本文主要是介绍2.2数据的表示和运算--原码、反码、补码、移码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2.数据的表示和运算
2.2原码、反码、补码、移码
🔺问题:真值与对应的原码、反码、补码变换规则?
答:
正数:原码、反码、补码都一样。
负数:原码不变、反码除符号位其它各位取反、补码在反码基础上再加一。
🔺问题:补码与移码对应规则?
答:
补码符号位取反得到移码。
移码符号位取反得到补码。
🔺问题:已知负数原码求补码为取反加一,那么已知负数补码如何求原码?
答:
仍为取反加一。
🔺问题:已知[x]补,如何求[-x]补?
答:
将符号位和数值一同取反再加一。
🔺问题:默写8位机器数对应的无符号数、原码、反码、补码、移码?观察不同码关于0的表示?
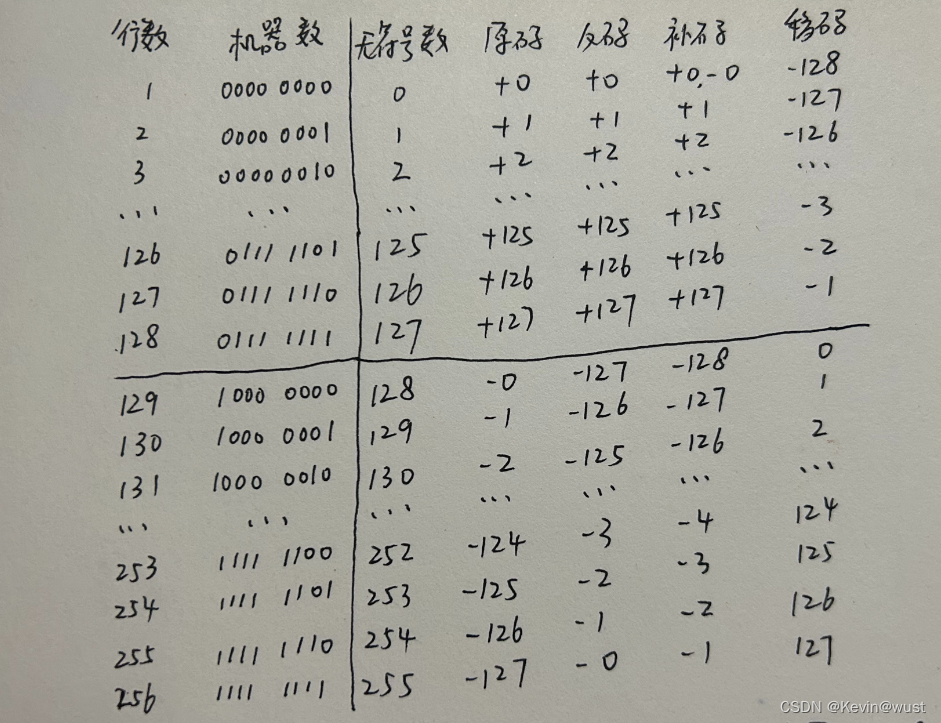
🔺问题:定点整数50,用8位机器数表示,符号位占1位,原码、反码、补码、移码分别为?
答:
原码:00110010
反码:00110010
补码:00110010
移码:10110010
🔺问题:定点整数-100,用8位机器数表示,符号位占1位,原码、反码、补码、移码分别为?
答:
原码:11100100
反码:10011011
补码:10011100
移码:00011100
🔺问题:定点整数用8位机器数表示为00001101,符号位占1位,当它分别表示原码、反码、补码、移码时,对应的真值分别为?
答:
1.原码:00001101
2.反码:00001101
3.补码:00001101
真值都为:13
4.移码:00001101
对应补码:10001101
对应原码:11110011
真值:-115
🔺问题:定点整数用8位机器数表示为10001101,符号位占1位,当它分别表示原码、反码、补码、移码时,对应的真值分别为?
答:
1.原码:10001101
真值:-13
2.反码:10001101
对应原码:11110010
真值:-114
3.补码:10001101
对应原码:11110011
真值:-115
4.移码:10001101
对应补码:00001101
对应原码:00001101
真值:13
🔺问题:补码有哪些优点?
答:
1.零表示唯一。
2.可以将减法转化为加法运算,简化运算部件设计,(只有加法器,没有减法器)。
3.符号位可以和数值位一起参与运算。
4.与真值对应关系简单(错误,对应关系比较复杂)。
这篇关于2.2数据的表示和运算--原码、反码、补码、移码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






