本文主要是介绍tornado调用tensorflow模型对视频进行处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
系统环境:
linux系统:ubuntu16.04
tensorflow:tensorflow-1.13.1-cp35-cp35m-linux_x86_64.whl
python:3.5
OpenCV:3.4.5
1、安装tornado
sudo apt install python3-pip
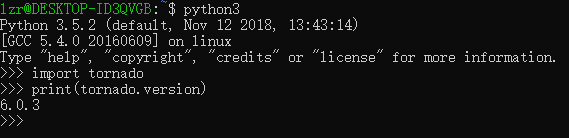
pip3 install tornado查看版本号,安装完成
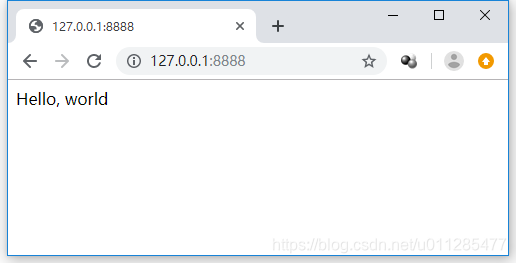
2、运行官方例程 helloworld.py
import tornado.ioloop
import tornado.webclass MainHandler(tornado.web.RequestHandler):def get(self):self.write("Hello, world")def make_app():return tornado.web.Application([(r"/", MainHandler),])if __name__ == "__main__":app = make_app()app.listen(8888)tornado.ioloop.IOLoop.current().start()python3 helloworld.py打开浏览器,输入http://127.0.0.1:8888即可
3、tornado调用tensorflow模型对视频进行处理
服务端代码video_server.py如下:
import tornado.httpserver
import tornado.ioloop
import tornado.options
import tornado.web
import requests
import base64
from PIL import Image
from io import BytesIO
import numpy as np
import cv2
import jsonfrom tornado.options import define, optionsfrom tf_human_pose_pb import runVideotensorflow_model = r"/mnt/c/workspace/code/model.pb"# http://127.0.0.1:8888/video
define("port", default=8888, help="run on the given port", type=int)class MainHandler(tornado.web.RequestHandler):def get(self):self.write("run demo ......")class testHandler(tornado.web.RequestHandler):def get(self):self.write("test!!!")def post(self):## using json jsonbyte = self.request.bodyjsonstr = jsonbyte.decode('utf8')args = json.loads(jsonstr)video_url = args.get('video_url')if video_url is not None:to_return = {}output = runVideo(video_url,tensorflow_model)to_return['result'] = outputself.write(json.dumps(to_return))else:self.write_error(401)returndef main():tornado.options.parse_command_line()application = tornado.web.Application([(r"/", MainHandler), (r"/video",testHandler)])http_server = tornado.httpserver.HTTPServer(application)http_server.listen(options.port,address='0.0.0.0')tornado.ioloop.IOLoop.current().start()if __name__ == "__main__":main()客户端代码http_client.py如下:
import requests
import jsonresponse = requests.post('http://XXX.XXX.XXX.XXX:8888/video', json.dumps({"video_url": "https://XXXXXXXXXX视频下载地址XXXXXXXXXXX"}))
print(response.json())先运行服务端代码,再运行客户端代码,可以在服务端的命令行窗口那看到显示下面这行信息
![]()
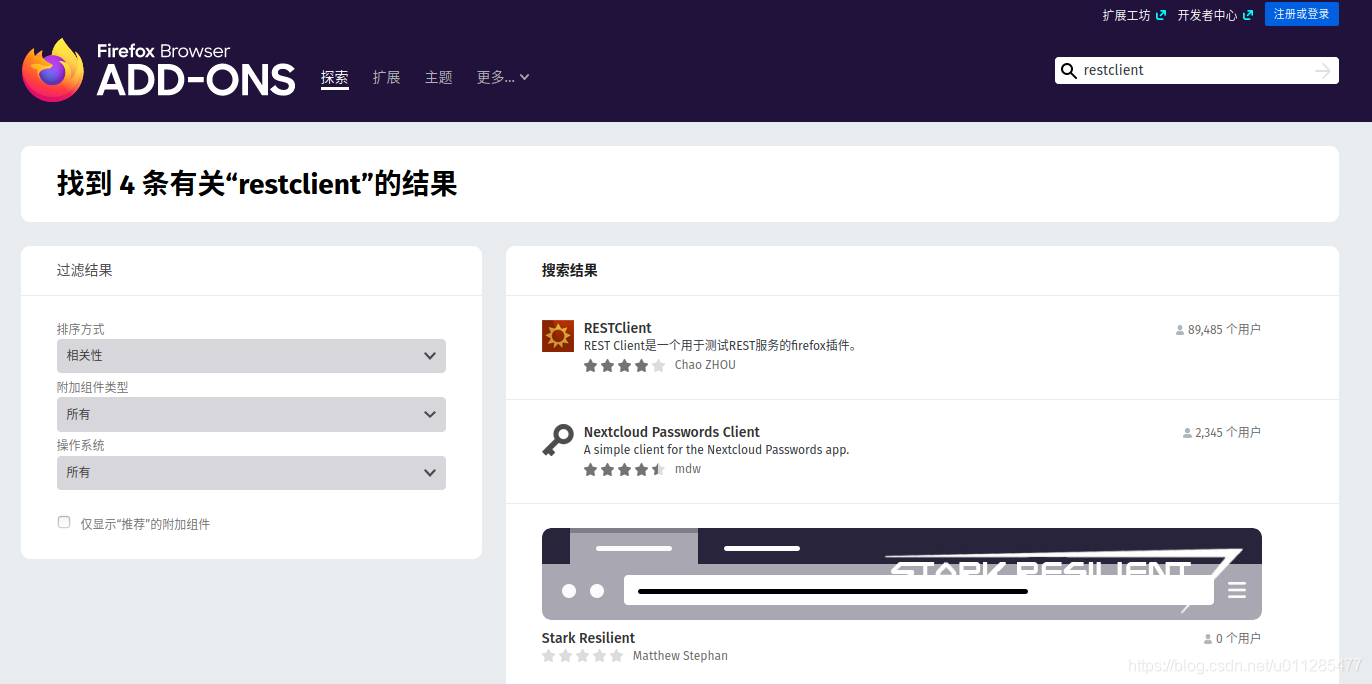
其他的测试工具,可以用Postman或者火狐浏览器的插件RESTClient
在浏览器附加组件选项中搜索RESTClient,如下图
添加启用该组件后就可以愉快地玩耍了
参考链接
tornad官网:https://www.tornadoweb.org/en/stable/
这篇关于tornado调用tensorflow模型对视频进行处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




