本文主要是介绍「布道师系列文章」众安保险王凯解析 Kafka 网络通信,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者|众安保险基础平台 Java 开发专家王凯
引言
今天给大家带来的是 Kafka 网路通信主要流程的解析(基于 Apache Kafka 3.7[2])。同时引申分析了业界当前较火的AutoMQ基于Kafka在网络通信层面的优化和提升。
01
如何构建一个基本的请求和处理响应
一个消息队列涉及的网络通信主要有两块:
消息生产者与消息队列服务器之间(Kafka 中是生产者向队列「推」消息)
消息消费者与消息队列服务器之间(Kafka 中是消费者向队列「拉」消息)

图上就是一个从发送消息到收到响应主要经过的流程。Client:1.KafkaProducer 初始化 Sender 线程2.Sender 线程从 RecordAccumulator 中获取攒批好的数据(这里详细的客户端发送可以看 https://mp.weixin.qq.com/s/J2\_O1l81duknfdFvHuBWxw)3.Sender 线程调用 NetworkClient 检查连接(未 ready 需要 initiateConnect)4.Sender 线程调用 NetworkClient 的 doSend 方法将数据写入 KafkaChannel5.Sender 线程调用 NetworkClient 的 poll 进行实际的发送Server:1.KafkaServer 初始化 SocketServer、dataPlaneRequestProcessor(KafkaApis)、dataPlaneRequestHandlerPool2.SocketServer 初始化 RequestChannel、dataPlaneAcceptor3.dataPlaneAcceptor 负责获取连接并分配处理任务给对应的 Processor4.Processor 线程从 newConnections 的 queue 中取出任务进行处理5.Processor 线程处理准备好的 IO 事件
configureNewConnections() :创建新连接
processNewResponses():发送 Response,并将 Response 放入到 inflightResponses 临时队列
poll():执行 NIO poll,获取对应 SocketChannel 上准备就绪的 I/O 操作
processCompletedReceives():将接收到的 Request 放入 RequestChannel 队列
processCompletedSends():为临时 Response 队列中的 Response 执行回调逻辑
processDisconnected():处理因发送失败而导致的连接断开
closeExcessConnections():关闭超过配额限制部分的连接
6.KafkaRequestHandler 从 RequestChannel 中获取准备好的事件根据 apiKey 分配给对应的 KafkaApi 进行处理7.KafkaApi 处理完成后,把 response 放入 RequestChannel8.Processor 线程将 response 响应给 client以上就是一个完整的 kafka 发送消息,客户端和服务端的处理流程。
02
Kafka 中的网络通信
1. 服务端通信线程模型
不同于 rocketmq 中通过 netty 实现了高效的网络通信,Kafka 中的相当于通过 java NIO 实现了一个主从 Reactor 模式的网路通信(不熟悉的可以关注 https://jenkov.com/tutorials/java-nio/overview.html)。
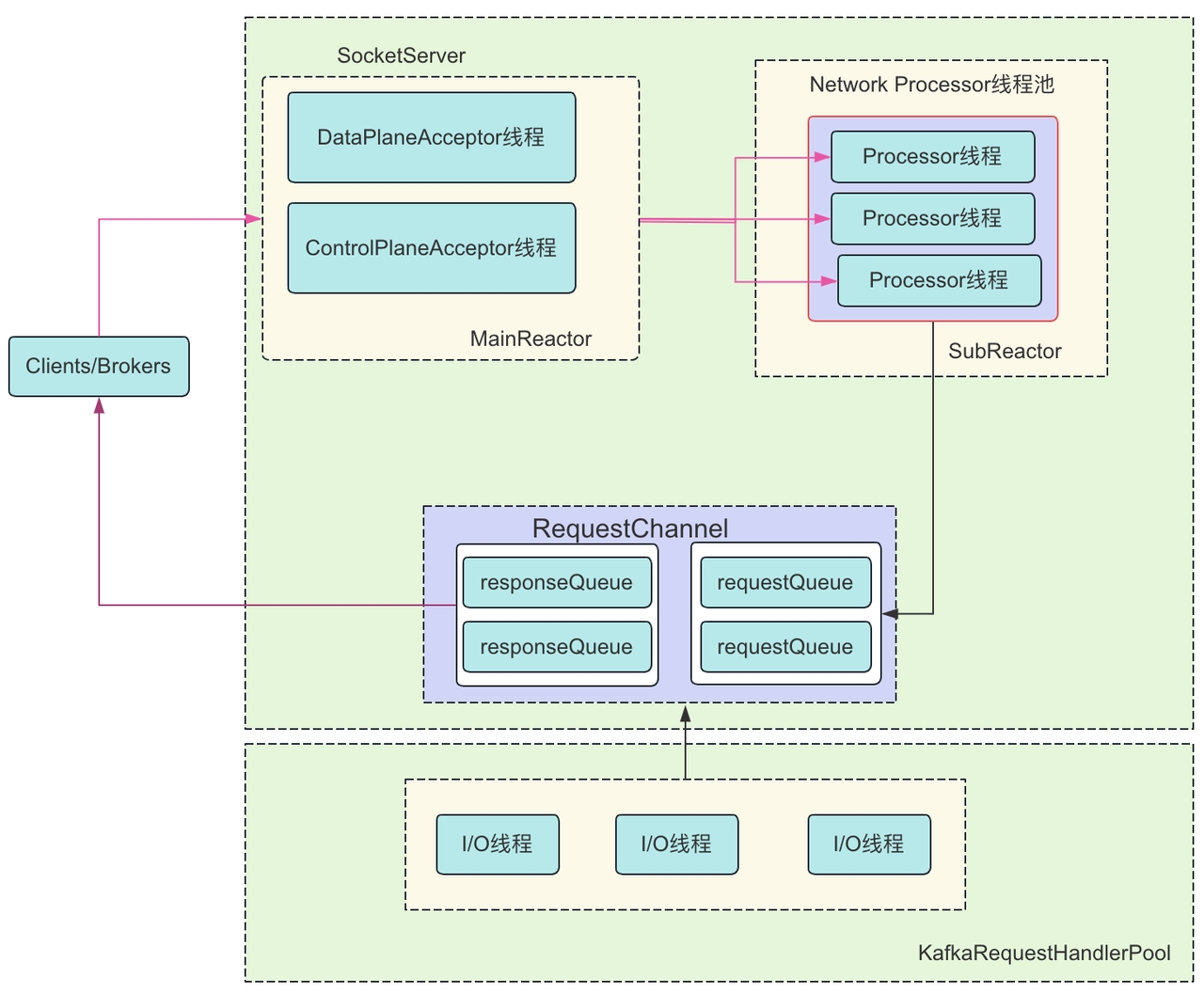
DataPlanAcceptor 和 ControlPlanAcceptor 都是 Acceptor 的一个子类,Acceptor 又是一个实现了 Runnable 接口的线程类,Acceptor 的主要目的是监听并且接收 Client 和 Broker 之间的请求,同时建立传输通道(SocketChannel),通过轮询的方式交给一个 Processor 处理。这里还有一个 RequestChannel(ArrayBlockingQueue),用于建立 Processor 和 Handler 的连接,MainReactor(Acceptor)只负责监听 OP_ACCEPT 事件, 监听到之后把 SocketChannel 传递给 SubReactor(Processor), 每个 Processor 都有自己的 Selector,SubReactor 会监听并处理其他的事件,并最终把具体的请求传递给 KafkaRequestHandlerPool。
2. 线程模型中主要组件的初始化
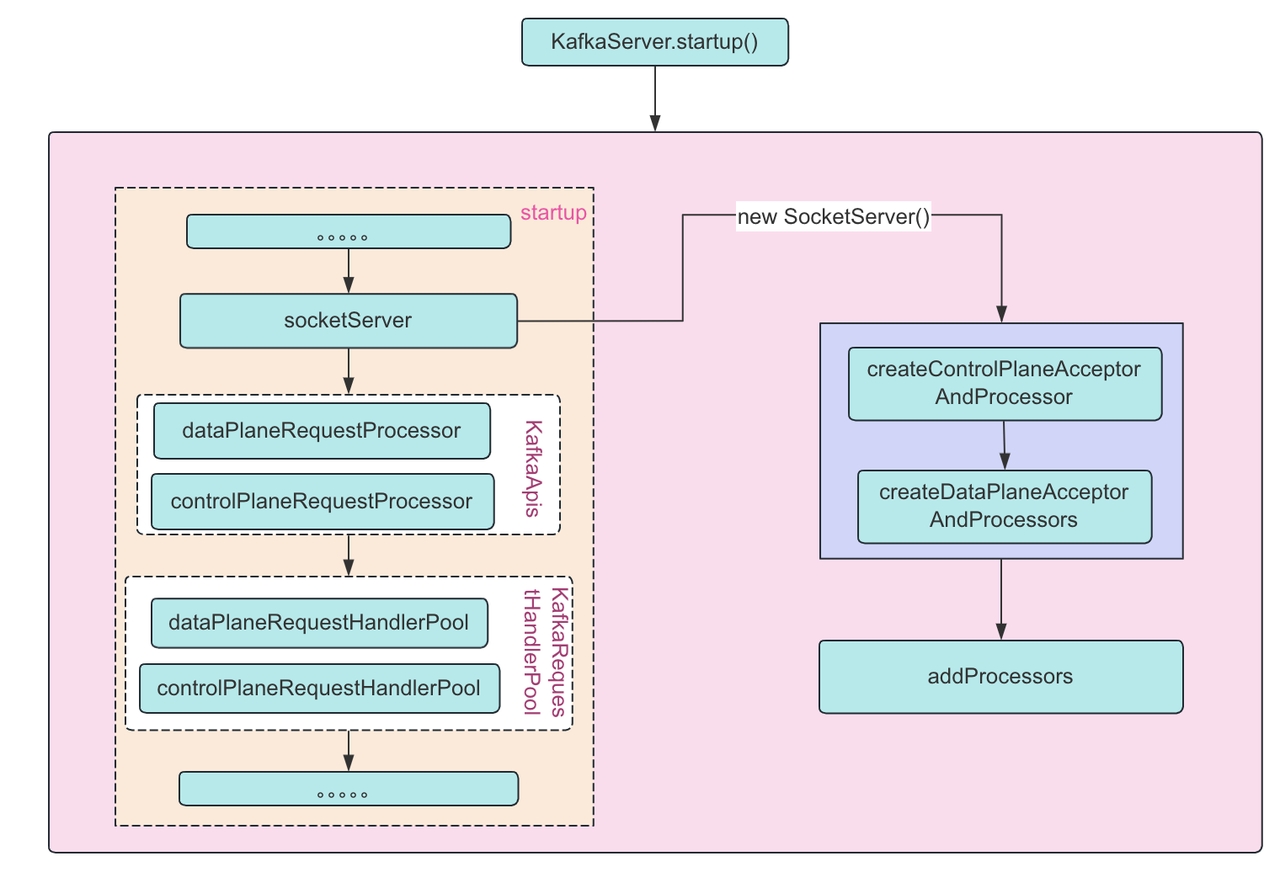
从图上可以看出在 broker 启动时会调用 KafkaServer 的 startup 方法(这里我们默认还是基于 zookeeper 的模式)。startup 方法中主要创建:1.KafkaApis 的处理类:dataPlaneRequestProcessor 和 controlPlaneRequestProcessor 的创建2.KafkaRequestHandlePool:dataPlaneRequestHandlerPool 和 controlPlaneRequestHandlerPool 创建3.socketServer 的初始化4.controlPlaneAcceptorAndProcessor 和 dataPlaneAcceptorAndProcessor 的创建其实这里还有一步图上没有但是也在 startup 方法中非常重要的方法,线程启动:enableRequestProcessing 是通过初始化完成的 socketServer 进行。
3. Processor 的添加和销毁
1.添加
broker 启动时添加
主动调整 num.network.threads 处理线程数量
2.启动
broker 启动 accetor 时启动 processor
主动调整时启动未启动的新的处理线程
3.移除队列并销毁
broker 关闭
主动调整 num.network.threads 处理线程数量时移除多余的线程并关闭

4.KafkaRequestHandlePool 和 KafkaRequestHandler
1.KafkaRequestHandlerPool
真正处理 Kafka 请求的地方,它是一个请求处理线程池,主要负责创建、维护、管理和销毁下辖的请求处理线程。
2.KafkaRequestHandler
真正的业务请求处理线程类,每个请求处理线程实例,负责从 SocketServer 的 RequestChannel 的请求队列中获取请求对象,并进行处理。如下是 KafkaRequestHandler 的线程处理的方法体:
def run(): Unit = {threadRequestChannel.set(requestChannel)while (!stopped) {// We use a single meter for aggregate idle percentage for the thread pool.// Since meter is calculated as total_recorded_value / time_window and// time_window is independent of the number of threads, each recorded idle// time should be discounted by # threads.val startSelectTime = time.nanoseconds// 从请求队列中获取下一个待处理的请求val req = requestChannel.receiveRequest(300)val endTime = time.nanosecondsval idleTime = endTime - startSelectTimeaggregateIdleMeter.mark(idleTime / totalHandlerThreads.get)req match {case RequestChannel.ShutdownRequest =>debug(s"Kafka request handler $id on broker $brokerId received shut down command")completeShutdown()returncase callback: RequestChannel.CallbackRequest =>val originalRequest = callback.originalRequesttry {// If we've already executed a callback for this request, reset the times and subtract the callback time from the // new dequeue time. This will allow calculation of multiple callback times.// Otherwise, set dequeue time to now.if (originalRequest.callbackRequestDequeueTimeNanos.isDefined) {val prevCallbacksTimeNanos = originalRequest.callbackRequestCompleteTimeNanos.getOrElse(0L) - originalRequest.callbackRequestDequeueTimeNanos.getOrElse(0L)originalRequest.callbackRequestCompleteTimeNanos = NoneoriginalRequest.callbackRequestDequeueTimeNanos = Some(time.nanoseconds() - prevCallbacksTimeNanos)} else {originalRequest.callbackRequestDequeueTimeNanos = Some(time.nanoseconds())}threadCurrentRequest.set(originalRequest)callback.fun(requestLocal)} catch {case e: FatalExitError =>completeShutdown()Exit.exit(e.statusCode)case e: Throwable => error("Exception when handling request", e)} finally {// When handling requests, we try to complete actions after, so we should try to do so here as well.apis.tryCompleteActions()if (originalRequest.callbackRequestCompleteTimeNanos.isEmpty)originalRequest.callbackRequestCompleteTimeNanos = Some(time.nanoseconds())threadCurrentRequest.remove()}// 普通情况由KafkaApis.handle方法执行相应处理逻辑case request: RequestChannel.Request =>try {request.requestDequeueTimeNanos = endTimetrace(s"Kafka request handler $id on broker $brokerId handling request $request")threadCurrentRequest.set(request)apis.handle(request, requestLocal)} catch {case e: FatalExitError =>completeShutdown()Exit.exit(e.statusCode)case e: Throwable => error("Exception when handling request", e)} finally {threadCurrentRequest.remove()request.releaseBuffer()}case RequestChannel.WakeupRequest => // We should handle this in receiveRequest by polling callbackQueue.warn("Received a wakeup request outside of typical usage.")case null => // continue}}completeShutdown()
}这里的 56 行会将任务最重分配给 KafkaApis 的 handle 进行处理。
03
统一的请求处理转发
Kafka 中主要的业务处理方法类其实是 KafkaApis,上面的所有的通信,线程处理类,最终都是为了更好的来到 KafkaApis 的 handle。
override def handle(request: RequestChannel.Request, requestLocal: RequestLocal): Unit = {def handleError(e: Throwable): Unit = {error(s"Unexpected error handling request ${request.requestDesc(true)} " +s"with context ${request.context}", e)requestHelper.handleError(request, e)}try {trace(s"Handling request:${request.requestDesc(true)} from connection ${request.context.connectionId};" +s"securityProtocol:${request.context.securityProtocol},principal:${request.context.principal}")if (!apiVersionManager.isApiEnabled(request.header.apiKey, request.header.apiVersion)) {// The socket server will reject APIs which are not exposed in this scope and close the connection// before handing them to the request handler, so this path should not be exercised in practicethrow new IllegalStateException(s"API ${request.header.apiKey} with version ${request.header.apiVersion} is not enabled")}request.header.apiKey match {case ApiKeys.PRODUCE => handleProduceRequest(request, requestLocal)case ApiKeys.FETCH => handleFetchRequest(request)case ApiKeys.LIST_OFFSETS => handleListOffsetRequest(request)case ApiKeys.METADATA => handleTopicMetadataRequest(request)case ApiKeys.LEADER_AND_ISR => handleLeaderAndIsrRequest(request)case ApiKeys.STOP_REPLICA => handleStopReplicaRequest(request)case ApiKeys.UPDATE_METADATA => handleUpdateMetadataRequest(request, requestLocal)case ApiKeys.CONTROLLED_SHUTDOWN => handleControlledShutdownRequest(request)case ApiKeys.OFFSET_COMMIT => handleOffsetCommitRequest(request, requestLocal).exceptionally(handleError)case ApiKeys.OFFSET_FETCH => handleOffsetFetchRequest(request).exceptionally(handleError)case ApiKeys.FIND_COORDINATOR => handleFindCoordinatorRequest(request)case ApiKeys.JOIN_GROUP => handleJoinGroupRequest(request, requestLocal).exceptionally(handleError)case ApiKeys.HEARTBEAT => handleHeartbeatRequest(request).exceptionally(handleError)case ApiKeys.LEAVE_GROUP => handleLeaveGroupRequest(request).exceptionally(handleError)case ApiKeys.SYNC_GROUP => handleSyncGroupRequest(request, requestLocal).exceptionally(handleError)case ApiKeys.DESCRIBE_GROUPS => handleDescribeGroupsRequest(request).exceptionally(handleError)case ApiKeys.LIST_GROUPS => handleListGroupsRequest(request).exceptionally(handleError)case ApiKeys.SASL_HANDSHAKE => handleSaslHandshakeRequest(request)case ApiKeys.API_VERSIONS => handleApiVersionsRequest(request)case ApiKeys.CREATE_TOPICS => maybeForwardToController(request, handleCreateTopicsRequest)case ApiKeys.DELETE_TOPICS => maybeForwardToController(request, handleDeleteTopicsRequest)case ApiKeys.DELETE_RECORDS => handleDeleteRecordsRequest(request)case ApiKeys.INIT_PRODUCER_ID => handleInitProducerIdRequest(request, requestLocal)case ApiKeys.OFFSET_FOR_LEADER_EPOCH => handleOffsetForLeaderEpochRequest(request)case ApiKeys.ADD_PARTITIONS_TO_TXN => handleAddPartitionsToTxnRequest(request, requestLocal)case ApiKeys.ADD_OFFSETS_TO_TXN => handleAddOffsetsToTxnRequest(request, requestLocal)case ApiKeys.END_TXN => handleEndTxnRequest(request, requestLocal)case ApiKeys.WRITE_TXN_MARKERS => handleWriteTxnMarkersRequest(request, requestLocal)case ApiKeys.TXN_OFFSET_COMMIT => handleTxnOffsetCommitRequest(request, requestLocal).exceptionally(handleError)case ApiKeys.DESCRIBE_ACLS => handleDescribeAcls(request)case ApiKeys.CREATE_ACLS => maybeForwardToController(request, handleCreateAcls)case ApiKeys.DELETE_ACLS => maybeForwardToController(request, handleDeleteAcls)case ApiKeys.ALTER_CONFIGS => handleAlterConfigsRequest(request)case ApiKeys.DESCRIBE_CONFIGS => handleDescribeConfigsRequest(request)case ApiKeys.ALTER_REPLICA_LOG_DIRS => handleAlterReplicaLogDirsRequest(request)case ApiKeys.DESCRIBE_LOG_DIRS => handleDescribeLogDirsRequest(request)case ApiKeys.SASL_AUTHENTICATE => handleSaslAuthenticateRequest(request)case ApiKeys.CREATE_PARTITIONS => maybeForwardToController(request, handleCreatePartitionsRequest)// Create, renew and expire DelegationTokens must first validate that the connection// itself is not authenticated with a delegation token before maybeForwardToController.case ApiKeys.CREATE_DELEGATION_TOKEN => handleCreateTokenRequest(request)case ApiKeys.RENEW_DELEGATION_TOKEN => handleRenewTokenRequest(request)case ApiKeys.EXPIRE_DELEGATION_TOKEN => handleExpireTokenRequest(request)case ApiKeys.DESCRIBE_DELEGATION_TOKEN => handleDescribeTokensRequest(request)case ApiKeys.DELETE_GROUPS => handleDeleteGroupsRequest(request, requestLocal).exceptionally(handleError)case ApiKeys.ELECT_LEADERS => maybeForwardToController(request, handleElectLeaders)case ApiKeys.INCREMENTAL_ALTER_CONFIGS => handleIncrementalAlterConfigsRequest(request)case ApiKeys.ALTER_PARTITION_REASSIGNMENTS => maybeForwardToController(request, handleAlterPartitionReassignmentsRequest)case ApiKeys.LIST_PARTITION_REASSIGNMENTS => maybeForwardToController(request, handleListPartitionReassignmentsRequest)case ApiKeys.OFFSET_DELETE => handleOffsetDeleteRequest(request, requestLocal).exceptionally(handleError)case ApiKeys.DESCRIBE_CLIENT_QUOTAS => handleDescribeClientQuotasRequest(request)case ApiKeys.ALTER_CLIENT_QUOTAS => maybeForwardToController(request, handleAlterClientQuotasRequest)case ApiKeys.DESCRIBE_USER_SCRAM_CREDENTIALS => handleDescribeUserScramCredentialsRequest(request)case ApiKeys.ALTER_USER_SCRAM_CREDENTIALS => maybeForwardToController(request, handleAlterUserScramCredentialsRequest)case ApiKeys.ALTER_PARTITION => handleAlterPartitionRequest(request)case ApiKeys.UPDATE_FEATURES => maybeForwardToController(request, handleUpdateFeatures)case ApiKeys.ENVELOPE => handleEnvelope(request, requestLocal)case ApiKeys.DESCRIBE_CLUSTER => handleDescribeCluster(request)case ApiKeys.DESCRIBE_PRODUCERS => handleDescribeProducersRequest(request)case ApiKeys.UNREGISTER_BROKER => forwardToControllerOrFail(request)case ApiKeys.DESCRIBE_TRANSACTIONS => handleDescribeTransactionsRequest(request)case ApiKeys.LIST_TRANSACTIONS => handleListTransactionsRequest(request)case ApiKeys.ALLOCATE_PRODUCER_IDS => handleAllocateProducerIdsRequest(request)case ApiKeys.DESCRIBE_QUORUM => forwardToControllerOrFail(request)case ApiKeys.CONSUMER_GROUP_HEARTBEAT => handleConsumerGroupHeartbeat(request).exceptionally(handleError)case ApiKeys.CONSUMER_GROUP_DESCRIBE => handleConsumerGroupDescribe(request).exceptionally(handleError)case ApiKeys.GET_TELEMETRY_SUBSCRIPTIONS => handleGetTelemetrySubscriptionsRequest(request)case ApiKeys.PUSH_TELEMETRY => handlePushTelemetryRequest(request)case ApiKeys.LIST_CLIENT_METRICS_RESOURCES => handleListClientMetricsResources(request)case _ => throw new IllegalStateException(s"No handler for request api key ${request.header.apiKey}")}} catch {case e: FatalExitError => throw ecase e: Throwable => handleError(e)} finally {// try to complete delayed action. In order to avoid conflicting locking, the actions to complete delayed requests// are kept in a queue. We add the logic to check the ReplicaManager queue at the end of KafkaApis.handle() and the// expiration thread for certain delayed operations (e.g. DelayedJoin)// Delayed fetches are also completed by ReplicaFetcherThread.replicaManager.tryCompleteActions()// The local completion time may be set while processing the request. Only record it if it's unset.if (request.apiLocalCompleteTimeNanos < 0)request.apiLocalCompleteTimeNanos = time.nanoseconds}
}从上面代码可以看到负责副本管理的 ReplicaManager、维护消费者组的 GroupCoordinator ,操作 Controller 组件的 KafkaController,还有我们最常用到的 KafkaProducer.send(发送消息)和 KafkaConcumser.consume(消费消息)。
04
AutoMQ 中线程模型
1. 处理线程的优化
AutoMQ 参照 CPU 的流水线将 Kafka 的处理模型优化成流水线模式,兼顾了顺序性和高效两方面。
顺序性:TCP 连接与线程绑定,对于同一个 TCP 连接有且只有一个网络线程在解析请求,并且有且只有一个 RequestHandler 线程在进行业务逻辑处理;
高效:不同阶段流水线化,网络线程解析完 MSG1 后就可以立马解析 MSG2,无需等待 MSG1 持久化完成。同理 RequestHandler 对 MSG1 进行完校验 & 定序后,立马就可以开始处理 MSG2;同时为了进一步提高持久化的效率,AutoMQ 还会将数据攒批进行刷盘持久化。
2. 通道 RequestChannel 的优化
AutoMQ 将 RequestChannel 进行了多队列改造,通过多队列模式,可以做到对于相同连接的请求都被放入相同一个队列,并且只被特定的 KafkaRequestHandler 进行业务逻辑处理,保障了检验 & 定序阶段内部的顺序处理。
队列和 KafkaRequestHandler 一一映射,数量保持一致;
Processor 解析完请求后,根据 hash(channelId) % N 来决定路由到特定的队列。
参考资料 [1]AutoMQ:https://github.com/AutoMQ/automq
[2]Kafka3.7:https://github.com/apache/kafka/releases/tag/3.7.0
[3]JAVANIO:https://jenkov.com/tutorials/java-nio/overview.html
[4]AutoMQ 线程优化:https://mp.weixin.qq.com/s/kDZJgUnMoc5K8jTuV08OJw
END
关于我们
我们是来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
🌟 GitHub 地址:https://github.com/AutoMQ/automq
💻 官网:https://www.automq.com
这篇关于「布道师系列文章」众安保险王凯解析 Kafka 网络通信的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







