本文主要是介绍基于DeepLabv3+实现图像分割,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 1. 作者介绍
- 2. DeepLabv3+算法
- 2.1 DeepLabv3+算法介绍
- 2.2 DeepLabv3+模型结构
- 3. 实验过程基于DeepLabv3+实现图像分割
- 3.1 VOC数据集介绍
- 3.2 代码实现
- 3.3 问题分析
- 4. 参考连接
1. 作者介绍
吴天禧,女,西安工程大学电子信息学院,2023级研究生,张宏伟人工智能课题组
研究方向:模式识别与智能系统
电子邮件:230411046@stu.xpu.edu.cn
路治东,男,西安工程大学电子信息学院,2022级研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:2063079527@qq.com
2. DeepLabv3+算法
2.1 DeepLabv3+算法介绍
DeepLabv3+是一种先进的语义图像分割算法,它通过结合编码器-解码器架构和Atrous卷积来实现对图像中每个像素的精确分类。
该算法利用DeepLabv3作为编码器,有效地捕捉丰富的上下文信息,并通过一个简单而有效的解码器模块来细化分割结果,尤其是在物体的边界区域。Atrous卷积允许模型以任意分辨率提取特征,这为处理不同尺寸的物体提供了灵活性。
此外,DeepLabv3+还采用了Xception模型和深度可分离卷积技术,显著提高了计算效率,同时保持了分割精度。
2.2 DeepLabv3+模型结构
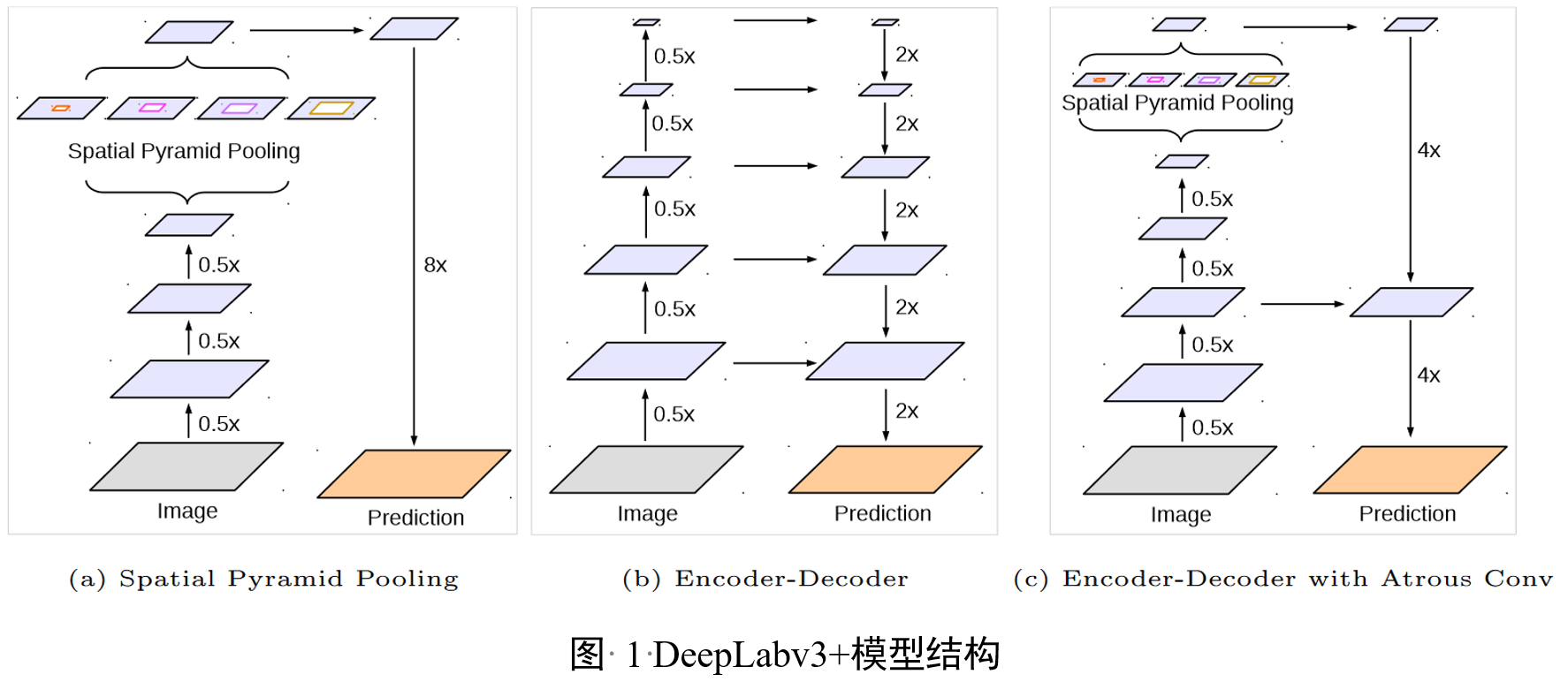
图1展示了DeepLabv3+模型的结构,该模型结合了编码器-解码器结构的优势以及空间金字塔池化模块。(a)部分显示了空间金字塔池化(Spatial Pyramid Pooling, SPP)模块,它通过在不同比例的网格上进行池化操作来捕获多尺度上下文信息。(b)部分展示了编码器-解码器(Encoder-Decoder)结构,它能够通过逐步恢复空间信息来捕获更锐利的物体边界。©部分则展示了带有Atrous卷积的编码器-解码器结构,这是DeepLabv3+模型的核心,其中编码器模块包含了丰富的语义信息,而解码器模块则用于恢复详细的物体边界。Atrous卷积允许以任意分辨率提取特征,这为模型提供了灵活性。
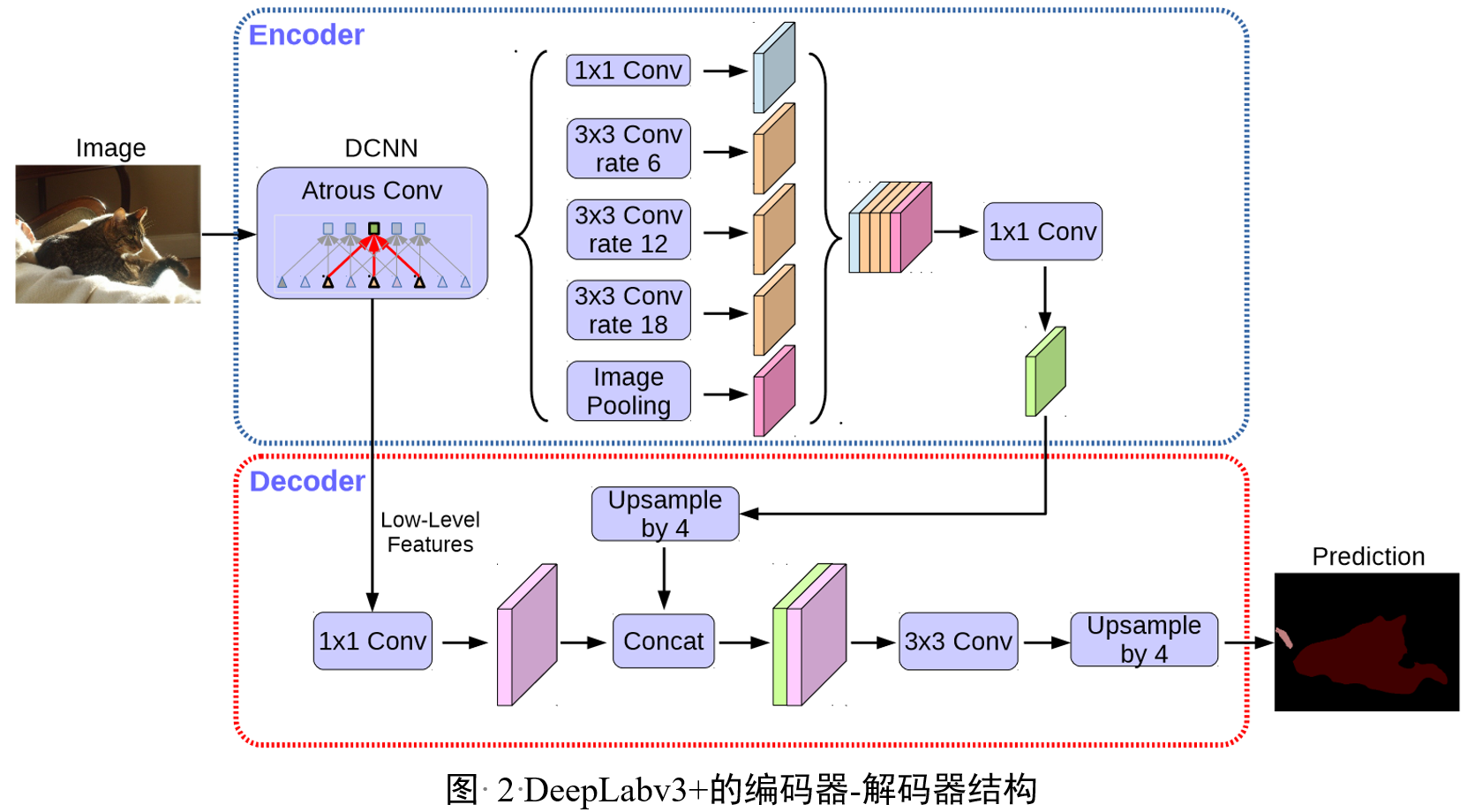
图2详细展示了DeepLabv3+模型的编码器和解码器模块。编码器模块通过多尺度的Atrous卷积来编码多尺度上下文信息,而解码器模块则用于细化分割结果,尤其是在物体边界上。在该模型中,首先使用Atrous卷积提取特征,然后通过解码器模块逐步恢复图像的空间分辨率,以获得更精细的分割效果。
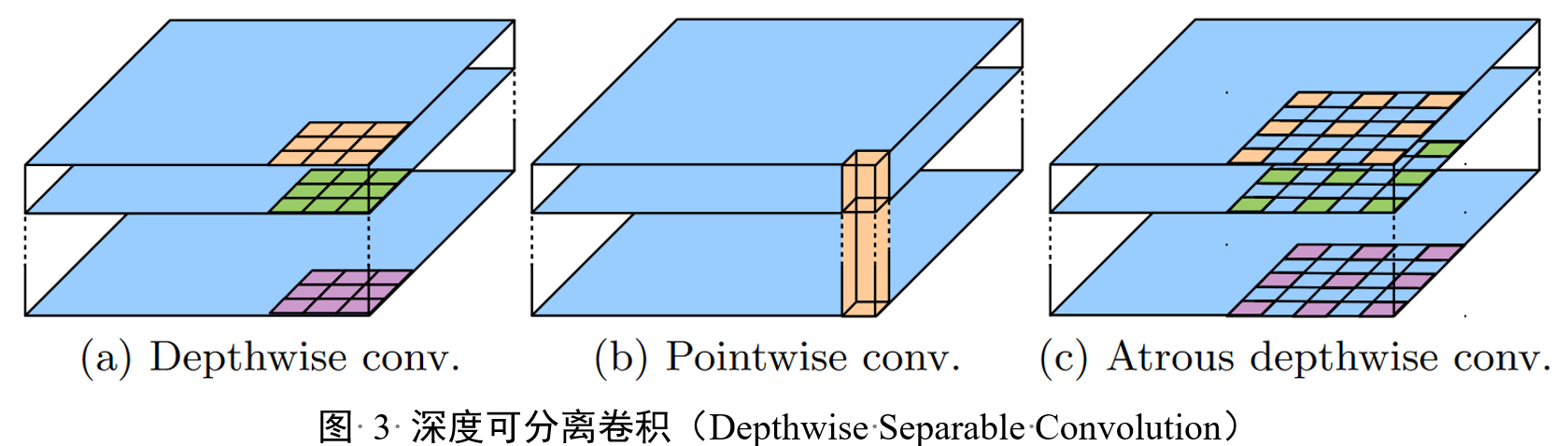
图3解释了深度可分离卷积的概念,这是一种减少计算复杂度的技术。(a)图展示了深度卷积(Depthwise Convolution),它对每个输入通道独立应用卷积核。(b)图展示了点卷积(Pointwise Convolution),它在深度卷积的输出上进行1x1的卷积,以组合不同通道的信息。©图展示了Atrous深度可分离卷积,这是在深度卷积中应用了Atrous卷积,允许模型以不同的采样率来捕获多尺度信息。
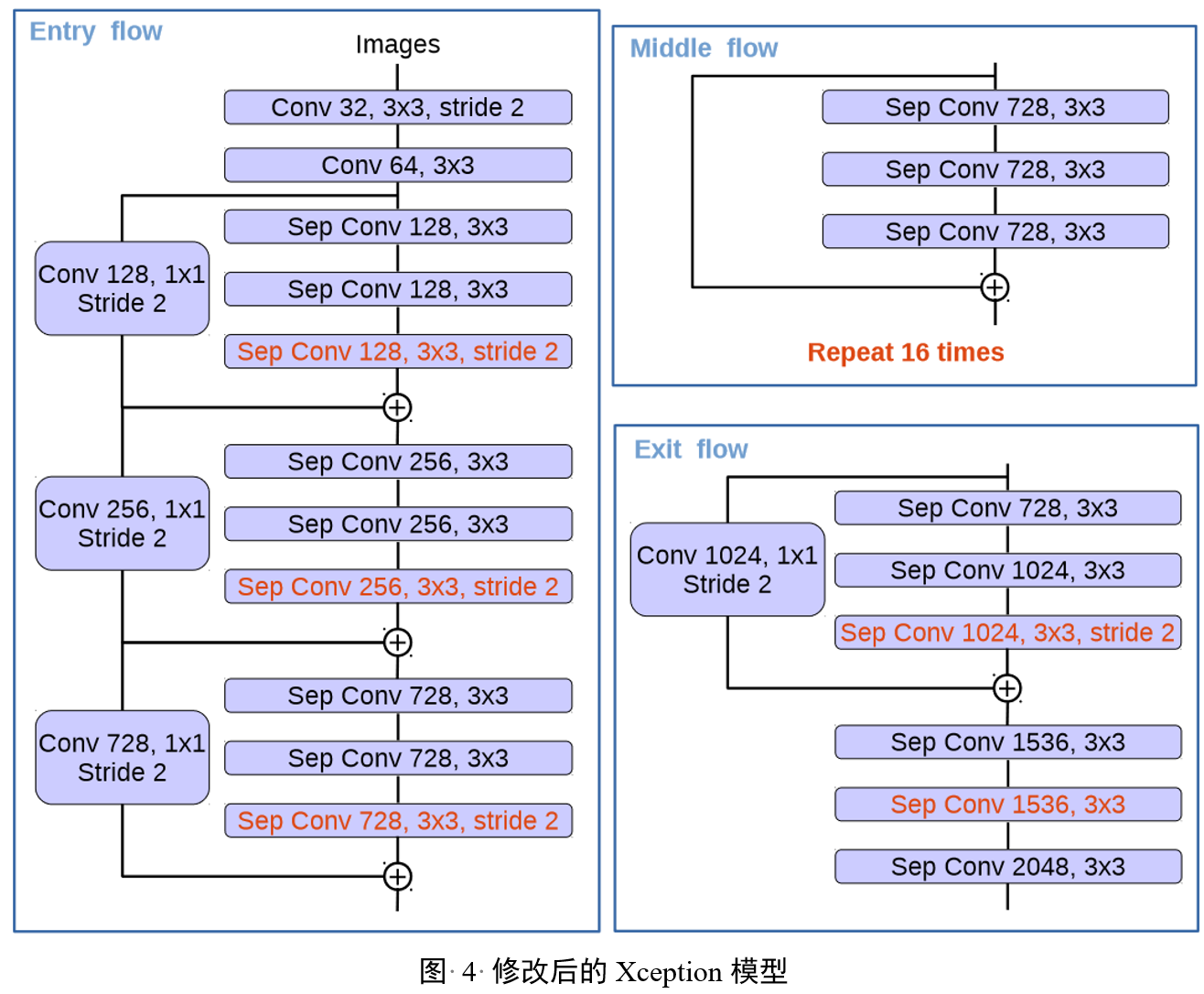
图4描述了对Xception模型的修改,使其更适合于语义图像分割任务。修改包括增加更多的层以捕获更深层次的特征,将所有最大池化操作替换为带有步长的深度可分离卷积,以及在每个3x3深度卷积后添加额外的批量归一化(Batch Normalization)和ReLU激活函数,这与MobileNet的设计相似。
3. 实验过程基于DeepLabv3+实现图像分割
3.1 VOC数据集介绍
PASCAL VOC挑战赛 (The PASCAL Visual Object Classes )是一个世界级的计算机视觉挑战赛,PASCAL全称:Pattern Analysis, Statical Modeling and Computational Learning,是一个由欧盟资助的网络组织。PASCAL VOC挑战赛主要包括以下几类:图像分类(Object Classification),目标检测(Object Detection),目标分割(Object Segmentation),行为识别(Action Classification) 等。

下面是数据集的展示,包括(a)图像分类与目标检测任务;(b)分割任务,注意,图像分割一般包括语义分割、实例分割和全景分割,实例分割是要把每个单独的目标用一种颜色表示(下图中间的图像),而语义分割只是把同一类别的所有目标用同一颜色表示(下图右侧的图片);(c)行为识别任务;(d)人体布局检测任务。

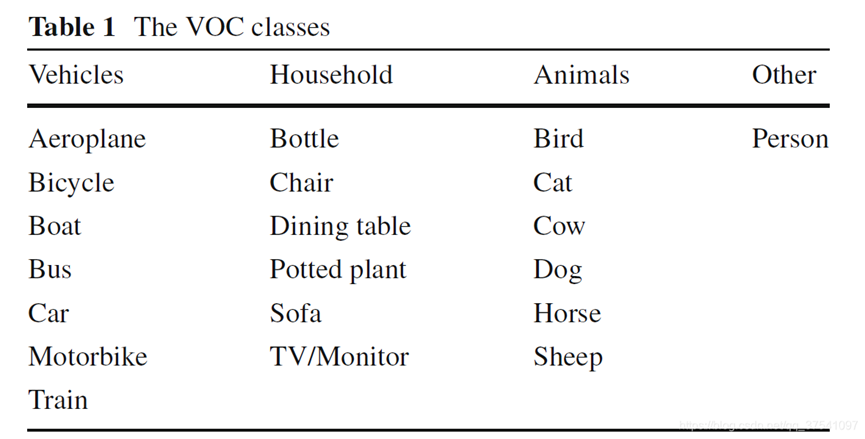
VOC数据集中主要包含20个目标类别,这个图展示了所有类别的名称以及所属大类。
3.2 代码实现
Main.py是一个用于图像分割的深度学习训练脚本。
- get_argparser() 函数定义了一个命令行参数解析器,允许用户在运行脚本时指定各种配置选项,如数据集路径、模型类型、训练选项、学习率、批大小等。
- validate() 函数执行模型的验证,计算指标(如IoU),并可选择保存验证结果和可视化样本。
- 主函数
main()
设置数据集类别数(基于所选数据集);
初始化可视化工具;
设置GPU和随机种子;
加载和初始化数据加载器;
根据参数构建模型,并将其置于GPU上;
设置优化器、学习率调度器和损失函数;
如果提供了检查点文件,恢复训练状态;
进入训练循环,包括前向传播、损失计算、反向传播和参数更新;
在每个验证间隔执行验证,并根据验证结果更新最佳模型;
使用Visdom可视化训练损失和验证指标。 - 训练循环:
模型设置为训练模式;
迭代训练数据加载器中的批次;
执行前向传播,计算损失;
执行反向传播,更新模型参数;
在指定间隔打印损失并进行可视化;
定期执行验证,并保存最佳模型。 - 检查点保存 save_ckpt() 函数负责保存当前模型的状态、优化器状态、学习率调度器状态和最佳验证分数到文件。
- 可视化
如果启用,使用Visdom可视化训练损失和验证指标。 - 模型评估
如果设置了–test_only ,模型将进行评估而不进行训练。
3.3 问题分析
python main.py --model deeplabv3plus_resnet50 --enable_vis --vis_port 28333 --gpu_id 0 --year 2012 --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16

下载的voc数据集中没有2008_000942.png图,这个图应该在2012_aug中,但下载的voc2012中没有,训练时改成2012就可以了,测试也一样。
4. 参考连接
- Voc数据集
- DeepLabv3+论文
- 代码:VainF/DeepLabV3Plus-Pytorch: Pretrained DeepLabv3 and DeepLabv3+ for Pascal VOC & Cityscapes
这篇关于基于DeepLabv3+实现图像分割的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






