本文主要是介绍HDFS encryption 实战之背景和架构介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、HDFS encryption背景
在全世界,为零满足隐私和其他安全需求,很多政府部门、金融部门和管理单位强制要求数据加密。例如 银行支付行业为零满足信息安全必须满足支付卡行业数据安全标准 Payment Card Industry Data Security Standard (PCI DSS)。其他一些例子,美国联邦政府信息安全管理法案 United States government’s Federal Information Security Management Act (FISMA) 、医疗保险可携性和责任法案Health Insurance Portability and Accountability Act (HIPAA)。对HDFS里面的数据进行加密可以帮助你的组织应对这些规定。
HDFS encryption 实现了在集群中读写HDFS Block时透明的、端到端的数据加密。透明加密意味着终端用户无需感知encryption/decryption 过程,而端到端意味数据在静态和传输过程中都是加密的。
2、HDFS encryption 具备的能力
HDFS encryption 具备下面一些能力:
- 只有HDFS client才能够加解密 ● 为了区分开HDFS administrator, Key
Administrator这两个用户,必须要将Administration of HDFS and administration of
keys分成两个独立的功能,这样可以保证没有一个独立的用户可以同时拥有data和keys。 - 操作系统级别和HDFS交互仅使用加密数据,减轻了os和文件系统成的威胁 ● HDFS使用的是高级加密标准模式(AES-CTR)加密算法。 AES-CTR默认支持128-bit 加密key,或者在 Java Cryptography Extension (JCE) unlimited strength JCE 安装情况下,可以支持128-bit 加密key
- HDFS encryption 在设计的时候充分利用了Intel® Advanced Encryption Standard
Instructions (AES-NI)指令集,一种基于硬件的加密加速技术,所以你的集群性能在配置encryption后没有明显的性能消耗(AES-NI指令集相比于硬件实现的AES,可以提高一个数量级)。但是你需要更新HDFS和MAPREDUCE的cryptography(密码学)库才能使用加速机制。
3、主要架构
3.1 Keystores 和 the Hadoop Key Management Server
许多keystores 没有满足HDFS加解密的性能,这就需要重新设计一个新的服务,叫做 Hadoop Key Management Server (KMS)。KMS作为一个代理实现连接HDFS client和后端的keystore。keystore和HADOOP KMS 相互交互和HDFS clients交互过程中 都必须使用 Hadoop’s KeyProvider API。
当然HDFS encryption可以使用一个本地的java Keystore 作为key 管理器,Cloudera在生产环境不推荐使用本地java keystore,而是一个更健壮和安全的key 管理方案。 Cloudera Navigator Key Trustee Server 是一个管理加密key 的key store,同时具有其它一些安全特性。为了集成Cloudera Navigator Key Trustee Server,Cloudera提供了一个通用的KMS 服务,叫做Key Trustee KMS。
下面这张图解释了HDFSclients 和 NAMENODE怎么样一个企业级keystore交互。
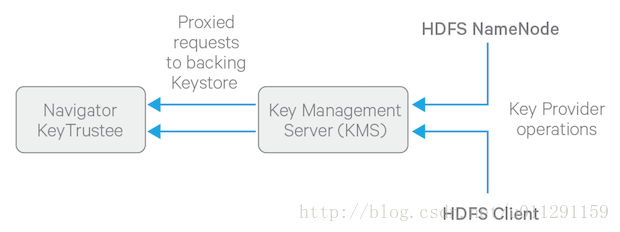
怎样安装Navigator Key Trustee和 Hadoop Key Management Server,我会在后面详细参数。
3.2、Encryption Zones and Keys
Encryption Zones(EZ) 是HDFS 上面的一个需要加密的目录。开始是一个空木了,可以使用一些工具比如distcp 将数据添加到Zones里面。拷贝到这个目录的文件和子目录都会被加密,只要添加到这个目录下面了就不可以对文件和目录进行命名。需要注意一点是不能在已经有的目录上面创建Encryption zones。
名词解释:
- 每一个EZ对应有一个 EZ key,这个key是有key administrator 在创建zone的时候指定的,EZ key存储在后端的keystore的,独立于HDFS存在的
- 在EZ里面的每一个文件 拥有自己的encryption key,叫做Data Encryption Key (DEK)
- 这些DEKS 使用了自己的EK key进行加密,然后了Encrypted Data Encryption Key (EDEK)
下面的这张图解释了怎么样使用encryption zone keys (EZ keys), data encryption keys (DEKs), 和encrypted data encryption keys (EDEKs)去解密和加密文件。
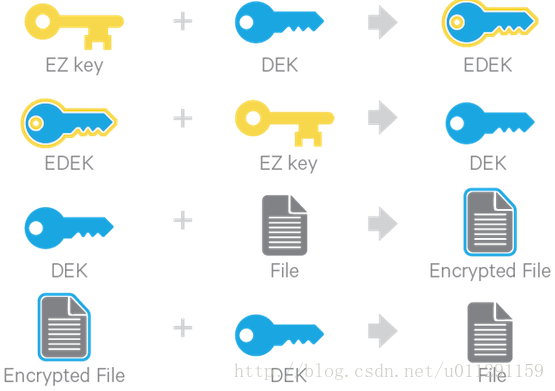
EDEKS 持久化存储在Namenode里面,作为一个文件的属性,使用了HDFS 可扩展属性。NameNode可以安全存储和处理EDEKS,因为HDFS 用户 没有权限获取EDEK’s encryption keys (EZ keys)。即使HDFS 妥协(比如获取到HDFS超级用户),这个恶意用户也只能获取到加密文件和EDEKS。EZ keys 在KMS和keystore被单独的权限管理。
一个EZ key 可以拥有多个版本,每个key version拥有自己不同key 实体(也就说, encryption and decryption使用的内容是不一样的)。key 的旋转 是通过翻滚EZ key实现的。每个文件 key的旋转是通过新的EZ可以重新加密文件的DEK ,获取到一个新的EDEK的。HDFS 可以识别一个 encrytion key主要两个途径:1)key name 最新的key version,2)指定的key version。
这个地方需要测试一下,不同的key version 是否可以 加密和解密同一份数据?
3.3 操作文件流程
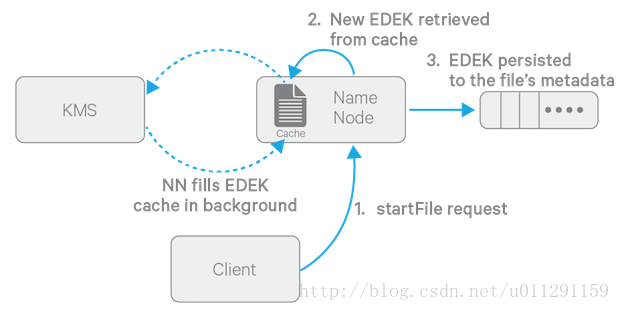
为了解密一个新文件,需要如下流程
- HDFS需要从Namenode获取一个新的EDEK
- NameNode 请求KMS 使用这个文件对应encryption zone 的EZ key 解密 EDE
- client 使用这个DEK去解密这个新文件
4、参考文档
https://www.cloudera.com/documentation/enterprise/latest/topics/cdh_sg_hdfs_encryption.html#concept_z2d_1vz_np
这篇关于HDFS encryption 实战之背景和架构介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





