本文主要是介绍【传知代码】探索视觉与语言模型的可扩展性(论文复现),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:在数字化时代的浪潮中,我们见证了人工智能(AI)技术的飞速发展,其中视觉与语言模型作为两大核心领域,正以前所未有的速度改变着我们的生活和工作方式。从图像识别到自然语言处理,从虚拟现实到智能客服,这些技术的广泛应用已经渗透到了社会的各个角落。然而,随着数据量的激增和应用场景的复杂化,如何确保视觉与语言模型的可扩展性,使其能够持续适应并满足日益增长的需求,成为了摆在我们面前的一大挑战。
本文所涉及所有资源均在传知代码平台可获取
目录
概述
性能评估分析
项目部署
写在最后
概述
视觉与语言结合模型的兴起标志着一个重要的发展阶段。这些多模态模型不仅能够理解图像内容,还能够处理和生成与图像相关的语言描述,极大地推动了跨模态交互和理解的进展。从社交媒体的内容标签到自动图像标注,再到复杂的视觉问答和场景理解任务,这些模型在多个应用场景中展现出了巨大的潜力。随着技术的进步,这些模型正在逐渐渗透到我们的日常生活中,成为连接视觉世界与语言理解的桥梁。
在《Learning Transferable Visual Models From Natural Language Supervision》这篇开创性的论文中,Alec Radford及其团队不仅提出了CLIP模型,还展示了如何通过自然语言的监督来训练一个能够理解图像内容的模型。CLIP模型的提出,代表了一种从传统监督学习范式向更灵活的学习和推理模型转变的尝试。这种转变的核心在于利用自然语言的广泛性和灵活性,来指导模型学习更为丰富和多样化的视觉表示。 CLIP模型的训练过程涉及到大量的图像和相应的文本描述,这些数据对是从互联网上自动收集而来。通过预测成对的图像和文本是否匹配,CLIP模型能够学习到一种联合的图像-文本表示空间,其中图像和文本的表示是紧密相连的。这种联合表示不仅能够用于图像的分类和检索,还能够支持模型在没有额外训练的情况下,通过自然语言的提示来解决新的、未见过的任务,如下图所示:
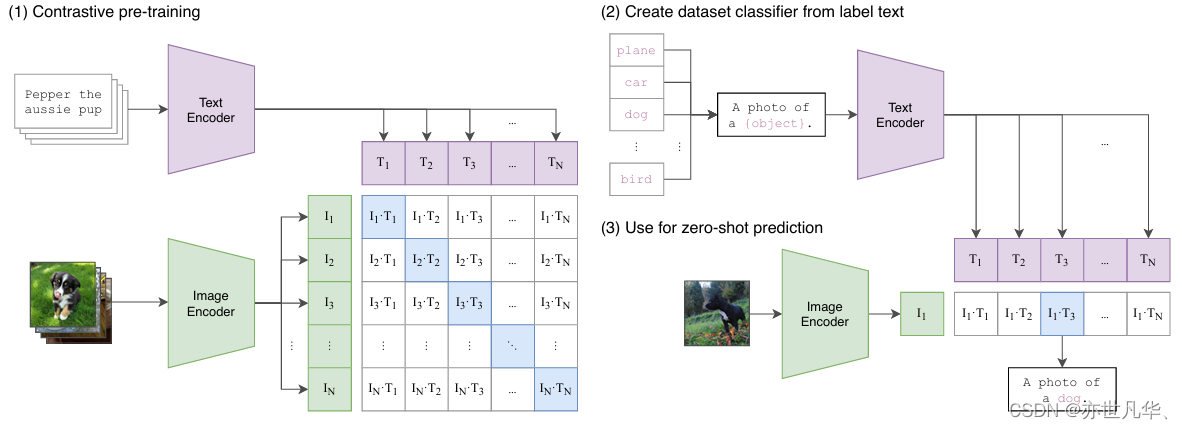
关于论文中出现的相关关键的概念进行如下的解释:
1)零样本学习:在零样本学习的设置中,模型在没有直接训练样本的情况下尝试识别新的类别。CLIP模型通过在预训练阶段学习图像和文本之间的关联,能够在测试时通过文本描述来识别新的类别。这种方法的优势在于,它允许模型泛化到新的、未见过的类别,从而扩展了模型的应用范围。
2)对比预训练:CLIP模型使用对比学习的方法来训练,这是一种通过最大化图像和文本对之间的相似度,同时最小化错误配对之间相似度的方法。通过这种方式,模型不仅学习到区分不同图像的能力,还学习到了如何根据文本描述来检索或分类图像。
3)任务不可知架构:CLIP模型的设计哲学是通用性和灵活性。它不针对任何特定的任务进行优化,而是旨在学习一种通用的视觉表示,这种表示可以适用于多种不同的任务。这种架构的优势在于,它减少了对特定任务数据的依赖,使得模型能够更容易地迁移到新的任务上。
最终可以看到实验的结果如下所示:

零-shot CLIP 在竞争对手中表现出色。在包括 ImageNet 在内的 27 个数据集评估套件中,零-shot CLIP 分类器在 16 个数据集上优于基于 ResNet-50 特征训练的完全监督线性分类器:
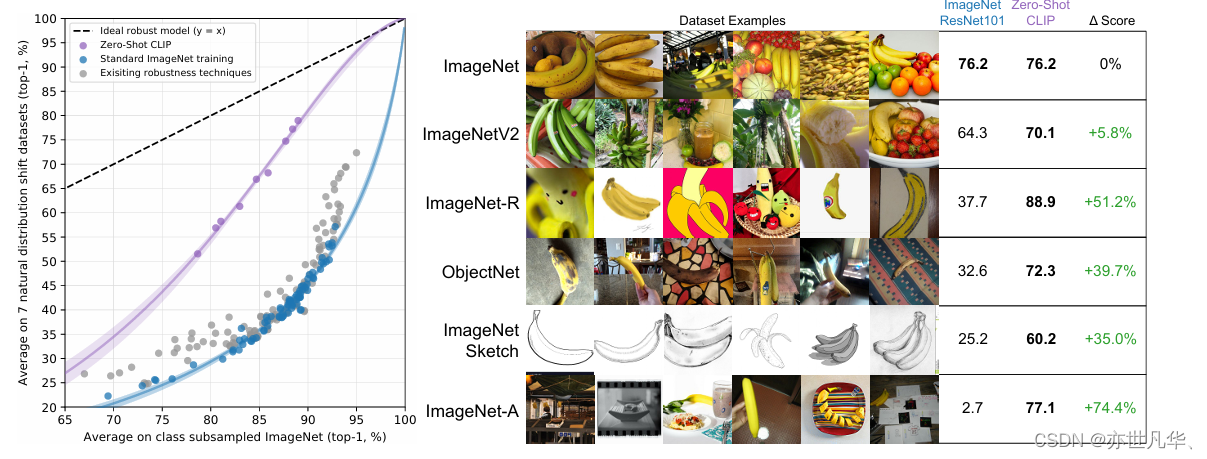
零-shot CLIP 对分布转移具有比标准 ImageNet 模型更强的鲁棒性。(左图)理想的鲁棒模型(虚线)在 ImageNet 分布和其他自然图像分布上表现同样出色。零-shot CLIP 模型将这种“鲁棒性差距”缩小了高达 75%。对 logit 转换值进行线性拟合,并显示 bootstrap 估计的 95% 置信区间。右图)对香蕉这一跨越了 7 个自然分布转移数据集的类别进行分布转移可视化。最佳零-shot CLIP 模型 ViT-L/14@336px 的性能与在 ImageNet 验证集上具有相同性能的 ResNet-101 模型进行比较。
论文中的实验结果部分,详细地展示了CLIP模型在多个计算机视觉任务上的性能。这些任务包括但不限于图像分类、图像检索、视频动作识别和地理定位等。CLIP模型在这些任务上的表现,不仅证明了其学习到的视觉表示的有效性,也展示了其在不同任务上的可迁移性。 在ImageNet数据集上的实验结果显示,CLIP模型在零样本学习设置下达到了令人印象深刻的准确率,与完全监督的ResNet-50模型相当。这一结果凸显了CLIP模型在没有访问训练样本的情况下,通过文本描述进行有效分类的能力。 此外,CLIP模型在其他数据集上的表现也同样出色。例如,在OCR任务中,CLIP能够识别图像中的文本,并将其转换为可编辑的文本形式。
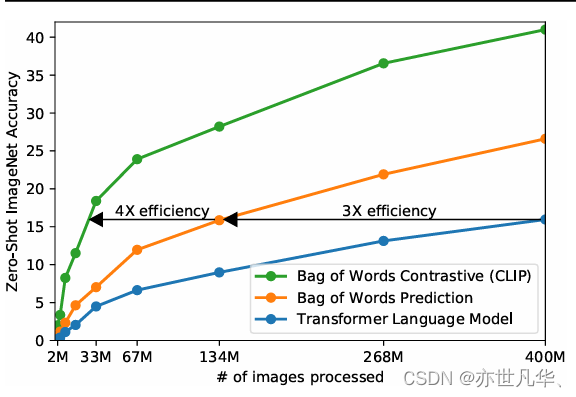
模型规模和数据大小的扩展导致视觉任务适应基准(VTAB)上线性分类器的误差降低[85]。我们为至少见过 13 亿样本的模型训练线性探针,如下所示:

使用 pHash在下游数据集和 LAION 400M 之间检测到重复图像。顶部行显示来自下游数据集的图像,而底部行显示在 LAION-400M 中检测到的相应重复图像。我们观察到对各种图像变换的近似重复检测:模糊、文本覆盖、颜色转换、裁剪和缩放。最后两列显示在 ImageNet-Sketch 数据集中检测到的误报例子。总体而言,我们观察到大多数误报情况具有统一的背景,而 pHash 似乎对此类情况比较敏感:

性能评估分析
在深入探讨CLIP模型的性能评估与分析之前,让我们先对CLIP(Contrastive Language-Image Pre-training)有一个基本的了解。CLIP是由OpenAI提出的一种基于自然语言监督的图像学习模型,它通过对海量互联网图片和相关文本的配对学习,能够实现对图像的丰富语义理解。CLIP模型的提出,为图像和语言的联合表示学习提供了新的视角,并且在多项任务上展现了出色的性能,如下所示:

接下来对相关性能评估进行一个简单的概述:
零样本分类:是衡量模型泛化能力的重要指标,尤其是在面对未见过的类别时。CLIP模型通过在海量的图像-文本对上进行预训练,学习到了一种能够将图像内容与语言描述相联系的通用表示。这种表示使得CLIP能够在没有任何特定类别样本的情况下,通过文本描述来识别图像的潜在类别。 在零样本分类的实验中,CLIP模型展现了其强大的性能。
图像与文本检索:任务要求模型能够理解图像内容以及文本描述,从而实现精确的信息检索。CLIP模型在这方面的表现同样出色。它能够根据给定的文本描述检索出与之相关的图像,或者根据图像内容找到最合适的文本描述。这种能力在多媒体内容管理、图像数据库检索和基于描述的图像搜索等应用中具有重要价值。
鲁棒性测试:是评估模型在面对不同数据分布时性能稳定性的重要手段。CLIP模型在多个自然分布的数据集上进行了广泛的测试,包括但不限于ImageNet的变种数据集,如ImageNet-V2、ImageNet-A、ImageNet-R等。这些数据集包含了风格多样的图像,如草图、风格化图像和真实世界图像,它们代表了不同的视觉内容和分布。
CLIP模型的提出和成功应用,为图像和语言的联合表示学习开辟了新的道路。通过自然语言监督学习,CLIP不仅在零样本分类任务上展现了强大的泛化能力,而且在图像与文本检索任务上也表现出了卓越的性能。此外,CLIP模型在多个自然分布的数据集上所展示的鲁棒性,进一步证明了其在现实世界视觉任务中的应用潜力,如下图所示:

项目部署
可以使用Anaconda或Miniconda来管理Python环境,这样可以避免系统级别的冲突:
conda create -n myenv python=3.8
conda activate myenv根据你的系统和CUDA版本(如果有)安装PyTorch。访问PyTorch官方网站获取正确的安装命令:
# 假设我们不需要CUDA支持,使用CPU版本的PyTorch
conda install -c pytorch pytorch torchvision torchaudio cpuonly -p hostPillow是Python中的一个图像处理库,可以通过以下命令安装:
pip install Pillow使用pip安装所需的Python包:
# 安装OpenCLIP
pip install open_clip_torch# 安装Chinese-CLIP
pip install cn_clip加载OpenCLIP或Chinese-CLIP的预训练模型:
# 加载OpenCLIP模型
import open_clip
model, _, preprocess = open_clip.create_model_and_transforms('ViT-B-32', pretrained='laion2b_s34b_b79k')# 加载Chinese-CLIP模型
import cn_clip
model, preprocess = cn_clip.load_from_name("ViT-B-16", device="cuda" if torch.cuda.is_available() else "cpu")
model.eval()对图像和文本进行预处理并提取特征:
from PIL import Image# 图像特征提取
image_path = 'path_to_your_image.jpg' # 替换为你的图像路径
image = preprocess(Image.open(image_path)).unsqueeze(0).to(model.device if 'cn_clip' in globals() else 'cpu')
with torch.no_grad():image_features = model.encode_image(image)# 文本特征提取
tokenizer = open_clip.get_tokenizer('ViT-B-32') if 'open_clip' in globals() else cn_clip.tokenize
text_inputs = ["描述你的图像"] # 替换为你想要的文本描述
text = tokenizer(text_inputs).to(model.device if 'cn_clip' in globals() else 'cpu')
with torch.no_grad():text_features = model.encode_text(text)使用提取的特征进行匹配或其他应用:
# 归一化特征
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)# 计算匹配得分
similarity = image_features @ text_features.TTensorRT的导出过程较为复杂,通常需要一个支持CUDA的系统,并且需要NVIDIA的TensorRT库。具体步骤可能因模型而异,但通常包括以下步骤:
1)将模型转换为ONNX格式
2)使用TensorRT的Python API将ONNX模型转换为TensorRT优化的引擎
import torch
# 假设你已经加载了OpenCLIP的预训练模型和tokenizer
# 并已经对图像进行了特征提取
dummy_image = preprocess(Image.open("path_to_your_image.jpg")).unsqueeze(0)
torch.onnx.export(model,dummy_image,"openclip_model.onnx",export_params=True,opset_version=12, # 根据需要选择合适的opset版本do_constant_folding=True,input_names=['input'],output_names=['output'],dynamic_axes={'input': {0: 'batch_size'}, 'output': {0: 'batch_size'}}
)使用Flask创建简单的Web服务(以OpenCLIP为例)创建Flask应用:
from flask import Flask, request, jsonify
from PIL import Image
import io
import torchapp = Flask(__name__)@app.route('/predict', methods=['POST'])
def predict():data = request.get_json(force=True)image = data['image']image = Image.open(io.BytesIO(image))image = preprocess(image).unsqueeze(0)with torch.no_grad():features = model.encode_image(image)# 根据需要添加文本特征匹配或其他逻辑return jsonify({'similarity': features.tolist()})if __name__ == '__main__':app.run(debug=True)将模型集成到更大的工作流中可能涉及以下步骤:
1)使用Docker容器化你的应用,以便于部署。
2)使用Kubernetes或其他编排工具管理容器。
3)设置持续集成/持续部署(CI/CD)流程。
4)确保监控和日志记录,以便跟踪应用的性能和状态。
写在最后
随着技术的不断进步和应用场景的不断拓展,视觉与语言模型的可扩展性将面临更多的挑战和机遇。我们可以预见,未来的模型将能够处理更大规模的数据、更复杂的任务和更广泛的环境。它们将能够自我学习、自我优化、自我适应,以应对不断变化的世界,在这个充满变革的时代,我们期待视觉与语言模型的可扩展性能够为我们带来更多的惊喜和可能性。它们将不仅改变我们的生活方式和工作方式,还将推动社会的进步和发展。让我们共同期待一个更加智能、便捷和可持续的未来吧!
详细复现过程的项目源码、数据和预训练好的模型可从该文章下方附件获取。
【传知科技】关注有礼 公众号、抖音号、视频号

这篇关于【传知代码】探索视觉与语言模型的可扩展性(论文复现)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





