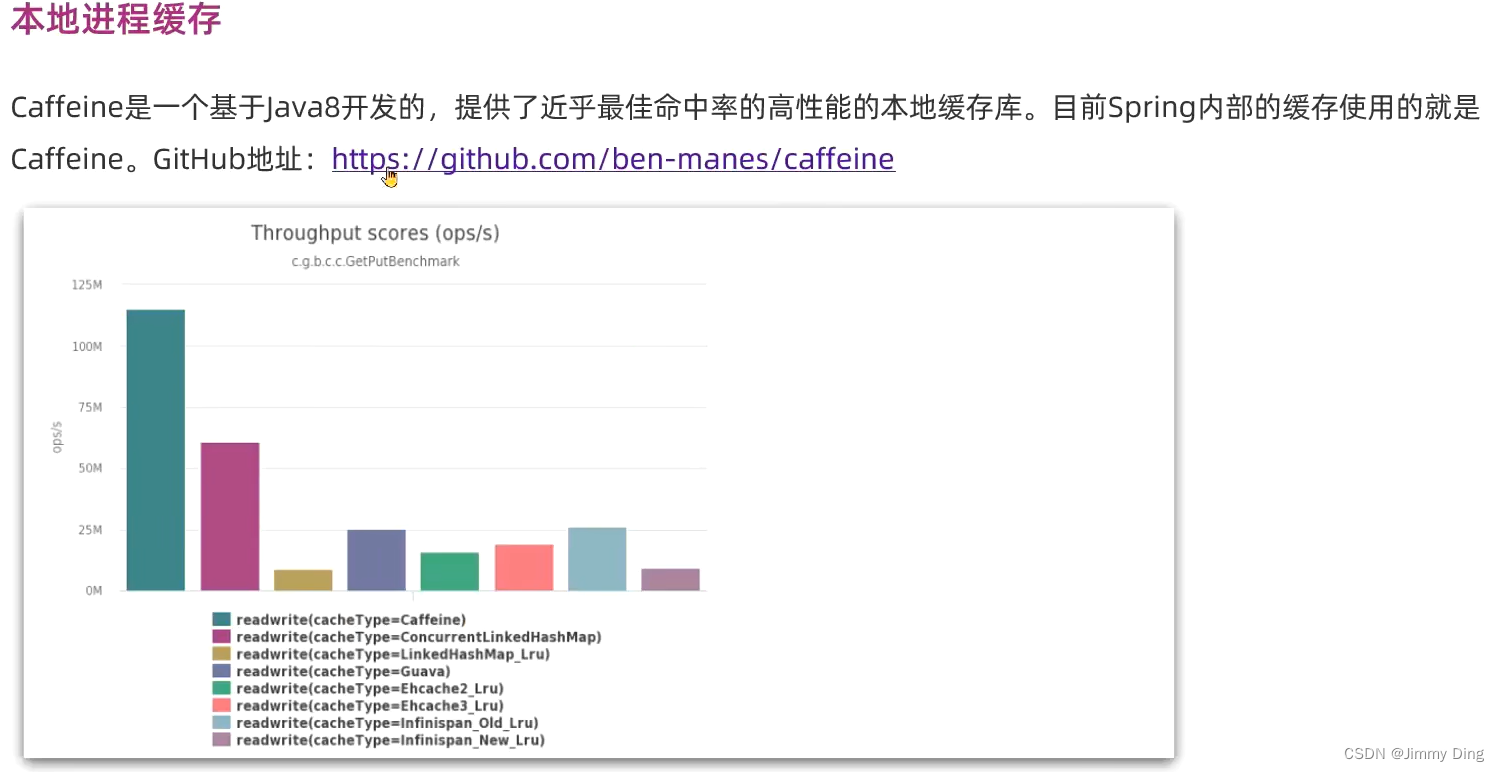
Caffeine学习


实现进程缓存

@Configuration
public class CaffeineConfig {@Beanpublic Cache<Long, Item> itemCache(){return Caffeine.newBuilder().initialCapacity(100).maximumSize(10_000).build();}@Beanpublic Cache<Long, ItemStock> stockCache(){return Caffeine.newBuilder().initialCapacity(100).maximumSize(10_000).build();}
}
@Autowiredprivate Cache<Long,Item> itemCache;@Autowiredprivate Cache<Long,ItemStock> stockCache;@GetMapping("/{id}")public Item findById(@PathVariable("id") Long id){return itemCache.get(id,key -> itemService.query().ne("status", 3).eq("id", key).one());}@GetMapping("/stock/{id}")public ItemStock findStockById(@PathVariable("id") Long id){return stockCache.get(id,key -> stockService.getById(key));}
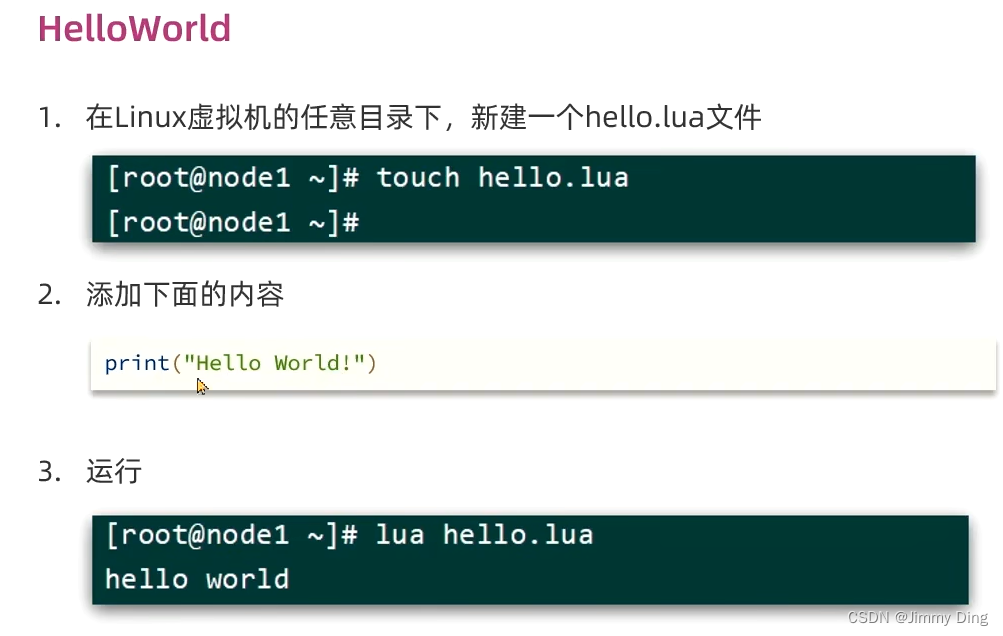
Lua语法入门
认识Lua

变量和循环

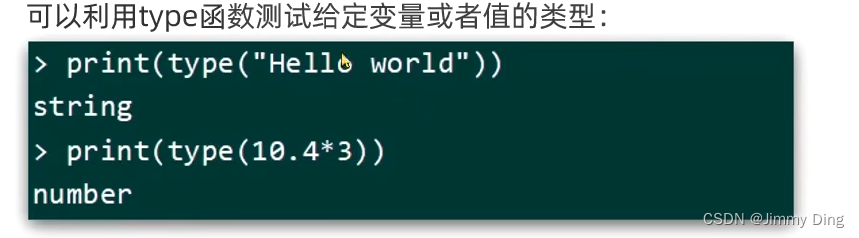
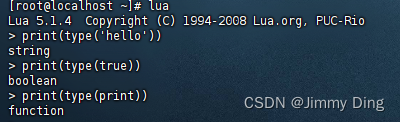

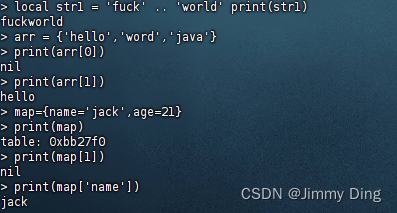

条件控制、函数


多级缓存
安装OpenResty
 首先要安装OpenResty的依赖开发库,执行命令:
首先要安装OpenResty的依赖开发库,执行命令:
yum install -y pcre-devel openssl-devel gcc --skip-broken
你可以在你的 CentOS 系统中添加 openresty 仓库,这样就可以便于未来安装或更新我们的软件包(通过 yum check-update 命令)。运行下面的命令就可以添加我们的仓库:
yum-config-manager --add-repo https://openresty.org/package/centos/openresty.repo
然后就可以像下面这样安装软件包,比如 openresty:
yum install -y openresty
如果提示说命令不存在,则运行:
yum install -y yum-utils
然后再重复上面的命令
opm是OpenResty的一个管理工具,可以帮助我们安装一个第三方的Lua模块。
如果你想安装命令行工具 opm,那么可以像下面这样安装 openresty-opm 包:
yum install -y openresty-opm
默认情况下,OpenResty安装的目录是:/usr/local/openresty
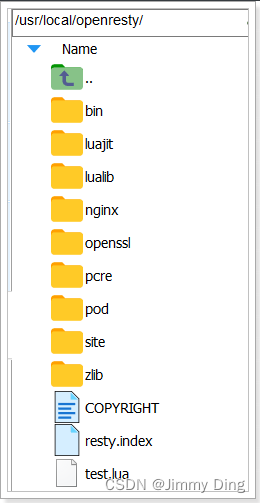
看到里面的nginx目录了吗,OpenResty就是在Nginx基础上集成了一些Lua模块。
打开配置文件:
vi /etc/profile
在最下面加入两行:
export NGINX_HOME=/usr/local/openresty/nginx
export PATH=${NGINX_HOME}/sbin:$PATH
NGINX_HOME:后面是OpenResty安装目录下的nginx的目录
然后让配置生效:
source /etc/profile
OpenResty底层是基于Nginx的,查看OpenResty目录的nginx目录,结构与windows中安装的nginx基本一致:
所以运行方式与nginx基本一致:
# 启动nginx
nginx
# 重新加载配置
nginx -s reload
# 停止
nginx -s stop
nginx的默认配置文件注释太多,影响后续我们的编辑,这里将nginx.conf中的注释部分删除,保留有效部分。
修改/usr/local/openresty/nginx/conf/nginx.conf文件,内容如下:
#user nobody;
worker_processes 1;
error_log logs/error.log;events {worker_connections 1024;
}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;server {listen 8081;server_name localhost;location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}
}
在Linux的控制台输入命令以启动nginx:
nginx
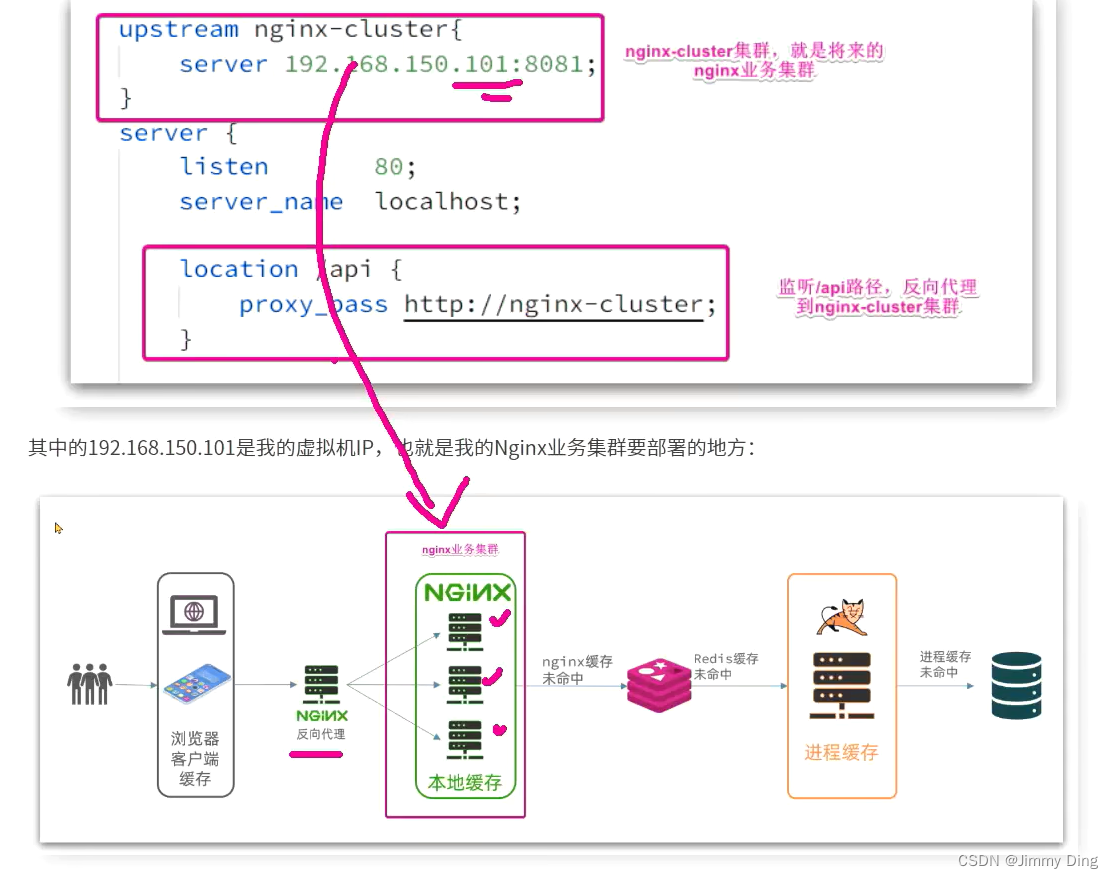
然后访问页面:http://192.168.150.101:8081,注意ip地址替换为你自己的虚拟机IP:
OpenResty入门


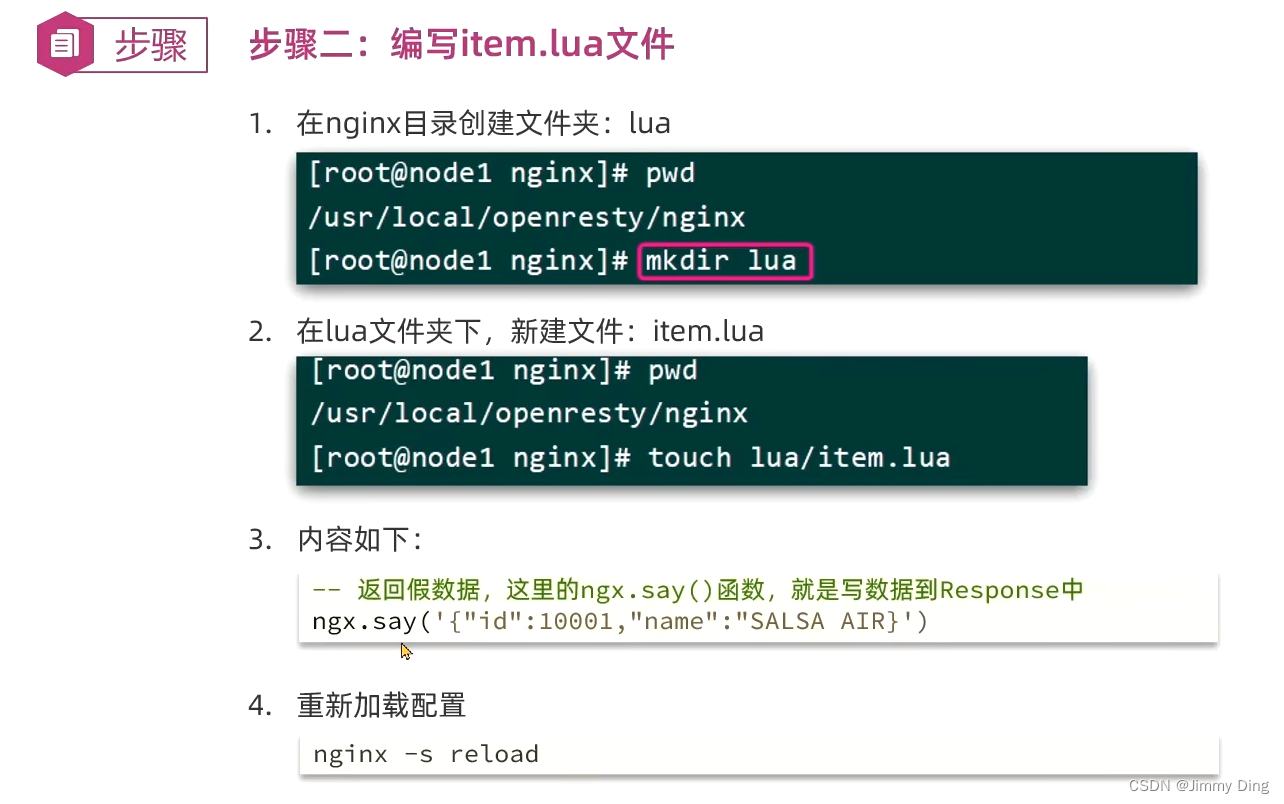
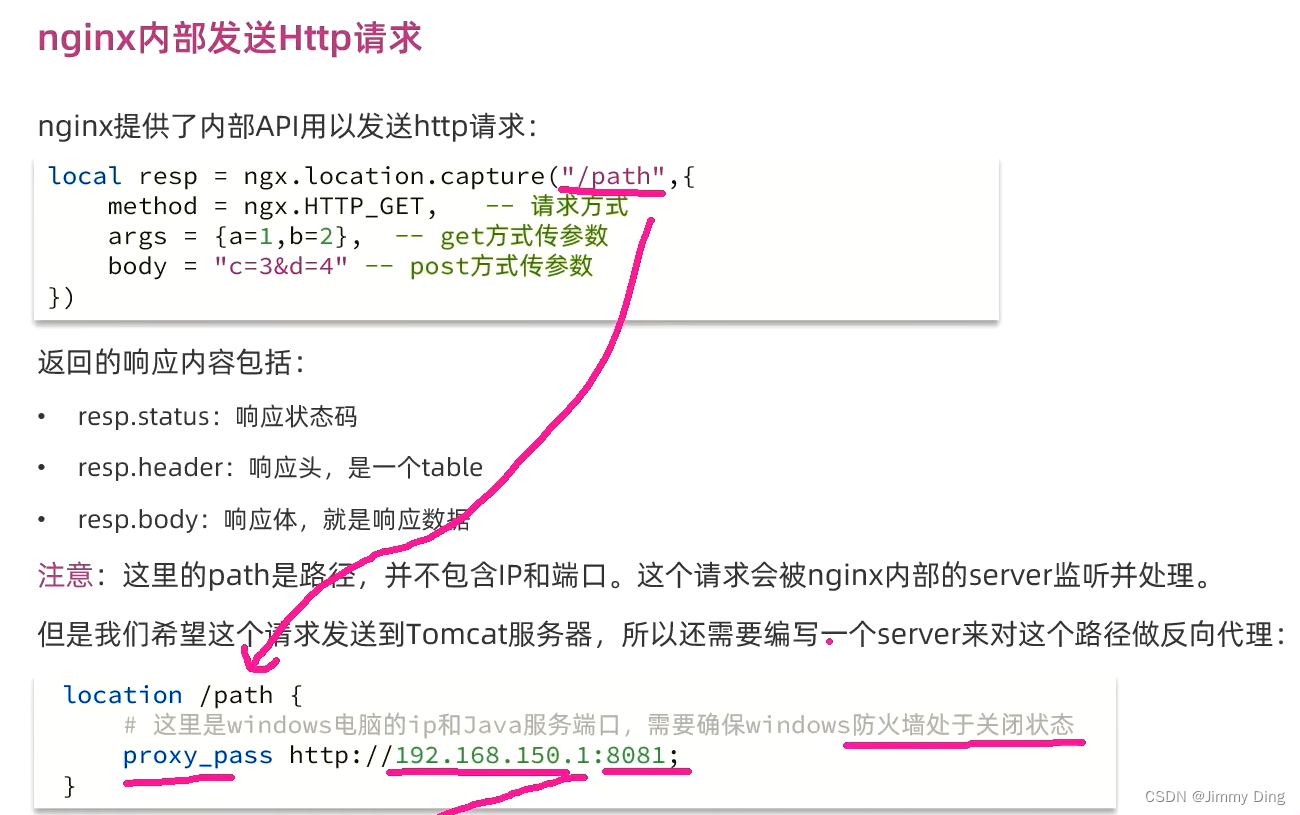
请求参数处理

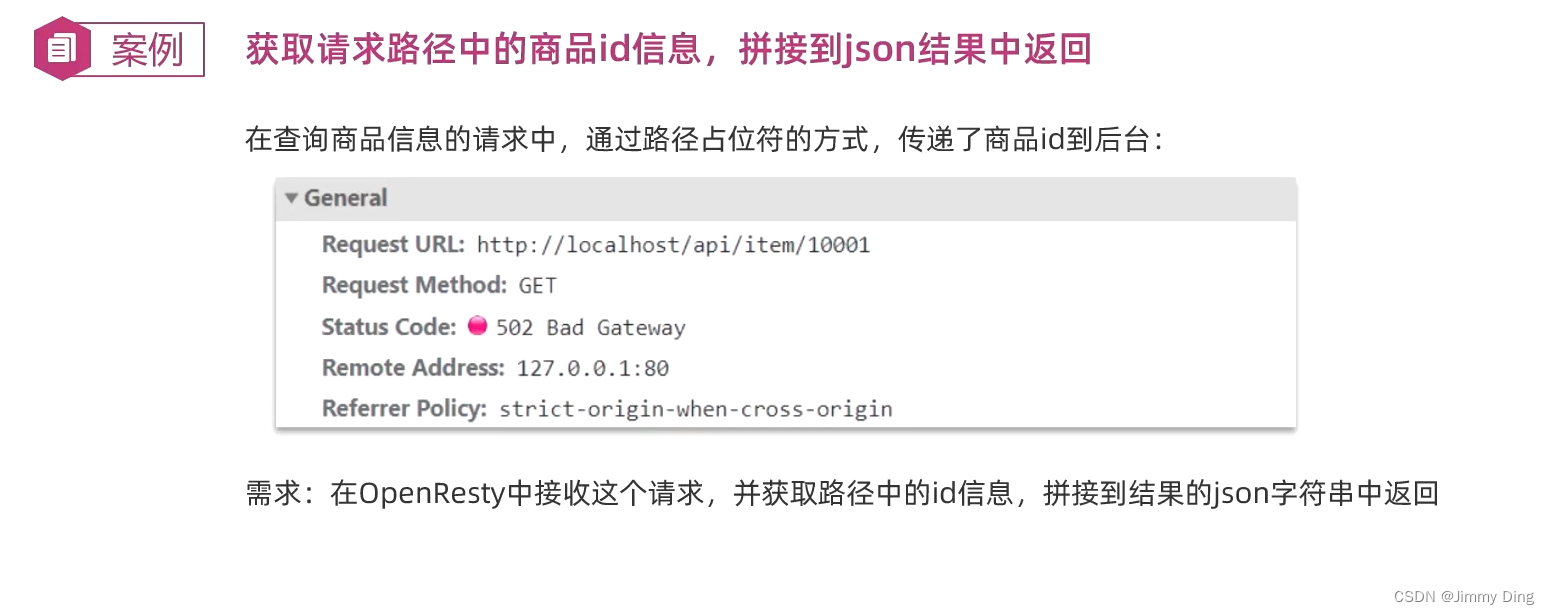
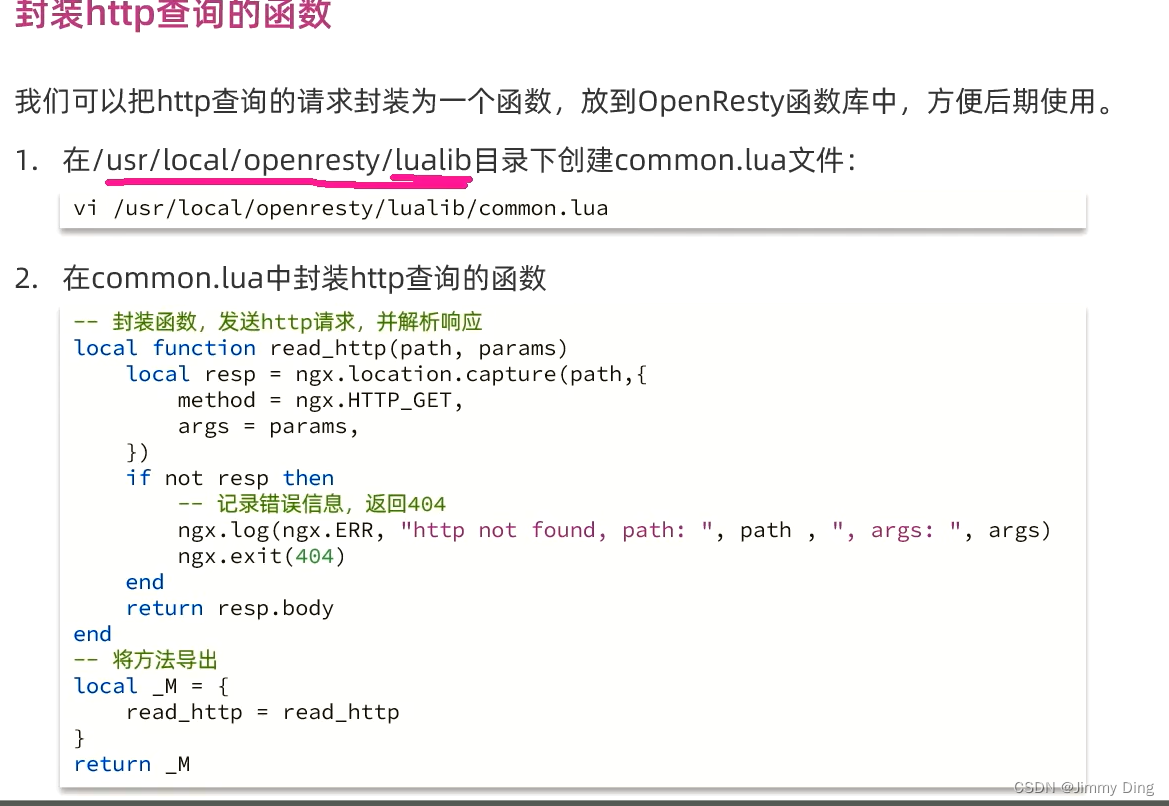
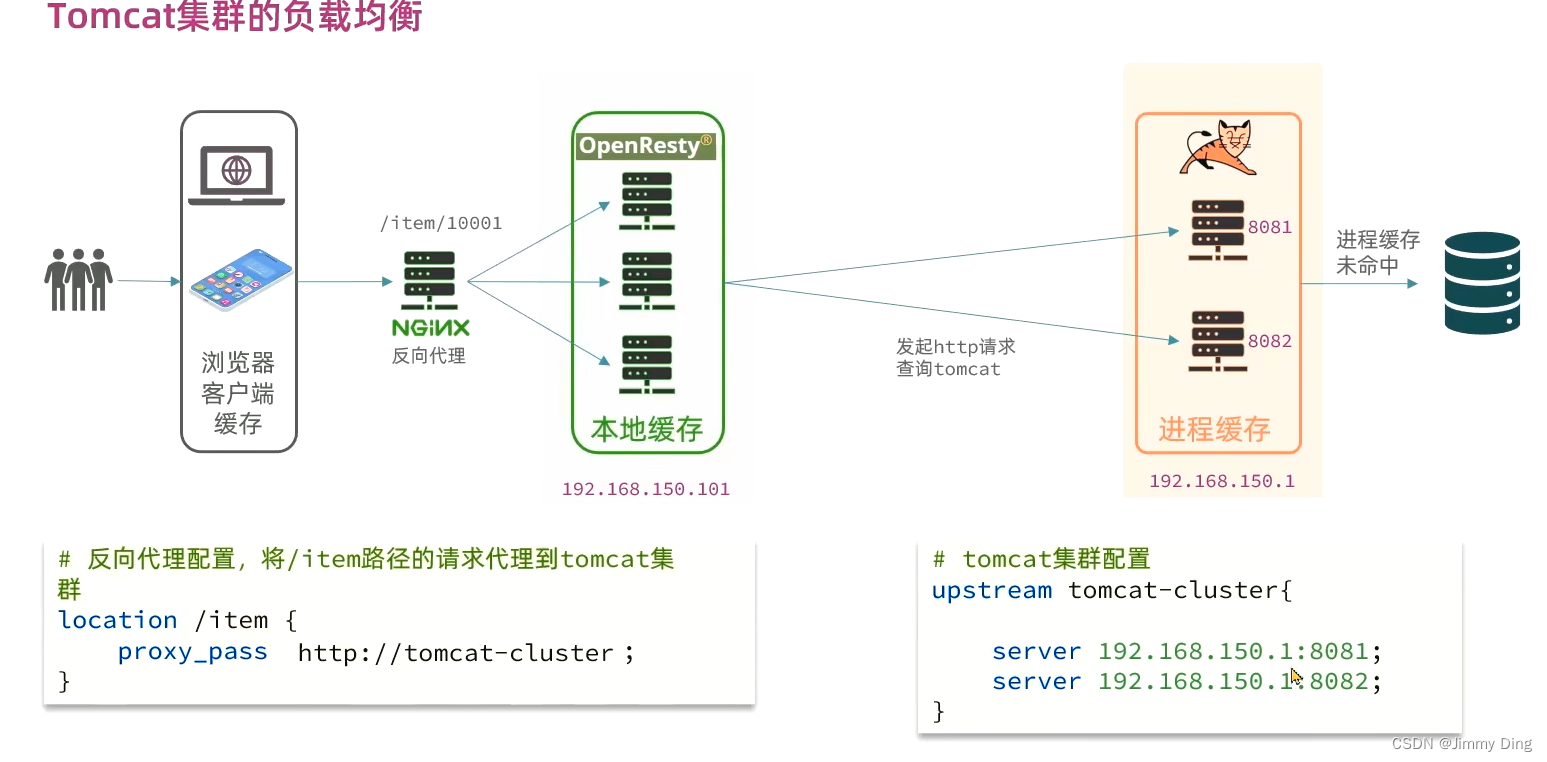
查询Tomcat
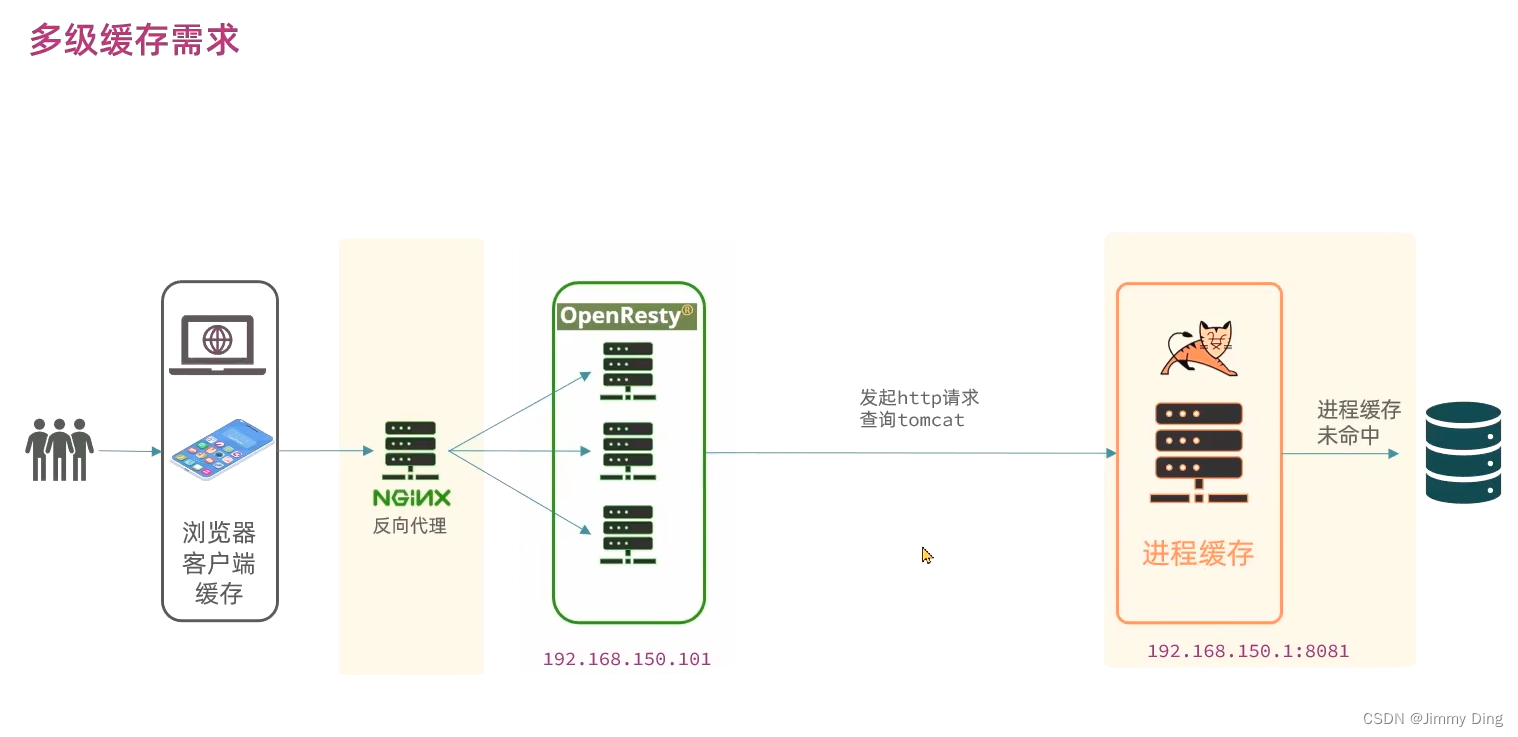


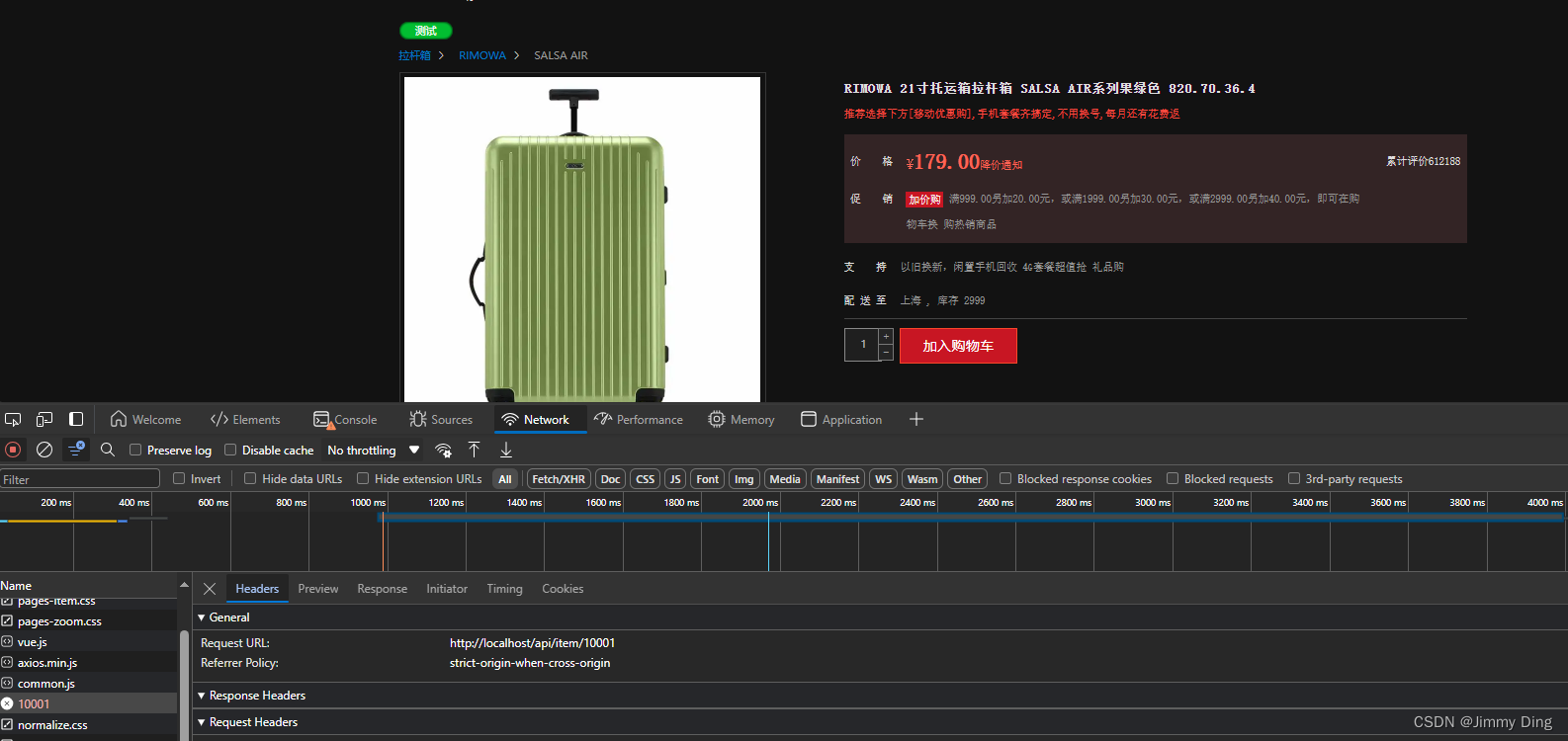
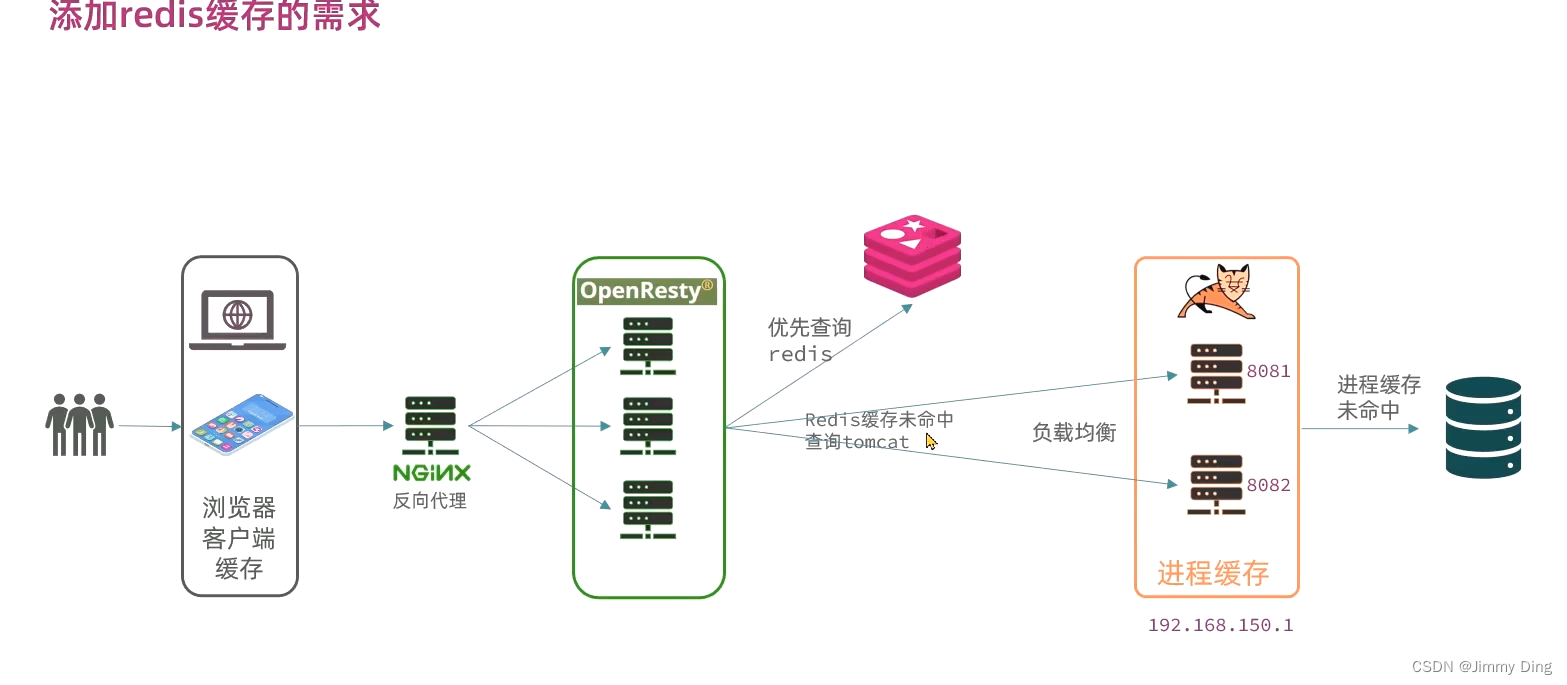
Redis缓存预热

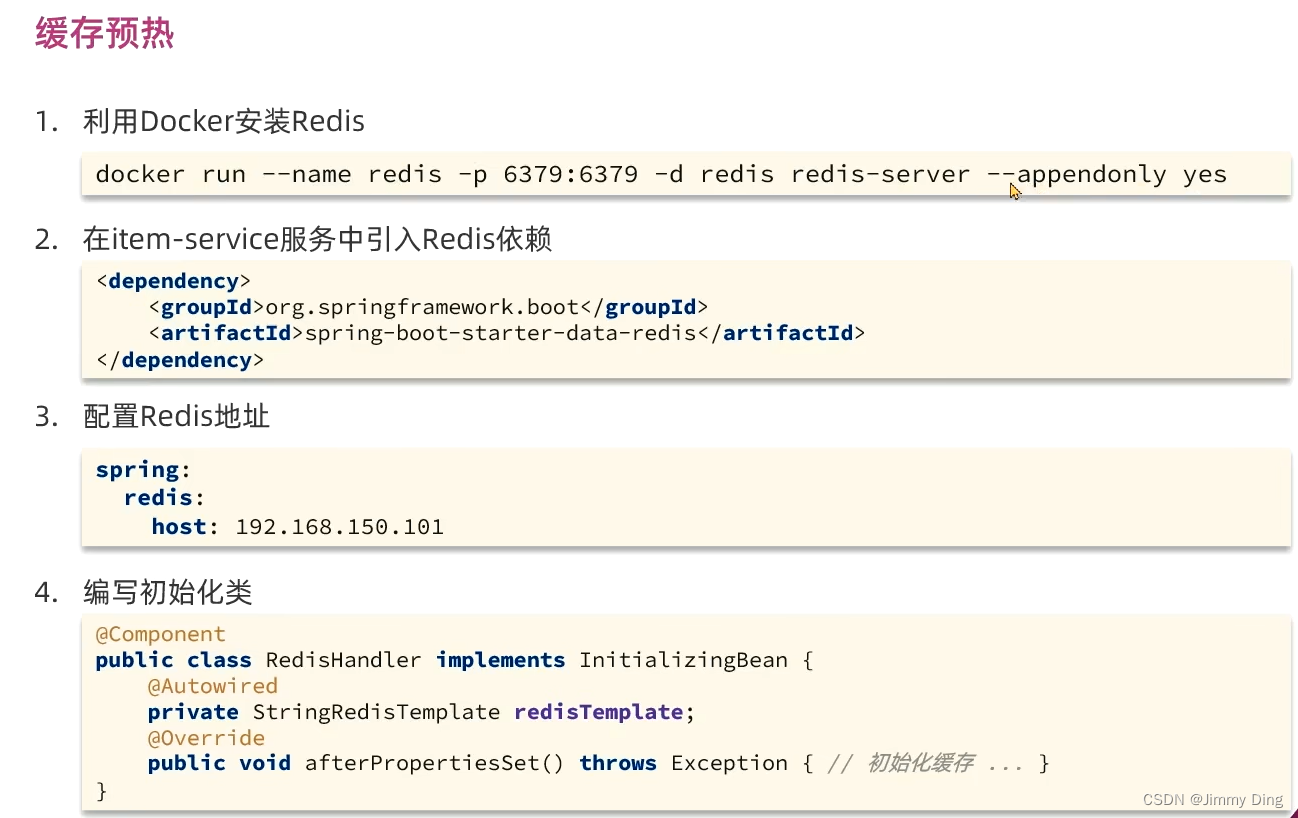
@Component
public class RedisHandler implements InitializingBean {@Autowiredprivate StringRedisTemplate redisTemplate;@Autowiredprivate IItemService itemService;@Autowiredprivate IItemStockService stockService;private static final ObjectMapper MAPPER = new ObjectMapper();@Overridepublic void afterPropertiesSet() throws Exception {//初始化缓存//1.查询商品信息List<Item> itemList = itemService.list();//2.放入缓存for (Item item : itemList) {//2.1 item序列化为JSONString json = MAPPER.writeValueAsString(item);//2.2存入redisredisTemplate.opsForValue().set("item:id:" + item.getId(), json);}//3.查询商品库存信息List<ItemStock> stockList = stockService.list();//4.放入缓存for (ItemStock stock : stockList) {//2.1 item序列化为JSONString json = MAPPER.writeValueAsString(stock);//2.2存入redisredisTemplate.opsForValue().set("item:stock:id:" + stock.getId(), json);}}
}
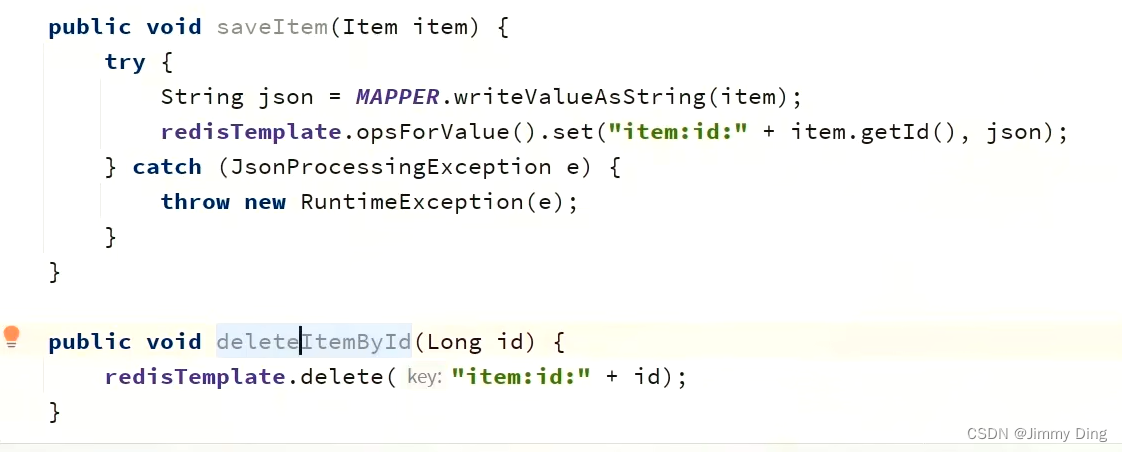
查询Redis缓存



Nginx本地缓存



缓存同步策略
策略

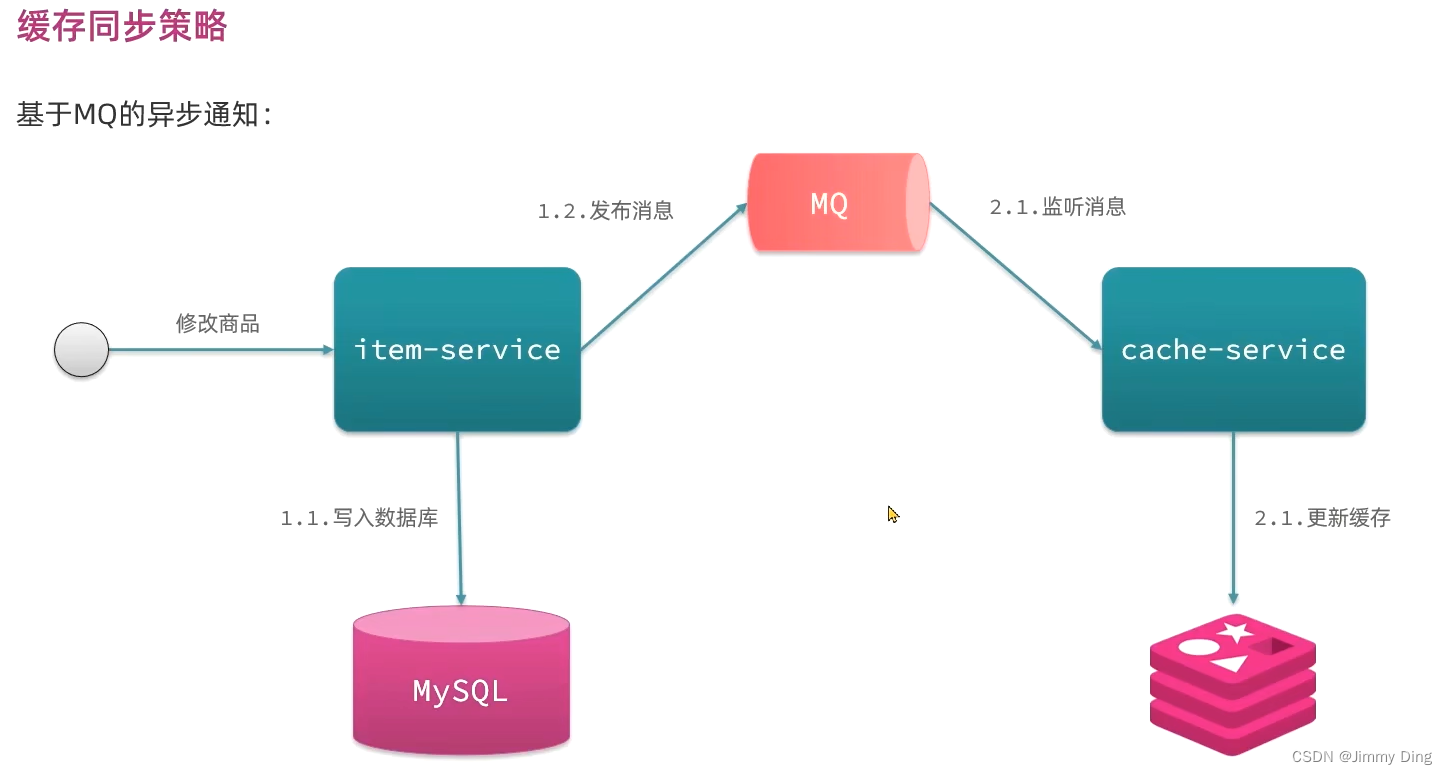
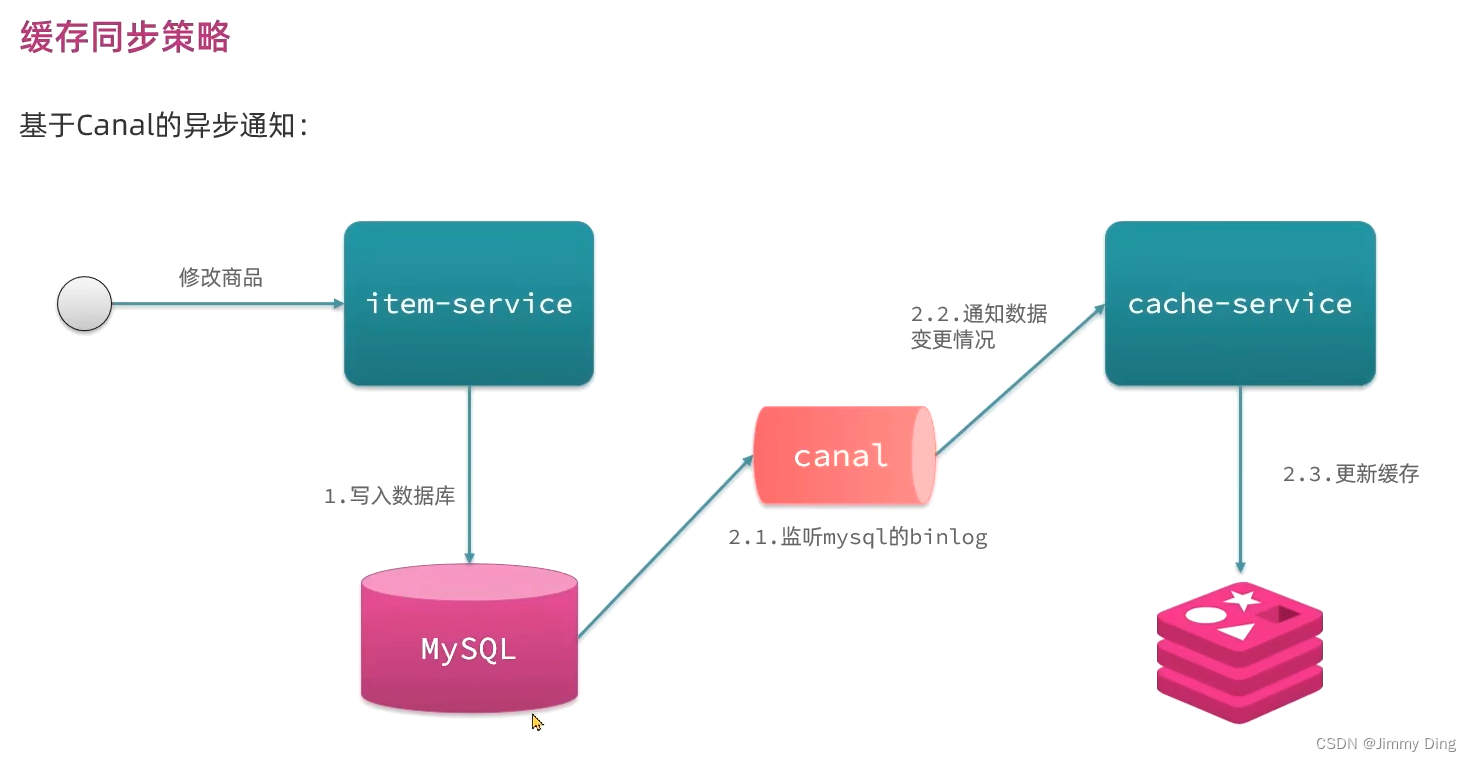
安装Canal
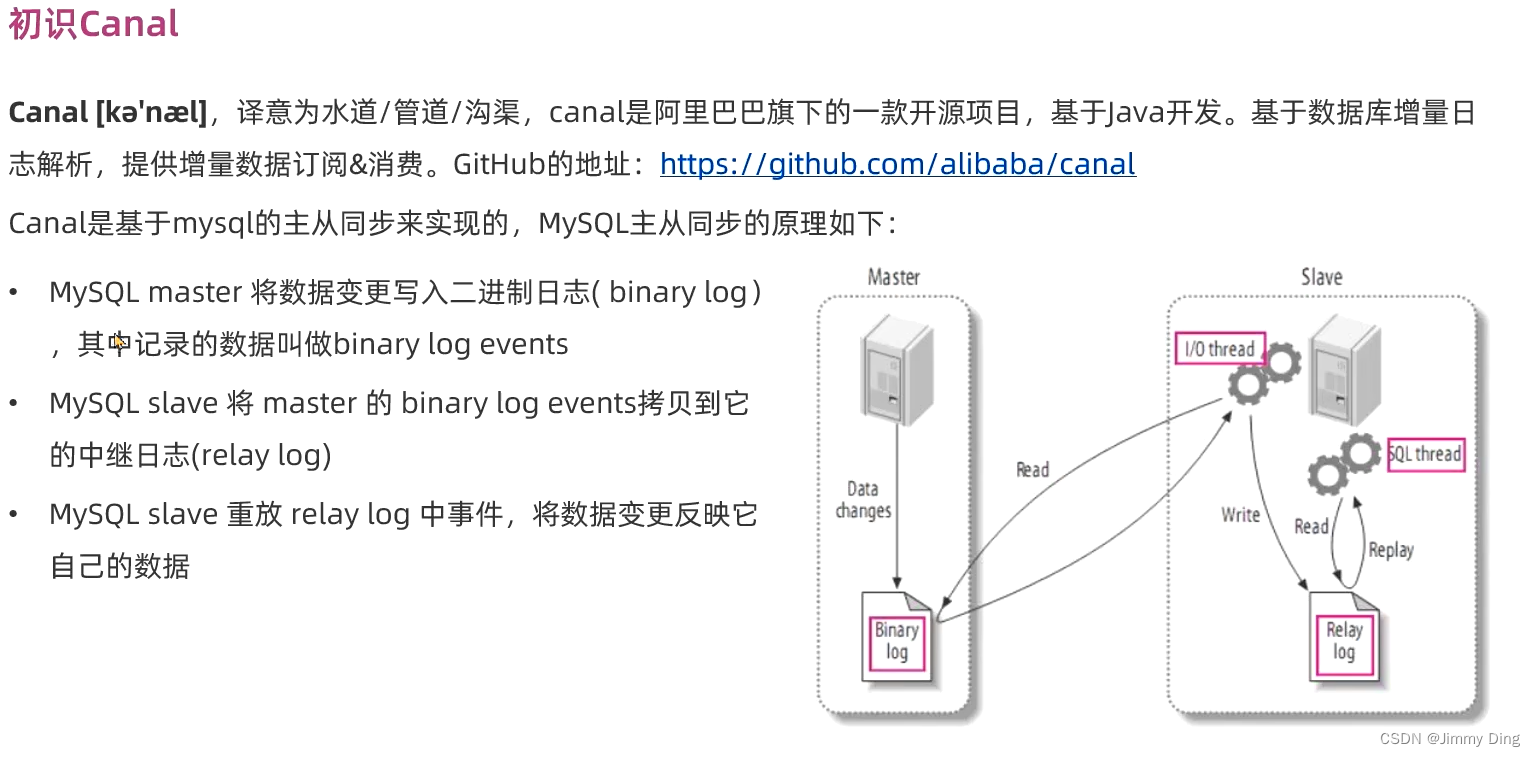
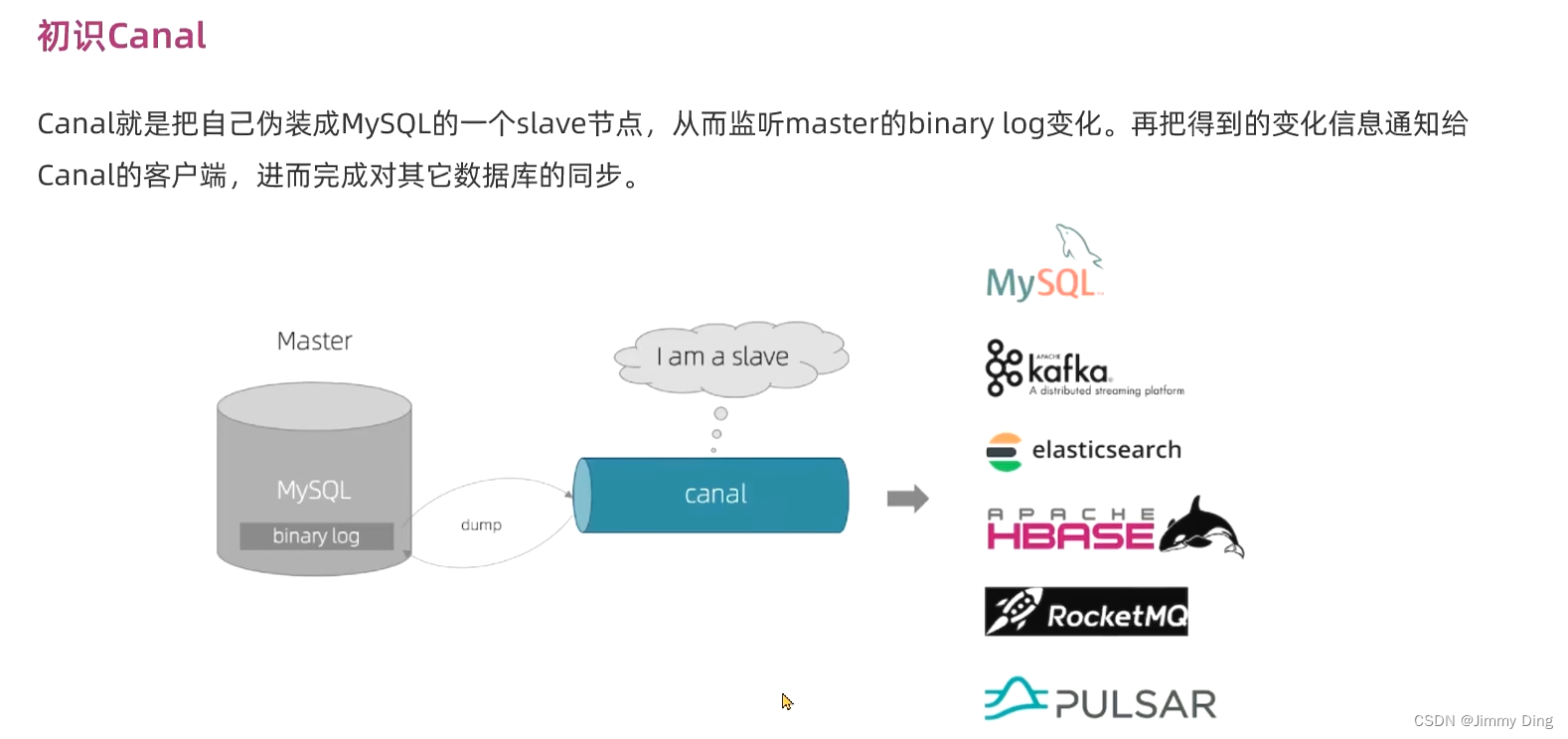
Canal是基于MySQL的主从同步功能,因此必须先开启MySQL的主从功能才可以。
这里以之前用Docker运行的mysql为例:
打开mysql容器挂载的日志文件,我的在/tmp/mysql/conf目录:
修改文件:
vi /tmp/mysql/conf/my.cnf
添加内容:
log-bin=/var/lib/mysql/mysql-bin
binlog-do-db=heima
配置解读:
log-bin=/var/lib/mysql/mysql-bin:设置binary log文件的存放地址和文件名,叫做mysql-binbinlog-do-db=heima:指定对哪个database记录binary log events,这里记录heima这个库
最终效果:
[mysqld]
skip-name-resolve
character_set_server=utf8
datadir=/var/lib/mysql
server-id=1000
log-bin=/var/lib/mysql/mysql-bin
binlog-do-db=heima
接下来添加一个仅用于数据同步的账户,出于安全考虑,这里仅提供对heima这个库的操作权限。
create user canal@'%' IDENTIFIED by 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT,SUPER ON *.* TO 'canal'@'%' identified by 'canal';
FLUSH PRIVILEGES;
重启mysql容器即可
docker restart mysql
测试设置是否成功:在mysql控制台,或者Navicat中,输入命令:
show master status;

我们需要创建一个网络,将MySQL、Canal、MQ放到同一个Docker网络中:
docker network create heima
让mysql加入这个网络:
docker network connect heima mysql
课前资料中提供了canal的镜像压缩包:
大家可以上传到虚拟机,然后通过命令导入:
docker load -i canal.tar
然后运行命令创建Canal容器:
docker run -p 11111:11111 --name canal \
-e canal.destinations=heima \
-e canal.instance.master.address=mysql:3306 \
-e canal.instance.dbUsername=canal \
-e canal.instance.dbPassword=canal \
-e canal.instance.connectionCharset=UTF-8 \
-e canal.instance.tsdb.enable=true \
-e canal.instance.gtidon=false \
-e canal.instance.filter.regex=heima\\..* \
--network heima \
-d canal/canal-server:v1.1.5
说明:
-p 11111:11111:这是canal的默认监听端口-e canal.instance.master.address=mysql:3306:数据库地址和端口,如果不知道mysql容器地址,可以通过docker inspect 容器id来查看-e canal.instance.dbUsername=canal:数据库用户名-e canal.instance.dbPassword=canal:数据库密码-e canal.instance.filter.regex=:要监听的表名称
表名称监听支持的语法:
mysql 数据解析关注的表,Perl正则表达式.
多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
常见例子:
1. 所有表:.* or .*\\..*
2. canal schema下所有表: canal\\..*
3. canal下的以canal打头的表:canal\\.canal.*
4. canal schema下的一张表:canal.test1
5. 多个规则组合使用然后以逗号隔开:canal\\..*,mysql.test1,mysql.test2
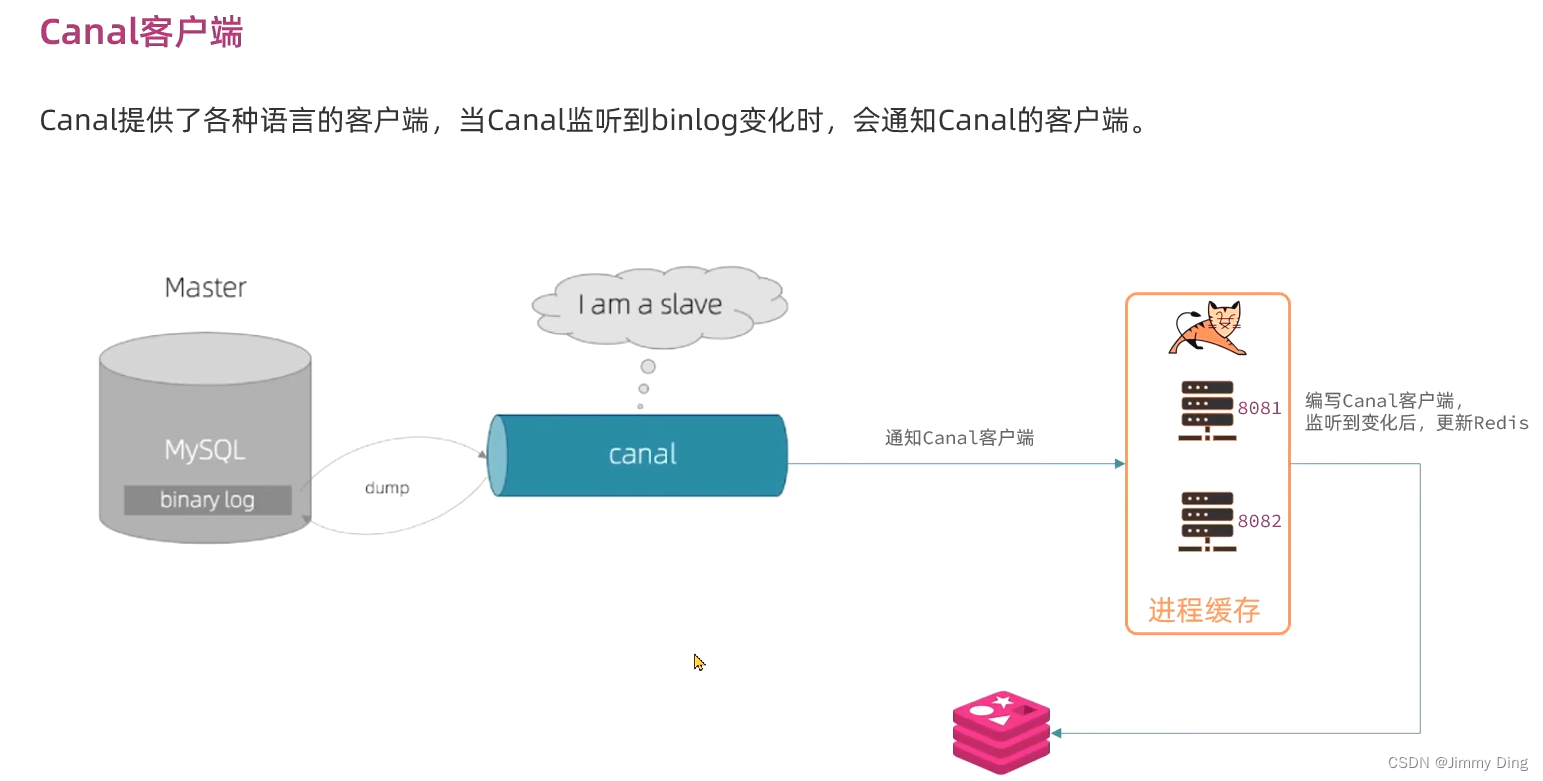
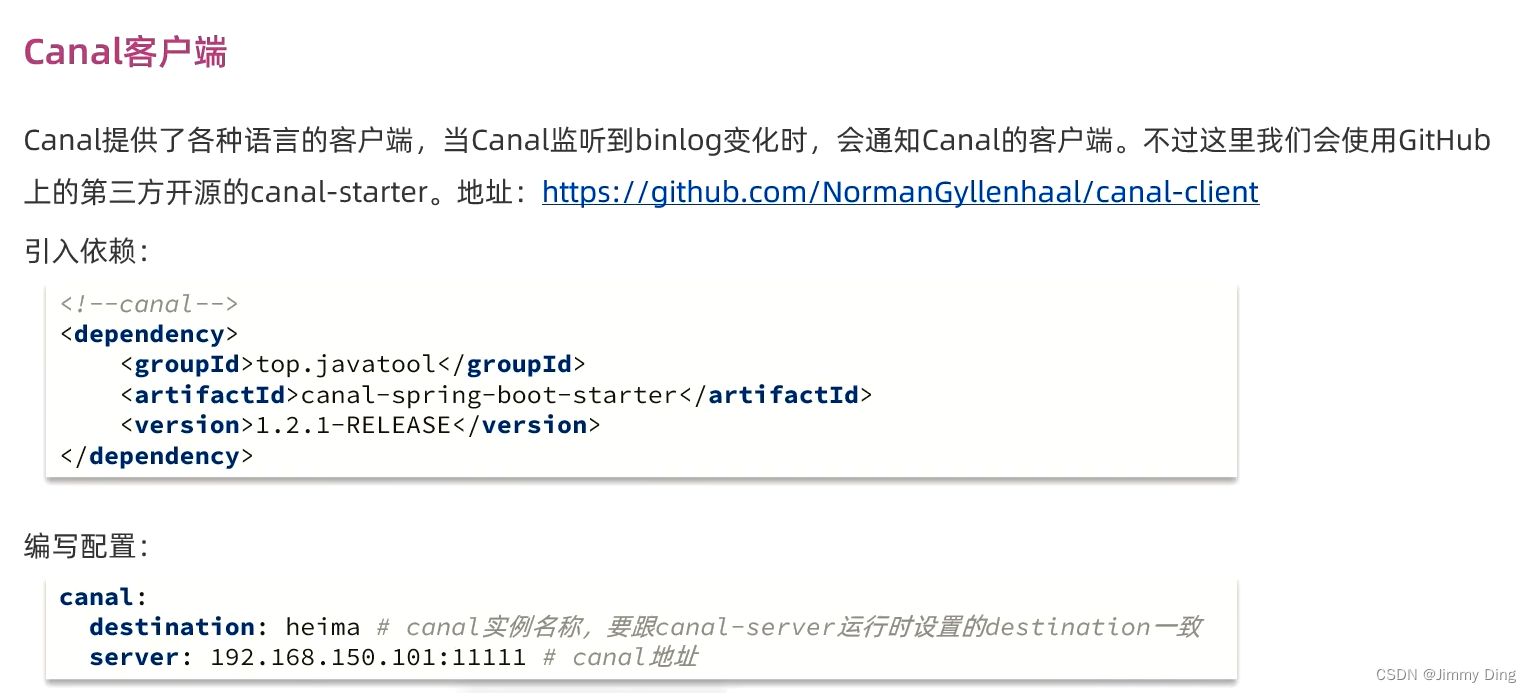
监听Canal



这篇关于微服务学习Day11-缓存问题学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






